Before we delve into the details of AI, it is helpful to understand,
in a big picture, the history of AI.
The Prehistory of AI
Various precursors of AI concepts were proposed since antiquity, well
before the birth of modern computers in the 1940s, but the most relevant
developments that led to the birth of AI are undoubtedly
formal reasoning, mathematical logic, and model of computation
The study of mathematical logic aims to “formalize” and “mechanize”
all mathematics and formal reasoning. In the 19th century Boole (from
whom we have “boolean”) and Frege laid down foundations of mathematical
logic, which made AI seem plausible.
The Turing
machine by Alan
Turing and Lambda calculus
by Alonzo
Church are the first two models of computation. Interestingly, after
publishing the Turing machine, Turing later became a PhD student under
Church, and they proved the equivalence between the two formalisms.
Turing was also one of the founding fathers of AI; he proposed the
famous Turing Test (see below). To celebrate his foundational
contributions to computer science, the ACM Turing Award
was named after him; it is the highest award in computer science, and is
often called “the Nobel Prize in computing”.
Alan Turing
modern computers (during World War II)
The 1945 completion of ENIAC at the University
of Pennsylvania was considered the single most influential event in the
birth of modern computers. ENIAC was based on the theoretical foundation
laid by Alan Turing (see above) and developed by John von Neumann (hence
the von
Neumann architecture).
ENIAC computer
The Birth of AI (1941–1956)
Shortly after WWII, many important developments together led to the
birth of AI as a scientific field.
In addition to being a founding father of computing, Alan Turing was
also a founding father of AI. In 1950 he published another landmark
paper speculating the possibility of a “thinking machine”. Since
“thinking” is hard to define, he devised a thought experiment, now known
as the famous “Turing Test”, to assess a machine’s ability to exhibit
intelligent behavior indistinguishable from that of a human. In such a
test, a human interrogator engages in written conversation with two
unseen participants—one human and one machine. If the interrogator
cannot reliably distinguish between the human and the machine,
the machine is considered to have passed the test. The test serves as a
benchmark for artificial intelligence, with the goal of determining if a
machine can “think” by successfully imitating human communication.
Turing argued that a “thinking machine” in this simplified definition
was at least plausible. The Turing Test was also the first serious
proposal in the philosophy of artificial intelligence.
Throughout the history of AI, the Turing Test was long considered a
far-off goal and one of the holy grails of AI. This all changed at the
arrival of large language models (LLMs) such as ChatGPT where modern
LLMs such as GPT-4 have been found to pass the Turing Test in specific
settings, according to a study
by Stanford.
Mathematical studies on artificial neurons started in 1940s and in
1951 Marvin Minsky, one of the founding fathers of AI, built the first
neural network machine. Neural networks went on to become the
foundations of modern deep learning (which is based on deep, or
multilayered, neural networks) and are at the very center of the current
AI revolution. This also led to the birth of “connectionism” (connected
neurons), one of the two major paradigms of AI, with the other being
“symbolism” discussed below.
The early digital computers were mostly made for numerical
computations (due to military needs), but some scientists believed that
they could also be used for symbolic manipulation, which many belived to
be the essence of human thought. This gives birth to a new paradigm in
AI called symbolism (also known as “symbolic AI”, “logic-based
AI”, or “rule-based AI”), which dominated AI research and funding until
the mid-1990s.
In 1955, two founders of AI, Allen Newell and Herbert Simon, created
the “Logical Theorist” which would prove 38 of the first 52 theorems in
a famous math textbook, including new and more elegant proofs for some
of them.
The definitive event that marks the formal inception of AI is the
famous Dartmouth workshop of 1956, organized by Marvin Minsky and
John
McCarthy. Both of them were considered founding fathers of AI and
would later won the Turing Award. The workshop was supported by Claude Shannon
of IBM (the inventor of information theory). Other notable participants
inclue Allen
Newell and Herbert Simon,
both of whom also won the Turing Award (Simon also won the Nobel Prize
(in Economics), the first person to receive both). Since the original AI
ideas came from many different fields (see above), in the early 1950s,
there were various names for this emerging field of “thinking machines”.
In 1955, John McCarthy, a young Assistant Professor at the Dartmouth
College decided to organize a group to clarify ideas in this new field.
It was at this workshop that his proposed name ‘Artificial Intelligence’
was accepted by the participants, which quickly became the standard
name.
