KI-LEARN: Knowledge-Intensive Learning
The current methodology for applying machine learning can be
depicted as follows:
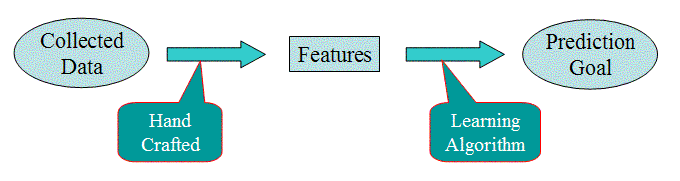
A machine learning researcher confronts a set of data. Typically,
there is a large gap between the raw data and the desired "prediction
target" (i.e., the variable whose value we wish to predict). The ML
researcher bridges this gap by defining a set of features. To do
this, he or she interviews experts in the domain to understand how the
raw data relates to the prediction target. He or she applies ML
expertise to choose a set of features that reflect this domain
knowledge and that narrow the gap. Then one or more machine learning
algorithms are applied to build a classifier or predictor.
This methodology has many problems. It is difficult to apply, because
you need someone with a PhD in machine learning or statistics to
design the features. It is difficult to maintain. If new sources of
data become available, the feature design process must be repeated.
In addition, the rationale behind the set of features is typically not
captured in any formal or informal way.
We propose a new methodology that replaces the hand-crafting of
features by the hand-crafting of contextual knowledge, as shown below:
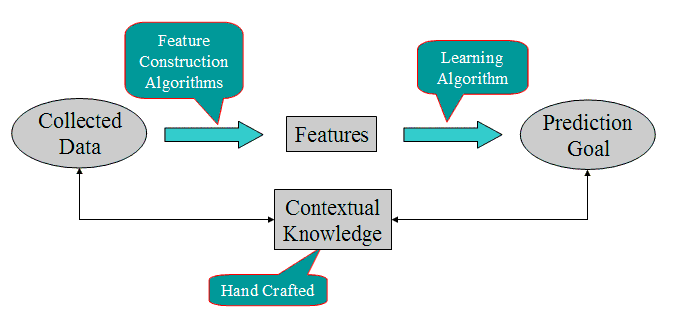
In this methodology, contextual knowledge is captured in the form of
an object-relational model and a collection of qualitative causal
relationships. This information is then automatically transformed to
design the features for a learning system and a set of constraints
that can be incorporated into the learning system. The hope is that
the explicit contextual knowledge will be easier for someone without a
PhD in machine learning to maintain. We also believe that if the
contextual knowledge is made explicit, then it can be incorporated
into the learning algorithms to constraint the parameter values of the
fitted predictive models. This should enable fast learning from small
samples, and thus provide higher-performance systems than can be
obtained with the current methodology.
In our methodology, we envision the following steps which result in a
probabilistic relational model (PRM) that can be fit to the available
data.
- Build object-relational model of the domain. This model
describes the objects, their properties, and their relationships. It
can be annotated to indicate which properties are observed and which
are the targets to be predicted.
- Indicate qualitative causal relationships. The
object-relational model is then augmented with qualitative causal
relationships. We are currently exploring extensions of Ken Forbus'
Qualitative Process Theory as our representation language.
- Introduce aggregations. If a variable has a
large and variable number of input causal links, then those links must
be aggregated to provide a compact parameterization of a predictive
model. By analyzing the kinds of qualitative relationships, we
believe it will be possible to automatically choose good
aggregations.
- Parameterize the Probabilistic Relational Model. Each
property in the object-relational model can be converted to a random
variable in a probabilistic relational model. The conditional
probability distribution (CPD) of each such variable must be
parameterized in a way that is compact and that reflects constraints
arising from the qualitative relationships (such as monotonicity,
saturation, etc.).
- Unroll the Probabilistic Relational Model and fit to the
data. Our plan is to use existing Bayesian network toolkits to
fit the model to the data, such as Intel's Probabilistic Networks
Library PNL.
We are developing and testing this methodology in three application
domains: (a) TaskTracer (the intelligent desktop), (b) predicting the
spread of West Nile Virus, and (c) predicting grasshopper populations
in Eastern Oregon.
This project is in the early stages, so we have no technical
results to report at this time.
Financial Support
This project has been funded by the following grants and contracts:
- NSF SGER Grant IIS 0335525: Exploiting Contextual Knowledge to
Design Input Representations for Machine Learning
- DARPA Contract HR0011-04-1-0005: KI-LEARN: Knowledge-Intensive
Learning Methods for Knowledge-Rich/Data-Poor Domains
The views expressed on this page are those of the principal
investigators and do not necessarily reflect the views of the National
Science Foundation or the Defense Advanced Research Projects Agency.