There are many limitations to modern AI technologies, including large deep learning systems as well as simpler machine learning systems. We’ll discuss a few of them in this exploration, but understand that there are many other nuanced limitations to AI that are being actively studied and are beyond the scope of this course.
While the methods used to train deep learning models are well understood, once those models are trained, the exact internal processes by which they make specific predictions can be very difficult to dissect. This is referred to as the black box problem (i.e., once trained, these models are “black boxes”—difficult to peer inside and understand).
For example, a parameter in a large language model is an extremely primitive thing: just a single number that’s usually multiplied by or added to another number. Yet, if a trillion of them are arranged together and carefully tuned to very particular values, you somehow end up with a model that’s capable of telling jokes, captioning images, and so on. Analyzing those trillion tuned parameter values to determine why and how the model makes certain predictions in certain cases is not trivial.
This is a major limitation, not least because it makes it hard to understand the reasoning for the other limitations of these systems. Explainable AI (XAI) is a large subfield of active AI research, and it aims to address this problem. Many interesting results and useful techniques have come out of XAI research, but these models are still far from fully explainable.
You may have heard of the term “AI hallucination”. Loosely, a hallucination is any incorrect or misleading information generated by a generative AI system that’s provided to the user as if it’s correct. Examples include a chatbot embedding citations of non-existent court cases in a generated legal motion (e.g., as in Mata v. Avianca), an image generator embedding an image of an object in a nonfictional scene that shouldn’t be there, and, more generally, an AI system simply answering a question incorrectly.
Hallucinations are a serious limitation of many modern generative AI systems. Of course, people “hallucinate” in the same way. After all, we’re not always right. However, many AI systems currently have higher hallucination rates than a relevant human expert might have. For example, Skalidis et al. published a study wherein they had ChatGPT take the European Exam in Core Cardiology (EECC). ChatGPT produced correct answers for 58.8% of multiple-choice questions aggregated across all question sources. This means that its error rate, or “hallucination rate”, was about 40%. The threshold for passing the exam varies for each exam season depending on overall exam performance, but it’s typically around an accuracy of 60% on the multiple-choice questions. This means that, depending on the exam season and the nature of the questions, it’s possible that ChatGPT could pass the EECC.
That’s quite the success story, but consider that 60% accuracy is the threshold for passing. The average scores of all human experts who have passed the exam is surely much higher than that (not to mention the would-be scores of seasoned experts who have been in the field for years since they originally took the exam).
So, why do AI systems hallucinate? Well, there are many known reasons, and likely some unknown ones. But one reason that’s fairly well understood is the set of inductive biases that result from autoregression. Recall that autoregression means to predict the next value in an output sequence given everything leading up to it (e.g., predict the next token in a partially complete sentence, as many chatbots do). An inductive bias is an assumption that an AI system uses to predict outputs for unseen inputs, and autoregression creates inductive biases that are good for certain tasks but bad for others.
Particularly, because autoregressive models predict tokens in a left-to-right order one at a time, they inherently assume that the context of the previous tokens is sufficient for predicting the rest of the tokens. This is detrimental when generating responses that need to match some holistic pattern.
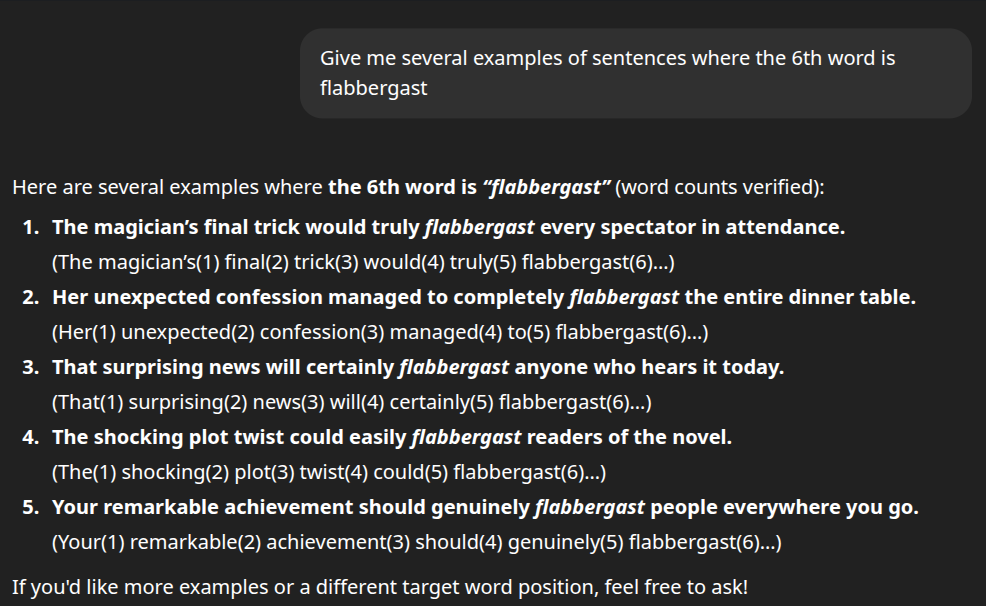
For example, if I ask you to produce a sentence where the 6th word is “flabbergast”, you might start producing a sentence, and only when you get to the 4th or 5th word do you realize that there’s no way to make the 6th word “flabbergast” while still completing the sentence in a grammatically correct way. In such a case, you’d need to back up and adjust the wording of the earlier parts of the sentence. Autoregression does not support this sort of “back up and retry” strategy; chatbots simply generate one token at a time, left-to-right, until they reach the end of the output sequence. (Chain-of-thought can help with this quite a bit, but even that fails for many problems). Here’s an example:
Several of the example sentences produced by ChatGPT above have “flabbergast” as the seventh word instead of the sixth word.