First AI Boom (1956-1974)
The next 20 years or so since the Dartmouth Workshop saw a big boom
in AI, known as the first AI boom.
AI Search
The first major research area is general-purpose AI search, which can
be used in many different domains such as game AI (e.g., chess playing)
and solving math problems. To achieve some goal (like winning a game or
proving a theorem), they proceeded step by step towards it (by making a
move or a deduction) as if searching through a maze, backtracking
whenever they reached a dead end. The principal difficulty was that, for
many problems, the number of possible paths through the “maze” was
astronomical (a situation known as a “combinatorial explosion”).
Researchers would reduce the search space by using heuristics that would
eliminate paths that were unlikely to lead to a solution.
Natural Language and Early
Chatbots
An important goal of AI, from the very beginning, has always been to
understand natural languages like English, and even translate between
languages.
Notable achievements include:
Daniel Bobrow’s program STUDENT, which could solve high school
algebra word problems
Joseph Weizenbaum’s ELIZA chatbot, the world’s first chatbot, which
could carry out conversations that were so realistic that users
occasionally were fooled into thinking they were communicating with a
human being and not a computer program. It was done with grammar
rules.
Terry Winograd’s SHRDLU, which could communicate in ordinary English
sentences about the micro-world, plan operations and execute them
Frank
Rosenblatt introduced the perceptron in 1957, a single-layer neural
network that can learn to make predictions. This remarkable invention
was the prototype of the more complex neural networks that are still
used today.
The Mark 1 Perceptron
The perceptron is the most important work in the early history of
connectionism, during a period when symbolism was more popular. The
philosophical debate between these two paradigms has been one of the
most fundamental issues in the history AI (and cognitive science). This
debate centers on whether intelligence is best explained as emerging
from distributed neural-like networks that learn patterns
(connectionism) or from structured, rule-based symbolic representations
that encode logic and meaning (symbolism), or in other words, which one
comes first, “learning” or “representation”. While symbolisms dominated
the 1980s and early 1990s, since late 1990s or so, connectionism has
been overwhelmingly more popular, especially in the current AI boom.
Although AI was considered quite promising in the 1960s, several
events led to the first AI winter which saw significantly reduced
government funding, research activities, and public interest in AI:
1966: failure of machine translation; it turns out the AI technology
at the time was far from powerful enough to solve this very hard
problem.
1969: criticism of perceptron (single-layer neural networks); Minsky
and Papert wrote a famous book entitled Perceptron which showed it was
impossible for single-layer neural networks to learn an XOR function. It
is often incorrectly believed that they also conjectured that a similar
result would hold for a multi-layer perceptron network. However, this is
not true, as both Minsky and Papert already knew that multi-layer
perceptrons were capable of producing an XOR function. Nevertheless, the
often-miscited Minsky and Papert text caused a significant decline in
interest and funding of neural network research. It took ten more years
until neural network research experienced a resurgence in the 1980s
1971-75: DARPA’s frustration with the Speech Understanding Research
program at Carnegie Mellon University
1973: The Lighthill Report in the UK gave a very pessimistic view of
AI, which resulted in large decrease in AI research in the UK
1973-74: DARPA cut funding support to AI research in USA
Second AI Boom (1980s)
By early 1980s, AI had recovered from its first winter. In this
period, most of AI research is symbolic, focusing on knowledge
representation and logical reasoning. In particular, “expert systems”
become popular and widely adopted in the industry. Government funding
soared, especially in Japan and US.
Besides the mainstream symbolic AI, other ideas were also explored,
including neural network revival, probablistic reasoning, and
reinforcement learning.
Second
AI Winter (late 1980s to early-mid 1990s) and Paradigm Shift
(1990s-)
However, commercial interest in AI quickly fell by late 1980s,
because rule-based AI systems including expert systems were found to be
rather limited: they do not scale, are unable to adapt, and are too
costly to maintain. By 1991, Japan’s overly ambitious Fifth Generation
Computer project (which started in 1981) had largely failed. The US
government funding also saw large cuts, as DARPA had decided that AI was
“not the next wave”.
Paradigm
Shift: From Symbolic to Connectionist (1990s-)
In response to this Second AI Winter, starting from the early 1990s,
there has been a paradigm shift from symbolism
(rule-based/knowledge-based AI) to connectionism (machine
learning AI). This is because for most application domains,
rule-based systems are unable to scale, unable to adapt to new
scenarios, and are too costly (i.e., labor-intensive) to build and
maintain. Let’s take machine translation (MT) as a concrete example.
