So far we have been using the recursion tree method to analyze the complexities of divide-n-conquer algorithms. But you likely have heard of the other widely used method, the Master Theorem, which was popularized (as the “Master method”) by the CLRS textbook. With this method, you don’t need to draw the recursion trees; instead you only need to decide which of the three cases this recursion falls into, and look up the answer. Therefore you can think of it as a mnenomic or “cookbook” method.
Our objective in this section is to give you a quick and gentle introduction to this powerful method by deriving it from the recursion tree method, so that you can understand the geometric intuition behind this theorem rather than memorize the details. Therefore the treatment of math here is rather informal (missing a lot of details). For a much more rigorous treatment, please refer to CLRS or Wikipedia.
For a general divide-n-conquer algorithm, we divide a problem of size \(n\) evenly into \(b\) non-overlapping subproblems (each with size \(n/b\)), and conquer \(a\) of them. Together with the non-recursive work (i.e., divide + combine) of \(f(n)\), we can write the recurrence as
\[T(n) = aT(n/b) + f(n)\]
For example, in mergesort, \(a=b=2\) (conquer both children) and \(f(n)=n\), while in binary search, \(a=1\), \(b=2\) (conquer one of the two children), and \(f(n)=1\). Note that:
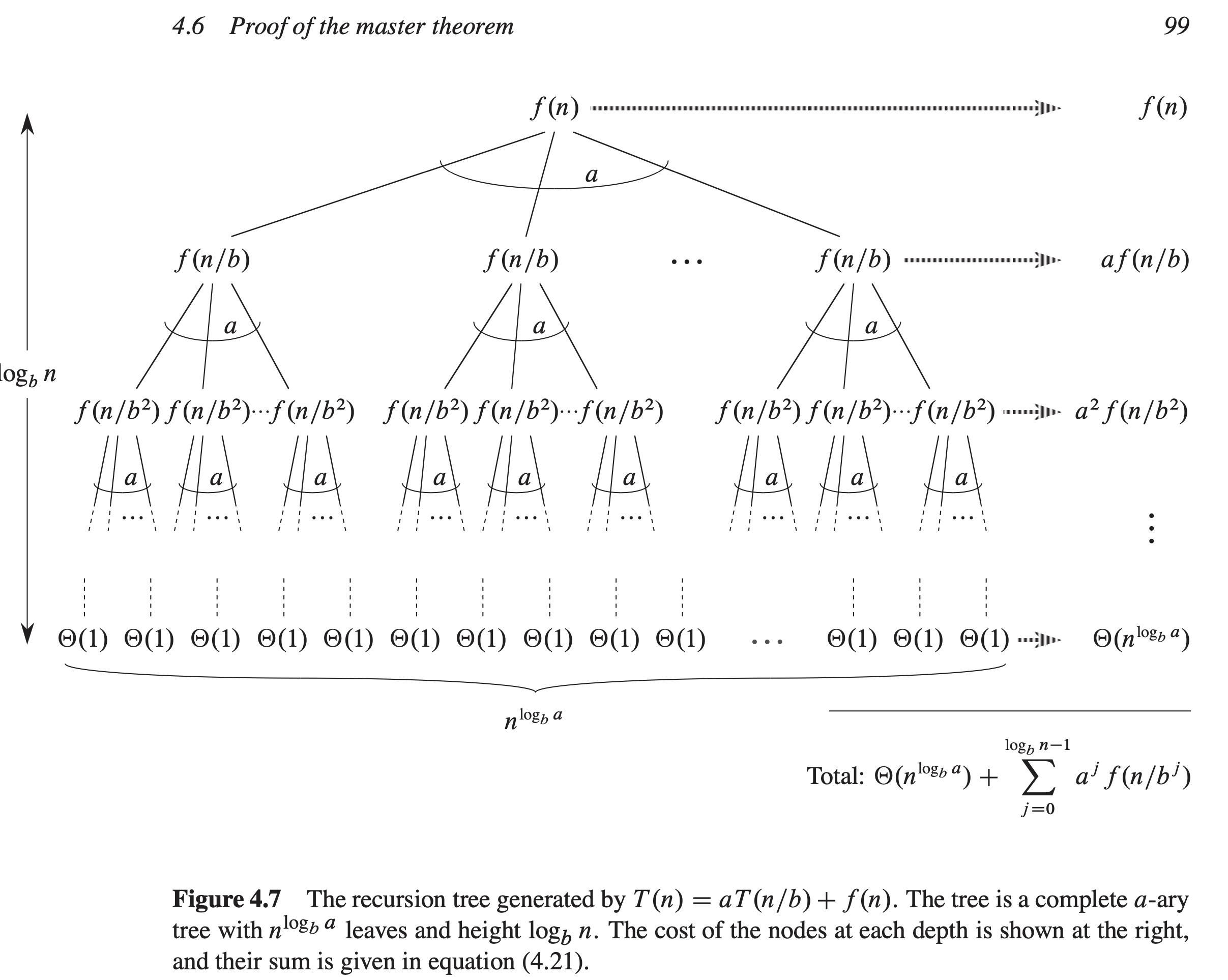
Recall that the key to the recursion tree analysis is the amount of work per level (see below a recursion tree from CLRS, Fig. 4.7):
Now we can ask the key question that divides the analysis into three cases: does the amount of work per level grows or shrinks as you get deeper? Or (more or less) equivalently, which one dominates the other, the root work \(f(n)\) or the leaves work \(n^{\log_b a}\)?
