CS539 Program 4 -- Due February 28, 2000
In this assignment, you will write the gatherEvidence,
distributeEvidence, and huginPropagation
routines for inference in Junction Trees. Then you will do some
simple experiments with these junction trees.
The file program4.tar is a tar
file containing all of the files necessary for this assignment. Here
is a brief explanation of the important files:
-
ptable.h, ptable.C: These files define
two classes: probabilityTable and
variableSet. A variableSet is a set of
variables, and it supports various set operations. A
probabilityTable is a probability table, and it supports
conformal product (*), conformal quotient
(/), and in-place conformal product (*=), as
well as other operations such as marginalizing (sumOver)
and normalizing (normalize). You should note that a
probabilityTable has a data member called
values, which is a one-dimensional vector containing all
of the probability values in the table. Some fancy bit vector
computations are used by conformal product and conformal quotient to
index into this vector.
-
bayes.h, bayes.C: These files define
the bayesNet data type for a belief network as well as
supporting classes such as a node in a belief network (node), and
a candidate factor (factor), used by the SPI algorithm.
The bayesNet class supports two key methods:
observe (observe that a given variable has a given
value), and query (compute the marginal probability that
a given variable has a given value).
-
jt.h, jt.C: These files define the
jtnode and junctionTree classes. You will
need to study them in detail. In particular, you need to understand
that there are two kinds of jtnodes: cluster nodes and
separator nodes. There is an integer data member
isClusterNode that is 1 if the node is a cluster node
and 0 if not. A junction tree consists of a list of nodes, and the
nodes are doubly-linked together. Each node stores a
probabilityTable, of course.
-
jtdriver.C: This is the main program. It is an
interactive program that reads a file name (as the command line
argument), and reads a belief network from that file. It then
converts the belief network into a junction tree and enters an
interactive loop in which you may observe and query nodes (and also,
re-generate the junction tree from a re-initialized belief network).
The driver program answers each query TWICE. Once using the SPI
algorithm on the belief network and once using the Hugin propagation
algorithm on the junction tree. Every time it prompts the user, it
first displays the junction tree and the belief network. You must
refer to nodes and values by their index numbers.
There are several other programs provided, including several programs
for manipulating single probability tables (e.g., product, quotient,
marginalize, print, etc.). But you should not need these.
I have provided you with a complete junction tree implementation
except for three routines in jt.C. You must write the
bodies of these routines (consult Jensen for details of how these
routines work):
-
probabilityTable * collectEvidence(jtnode * caller). This
routine is really two different routines, depending on whether the
current node (this) is a cluster node or a separator
node.
If it is a cluster node, it should recursively call each of its
neighbors and request that neighbor to return a message
in the form of a probabilityTable *. Each time it receives a
message, it should multiply its own probability table by that message:
(*table) *= (*message). Once it has collected messages
from all of its neighbors (except the caller, of course), then it
should make a copy of its table, marginalize the copy according to the
variables in the caller node, and return the marginalized table to the
caller. The first time it is invoked, caller will be
zero.
If it is a separator node, then it should recursively call its other
neighbor (i.e., not the caller), and when that neighbor returns a
message, it should divide it by its current table, update its current
table to be the (unmodified) message, and return the quotient to its
caller.
-
void distributeEvidence(jtnode * caller, probabilityTable
* message). This routine is also essentially two routines,
depending on whether the node is a cluster node or a separator node.
In this case, the caller passes the current node a
message, and the current node needs to process that
message and then pass it to all of its neighbors (except the caller).
If the current node is a cluster node, then it needs to multiply its
table by the message, and then pass the resulting table to each of its
neighbors.
If the current node is a separator node, it needs to divide the
message by its current table, update its table to be the unmodified
message, and pass the quotient on to its other neighbor.
-
huginPropagation(). This routine simply invokes
collectEvidence and then distributeEvidence
on the current node.
I encourage you to print out trace information to help in debugging.
There is a global variable TRACE that can be set by
passing the -t command line argument (e.g.,
jtdriver -t gas.net). It is helpful (and interesting) to
follow the message passing process.
To debug your code, I have provided four belief networks:
-
gas.net. This is the simple 3-node network that I
used in my lectures.
-
cold.net. This is the 5-node
cold/cat/scratch/sneeze network that Bruce D'Ambrosio used in his
paper. Note, however, that the joint distribution shown in his paper
is not correct.
-
asia.net. This is the network from the Asia
example that I also used in the class. It is taken from the original
paper by Lauritzen and Spiegelhalter that introduced the junction
tree.
-
car.net. This is the most complex network, which
describes the possible causes for the failure of a car to start.
Here is a picture of the belief network:
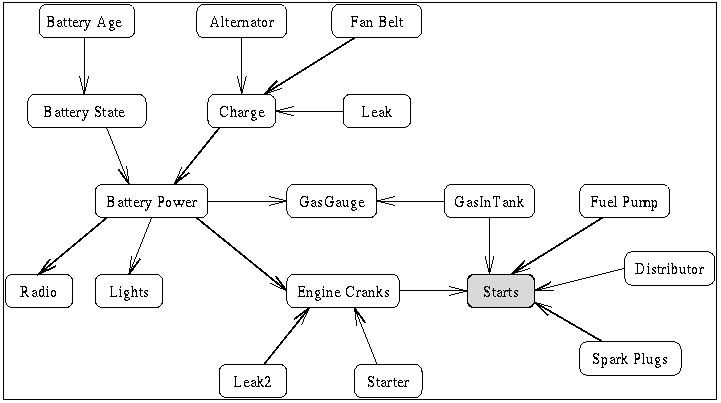
After you have your code working, please do the following:
Your assignment is to compute the probability of each of the following
10 causes after each observation:
SparkPlugs Distributor FuelPump Leak2 Starter
BatteryAge Alternator FanBelt Leak GasInTank
The observations are the following:
- Prior to any observations.
- After observing
Starts is 1. (car won't start)
- After observing
EngineCranks is 1. (engine won't crank)
- After observing
GasGauge is 1. (gas gauge reads empty)
- After observing
Radio is 1. (radio doesn't work)
- After observing
FuelPump is 0. (fuel pump ok)
Note that this kind of "all marginals" query is exactly what the
junction tree algorithm was designed for.
In addition to this computational experiment, please apply (by hand)
the graphical method for constructing a junction tree to the
car.net belief network. Turn in a drawing of the
resulting network.
What to turn in: Turn in a hardcopy of your version of
jt.C, a trace of your program producing the desired
fault probabilities after each observation, and a drawing of your
hand-generated junction tree. Also, please email me your verion of
jt.C.
For extra credit, add instrumentation to both the junction tree and
SPI algorithms to count the number of multiplications that they
perform while answering a query. Then compare the cost of each of
these algorithms for answering the queries for car.net.
Which method is more efficient in terms of number of multiplications?
You may ignore the initial multiplications required to construct the
junction tree.