Since the 1950s, MT has always been one of the focus areas of AI and was
(due to its complexity) considered a holy grail of AI. The early MT
systems, from 1950s till 1990s, were rule-based, where bilingual experts
need to write translation rules, say, for English-to-Chinese
translation. Apparently, we have the following observations:
these rules are very costly to write
only bilingual experts (often linguists) can write them
we need a huge number of such rules to cover all aspects of
English-to-Chinese translation
when multiple rules can apply in the same context, it is hard to
specify which rules should have higher precedence
when new words, phrases, or constructions emerge in the source
language (which happen all the time), we need to constantly add new
rules and adjust precedences
if we need a new translation direction, say, English-to-French, we
need to repeat this whole process again to write a completely different
set of rules
These limitations motivate researchers to consider the other
alternative, i.e., learning-based translation (also known as statistical
MT). Starting from 1990, statistcal MT has gradually become increasingly
popular, and by late 1990s, the dominate approach. Instead of hiring
linguists to write the translation rules, we try to extract them from
data by machine learning, without any prior knowledge of the two
languages. Such data is called “parallel text”, for example, a set of
English-Chinese sentence pairs. Such data is abundant, say, in the
United Nations and European Commission, and in multilingual user
manuals. If we see the English word “apple” and the Chinese word
“pingguo” tend to co-occur in many sentence pairs, we can conjecture
that they might be translations of each other.
In the 1990s, machine learning approaches (also known as statistical
learning or data-driven methods) become increasingly popular,
overshadowing classical symbolic approaches. More and larger datasets
became increasingly available, such as the Penn Treebank for
natural language and the MNIST database
for computer vision. Various machine learning models were proposed and
well studied, including support
vector machines (SVMs), logistic
regression, decision trees,
and k-nearest
neighbors (k-NN). This development paved the way for the deep
learning revolution.
In the 1990s and 2000s, researchers also combined symbolic and
machine learning approaches, which resulted in structured
prediction that was widely applicable to natural language
processing, computer vision, and computational biology. During this
period, IBM made two landmark breakthroughs in AI: (a) IBM Deep
Blue (chess playing AI) which beat the World Champion Kasparov, and
(b) IBM Watson
for question-answering in the Jeopardy! show.
Interestingly, (a) combined reinforcement learning, neural networks, and
AI search, but (b) used mostly classical symbolic methods with very
little machine learning.
Deep Learning Era
(the Third AI Boom) (2012-)
Deep learning is a subfield of machine learning which has dominated
AI since 2012.
Pre-2012 History
The concept of deep learning evolved from multi-layered (thus “deep”)
neural networks, which in turn evolved from single-layered (“shallow”)
neural networks such as the perceptron. The term “deep learning” was
already proposed by mid-1980s, when many scientists studied multilayer
perceptron, backpropagation training, convolutional neural networks
(CNNs), and recurrent neural networks (RNNs), all of which would be
central in the later deep learning revolution. However, computers were
far too slow at the time, and training data was scarce, so deep learning
did not take off.
In the 1990s and early 2000s, neural network become a rather
unpopular topic in AI. Very few researchers continued to work on it.
Probably the most notable achievement during this relatively quiet
period was the Long
Short-Term Memory (LSTM) by Sepp Hochreiter
and his advisor Jürgen
Schmidhuber, a variant of RNN specifically designed to learn and
remember information from long sequences of data, addressing the
vanishing gradient problem that plagues standard RNNs. LSTM would become
foundational in the deep learning revolution.
In 2006, Geoff Hinton
(who studied early forms of deep learning in the 1980s) published deep
belief networks (DBNs), which (although irrelevant today) led to the
revival of deep learning. Due to his central position in the history of
deep learning, he is now known as the “Godfather of AI”.
The landmark event that brought deep learning to the spotlight was
the 2012 ImageNet
Competition (organized by Fei-Fei Li). Each
year, many teams compete in this image classification test, trying to
classify any image into one of the many (~1,000) classes. Many of these
fine-grained classes are very hard even for humans, such as different
breeds of dogs. In 2012, the “AlexNet” team from U. of Toronto, made of
two PhD students Alex Krizhevsky
(thus “AlexNet”) and Ilya Sutskever
along with their advisor Geoff Hinton, surprised the whole computer
vision field by winning this contest by a huge margin, with only half of
the error rate of the second-best team. Ilya would later become Chief
Scientist of OpenAI and the main person behind GPTs (which led to
ChatGPT).