Here are the pictures (all you need to remember are these geometric intuitions!):
* f(n)
* * a f(n/b) > f(n)
* * * * a^2 f(n/b^2) >> f(n)
... ...
************************** a^h f(1) >>>>>> f(n) ******************* f(n)
********* ********* a f(n/b) = f(n)
**** **** **** **** a^2 f(n/b^2) = f(n)
... ...
******************* a^h f(1) = f(n)Another typical example: binary search (\(a=1, b=2, f(n)=1\)):
* f(n) = 1
* a f(n/b) = 1
... ...
* a^h f(1) = 1************************** f(n)
************* a fn/b) < f(n)
******* a^2 f(n/b^2) << f(n)
... ...
* a^h f(1) <<<<<< f(n)More formally, where do we draw the boundary? Well, we either compare the root \(f(n)\) with the leaves \(n^{\log_b a}\) to see which one is smaller, or compare the first two levels \(f(n)\) and \(af(n/b)\) to see which one grows faster. Either way, you can get the same threshold \(n^{\log_b a}\) as the critical polynomial that demarcates the boundaries of the three cases. A technical detail is that you need to leave a small polynomial margin of \(n^\epsilon\) between the three cases (so that the boundaries are more widely marked):
Examples:
| algorithm | recurrence |
|---|---|
| balanced binary tree traversal | \(T(n)=2T(n/2) + 1 = \Theta(n)\) |
| heapify | \(T(n) = 2T(n/2) + \log n = \Theta(n)\) |
Note: for heapify, \(f(n)=\log n\) grows slower than any polynomial \(n^c\) with \(c>0\), so it definitely is dominated by \(n^{\log_b a} = n\).
Examples:
| algorithm | recurrence |
|---|---|
| mergesort & quicksort best-case | \(T(n)=2T(n/2) + n = \Theta(n\log n)\) |
| binary search & search in balanced BST | \(T(n) = T(n/2) + 1 = \Theta(\log n)\) |
| \(k\)-way mergesort | \(T(n)=kT(n/k) + n\log_k = \Theta(n\log_k \times \log_k n) = \Theta(n\log n)\) |
Note: \(k\)-way mergesort should belong to this case although \(k\) is a variable here. We need to (slightly) genearalize the scope of this theorem by allowing \(a\) and \(b\) to be variables that do not change with height, and we need to use my form of \(T(n)=\Theta(f(n)\log_b n)\) rather than the textbook result of \(T(n)=\Theta(f(n)\log n)\) because the former works even when \(b\) is a variable that doesn’t change with height. But this is a rather minor point.
Examples:
| algorithm | recurrence |
|---|---|
| quickselect, best-case | \(T(n)=T(n/2) + n = \Theta(n)\) |
| bad mergesort (HW2) | \(T(n) = 2T(n/2) + n^2 = \Theta(n^2)\) |
Note: in most divide-n-conquer instances, \(b=2\) and \(a\in{1,2}\), so the critical threshold is \(n^0=1\) or \(n^1\). Any \(f(n)\) that grows faster than \(n\) falls into this root-heavy case, i.e., \(T(n)=2T(n/2) + n^2\log n = \Theta(n^2\log n)\).
The biggest drawback of Master Theorem is that it can not handle non-even (esp. worst-case) divisions such as \(T(n)=T(n-1) + f(n)\) which are very common in datastructures (e.g., quicksort/quickselect worst-case). Those cases can still be solved by the recursion tree method, which is more flexible (and thus the default method). Here I summarize the 3x3 combinations of
the three most common divisions:
and the three most common \(f(n)\)’s:
These combinations cover the vast majority of the most commonly used divide-n-conquer instances in algorithms and datastructures, so it’s worthwhile to list all of them:
| \(...1\) | \(...\log n\) | \(...n\) | |
|---|---|---|---|
| unary \(T(n) = T(n/2) + ...\) | case 2: \(\Theta(\log n)\) | case 2: \(\Theta((\log n)^2)\) | case 3: \(\Theta (n)\) |
| binary search; search in balanced BST | NOT COVERED | quickselect best-case | |
| binary \(T(n) = 2T(n/2) + ...\) | case 1: \(\Theta(n)\) | case 1: \(\Theta(n)\) | case 2: \(\Theta (n\log n)\) |
| balanced binary tree traversal | heapify | mergesort; quicksort best-case | |
| unary \(T(n) = T(n\!-\!1) + ...\) | \(\Theta(n)\) | \(\Theta(n \log n)\) | \(\Theta (n^2)\) |
| linear-chain tree traversal; search in linear-chain BST | \(n\) heappushes | quicksort/quickselect worst-case |
The Master Theorem was published by Bentley, Haken, and Saxe in 1980.