An example might be the association of a name with a grade record. A vector is one form of association, maintaining an integer key associated with a value.
But what if the key is not integer (such as a name), or if it is integer but from too large a range (such as a Social Security Number).
The hash table is good when we can afford to allocate a fixed
amount of storage to the association
intuition:
Example: Let a = 0, b = 1, c = 2, etc. Select first two letters of name and add together.
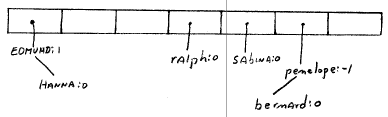
penelope 15 + 4 = 19 sabina 18 + 0 = 18 bernard 1 + 4 = 5 edmund 4 + 3 = 7 ralph 17 + 0 = 17
For example, set of six names, select third letter and take remainder after dividing by six.
name value remainder Al f red 5 5 Al e x 4 4 Al i ce 8 2 Am y 24 0 An d y 3 3 An n e 13 1
penelope 15 + 4 = 19 sabina 18 + 0 = 18 bernard 1 + 4 = 5 edmund 4 + 3 = 7 ralph 17 + 0 = 17 hanna 7 + 0 = 7Solution - instead of elements, make a vector of collections (called buckets). Elements that collide are then simply maintained in the same collection. Problem of collisions goes away (almost).
0 {edmund, hanna}
1 {}
2 {}
3 {ralph}
4 {sabina}
5 {bernard, penelope}
6 {}
class TableEntry {
int key;
infoType info;
}
class InfoType {
Object dataField1;
Object dataField2;
}
class HashTable {
public final statuc int emptyKey = 0;
int M;
int count;
TableEntry [] T;
HashTable(int tableSize) {
M = tableSize;
count = 0;
T = new TableEntry[M];
for (init i = 0; i < M; i++) {
T[i] = new TableEntry();
T[i],key = emptyKey;
}
}
void HashInsert(KeyType k, InfoType I) {
int i;
int probeDecrement;
i = h(K);
probeDecrement = p(K);
while (T[i].key != emptyKey) {
i -= probeDecrement;
if (i < 0) i += M;
}
T[i].key = k;
T[i].info = I;
count++;
}
int hashSearch(KeyType K) {
int i;
int probeDecrement;
KeyType probeKey;
i = h(K);
probeDecrement = p(K);
probeKey = T[i].key;
while ((K != probeKey) && (probeKey != emptyKey)) {
i -= probeDecrement;
if (i < 0) i+=M;
probeKey = T[i].key;
}
if (probeKey == emptyKey) return -1;
else return i;
}
}
Note that we don't specify a specific hash function, but that it will have
to be included in the class.
Here is one:
public final static int h(String key, int tbaleSize) {
int hashVal = 0;
for (int i = 0; i < key.length(); i++) {
hashVal = 37 * hashVal + key.charAt(i);
hashVal %= tableSize;
if (hashVal < 0) hashVal += tableSize;
return hashVal;
}
There are many variant "open-addressing" schemes for resolving conflicts.
Linear probing, double hashing, and a variety of more complex schemes.
However, its easier to just keep table size larger than number of entries.
Performance can get very bad as tables fill up, but one simple solution
is to use "separate chaining".
A generalization of simple chaining is the use of buckets. The idea is simple: each has table entry is itself a collection! What kind? Any kind you like that supports insert, remove, and find. For example, linked list, or better, AVL tree.
Let's look at our initial dataset that way
Best case, elements are uniformly spread over all buckets. Time is 0(log(n/m)).
If the number of buckets is proportional to the number of elements, latter is roughly a constant!
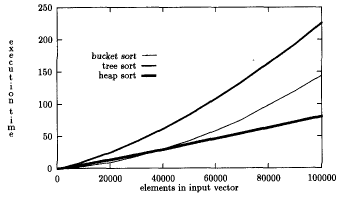
IF we can find a hash function that divides elements so that all values in first bucket are smaller than all elements in second bucket, and all elements in second bucket are smaller than elements in third bucket, and so on - then simply add values into hash table built on top of ordered lists or AVL trees, then pull them out in order. Under the right circumstances can be the fastest of sorting algorithms. Hard part is finding the right hash function. Here is an example. Values selected randomly between 0 and 16000.
Hash function is simply shift left by 4. 1000 buckets.
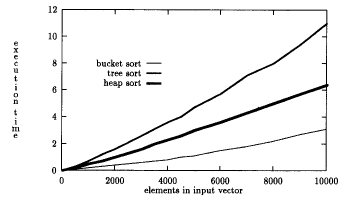
But, as buckets get full, advantage is lost. Why? (Hint - how are we
handling collisions?)
name value remainder Al f red 5 5 Al e x 4 4 Al i ce 8 2 Am y 24 0 An d y 3 3 An n e 13 1
penelope 15 + 4 = 19 sabina 18 + 0 = 18 bernard 1 + 4 = 5 edmund 4 + 3 = 7 ralph 17 + 0 = 17 hanna 7 + 0 = 7
Can mitigate this problem somewhat by shifting the result of the first mapping by some amount before adding the second.
penelope 15 << 1 + 4 = 34 sabina 18 << 1 + 0 = 36 bernard 1 << I + 4 = 6 edmund 4 << 1 + 3 = 11 ralph 17 << 1 + 0 = 34 hanna 7 << 1 + 0 = 14 adam 0 << 1 + 3 = 3 daphne 3 << I + 0 = 6
When does this happen? "unique" strings is one example: there are packages available which which ensure each distinct string exists only once in memory, so you can test for equality just by testing pointer equality.
But note: can't iterate in order over elements. Find next in order is O(n).