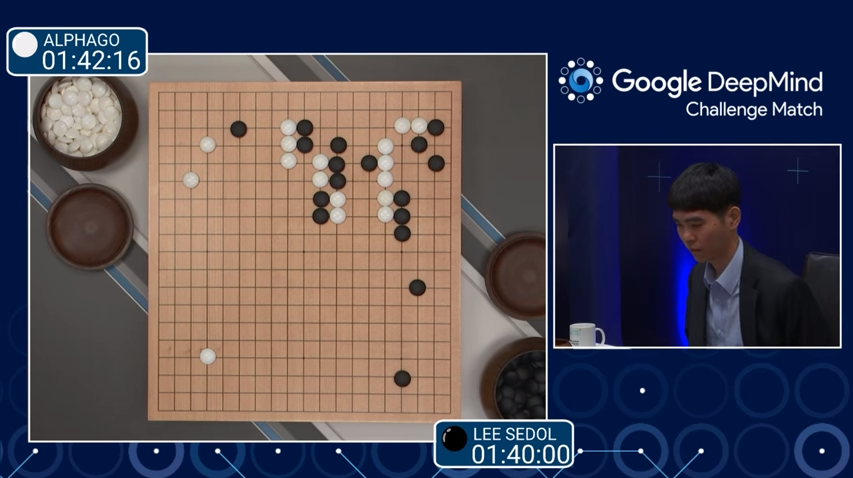
The next major landmark that greatly boosted public interest in AI
was AlphaGo (2015-2016), which was an AI Go-playing system
that beat Lee
Se-dol, the legendary Go player who dominated the game for many
years. This achievement by Google DeepMind was truly remarkable and very
shocking because the search space of Go is orders of magnitude larger
than that of Chess. Go has a 19x19 board where Chess only 8x8. So
although IBM Deep Blue beat the best human player in the mid-1990s,
computer Go was still considered (as of ~2014) far beyond AI. AlphaGo
thus shocked the whole world and changed the public view of AI.
Technically speaking, AlphaGo combines deep reinforcement learning with
classical AI search.
The foundation of the current AI boom is a breakthrough paper from
Google in 2017 which proposed the “Transformer” architecture. This is an
encoder-decoder architecture originally designed for machine translation
(e.g., from English to Chinese). However, just one year later, OpenAI
proposed a variant of Transformer called GPT
(generative pretrained transformer) which is decoder-only, so that
it can generate text (word by word) based on a prompt. This marks the
birth of large language models (LLMs). The key motivation behind GPT and
LLMs is that if you can predict the next word with high accuracy, you
can must have a very good understanding of the world’s knowledge and can
therefore perform tasks that require intelligence, such as reasoning. In
late 2022, OpenAI released ChatGPT (based on GPT
3.5) which shocked the entire world. It became the fastest consumer app
to hit 100 million users in two months.
2018 Turing Award and 2024
Nobel Prizes
The 2018 Turing award was given to three deep learning pioneers,
Geoff Hinton, Yann
LeCun, and Yoshua Bengio.
Among them, Hinton was a mentor/advisor to the other two, and thus the
central figure.
The 2024 Nobel Prize in Physics was awarded to John Hopfield and
Geoff Hinton, for physics-inspired machine learning. Both of them were
early pioneers of neural networks in the early 1980s: Hopfield proposed
the Hopfield
network and Hinton proposed the Boltzmann
machine with Hopfield’s student Terry Sejnowski
(another key pioneer of deep learning who deserves the Nobel Prize
and/or Turing Award). Hinton became the second person in history to win
both a Turing Award and a Nobel Prize, after Herbert Simon.
The 2024 Nobel Prize in Chemistry was also awarded to protein folding
(John Jumper and Demis Hassabis of Google DeepMind, for AlphaFold) and
protein design (David Baker), both by deep learning methods. Hassabis
was the founder of DeepMind, who co-led AlphaFold with Jumper and co-led
AlphaGo with David Silver. Baker is a biochemist by training but heavily
used deep learning in recent work.