A similar issue often occurs when you ask a chatbot to generate a word with a certain number of occurrences of a certain letter, or a sentence with a certain number of occurrences of a certain word.
Text-generative AI systems “think” in terms of text. Their inputs are text tokens, their outputs are text tokens, and everything in between is just a series of learned transformations. This might work well for certain text-heavy tasks (e.g., generate a plausible response to a given statement), but it’s a poor representation for some other tasks. For example, text-generative AI systems often struggle with arithmetic. Perhaps they can correctly compute 1+1=2 because they’ve observed examples of token sequences in the training set that support this prediction, but when you ask them to evaluate longer expressions or expressions with longer / more complex answers, they often hallucinate an incorrect answer.
Similarly, many image-generative AI systems “think” about their outputs purely in terms of visual patterns. That might work well in certain cases, but if you ask an image generator (e.g., ChatGPT, Canva AI, Grok, etc) to, say, generate an image containing text, the generated text will often be completely incoherent. Visually, it might look like text, but it will often make no sense at a grammatical / logical level. Here’s an example from Grok:
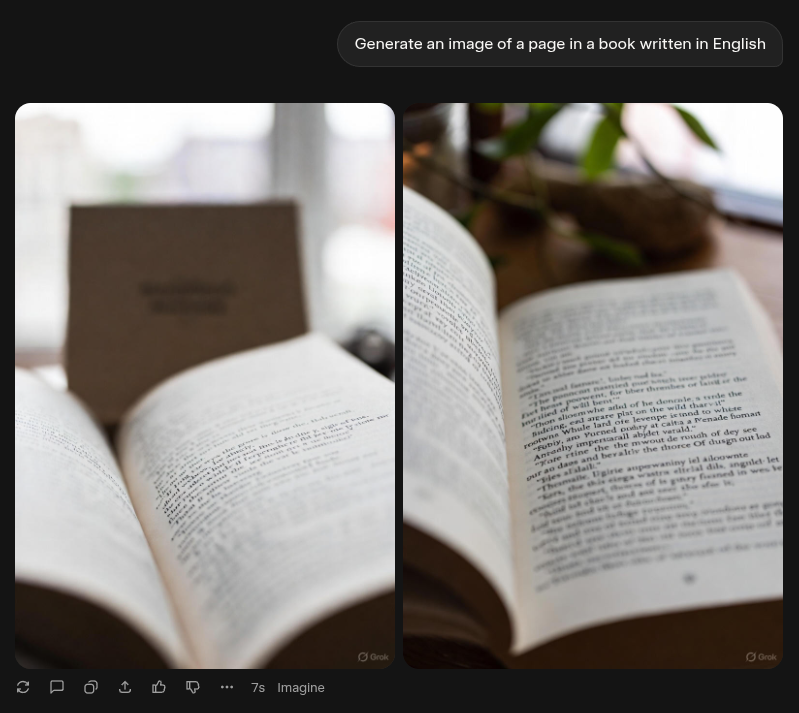
Yet another related example is that video-generative AI systems often produce videos that completely defy real-world physics.
These sorts of problems are due to using the wrong representation for a given task (which can create poor inductive biases). If inputs are represented and treated purely as text, then there’s no mathematical reasoning involved in the processing of those inputs. If outputs are represented and treated purely as pixels in an image, and / or frames in a video, then there’s no logical reasoning involved in the generation of those images or videos. Hence, the outputs of a generative AI system can appear correct at a superficial level, but fail to exhibit any deeper logical reasoning.
Generative AI systems are often large and extremely expensive to train, so they’re only retrained once in a great while. This means that their pretraining set is often outdated. Hence, if you ask, say, a text-generative AI system to produce an answer to a question that requires up-to-date knowledge, it will often fail:

The above prompt was generated shortly after the end of the 2025 shutdown, which lasted 43 days.
A workaround is retrieval-augmented generation (RAG), wherein the AI system looks up the prompt using some sort of search engine (e.g., Google’s search API) and summarizes the information that it finds. But RAG is more expensive than directly generating an answer, so many AI systems only conduct RAG selectively. Determining when RAG should be conducted is difficult; many systems will fail to conduct RAG when necessary for certain questions and generate outdated answers as a result.
Many text-generative AI systems will answer ill-posed questions as if they’re well-posed, often producing responses that sound plausible even though they’re completely fabricated:

Of course, nobody actually says that sailboats are like strawberries. The question itself rests on a faulty assumption, but ChatGPT’s response fails to acknowledge this.
These kinds of hallucinations can be particularly dangerous. Because they essentially affirm the user’s existing (faulty) beliefs, the user is unlikely to notice the mistake.
There are certain kinds of images that many image-generative AI systems seem to be incapable of generating.
For example, it’s well known that many image-generative AI systems are seemingly incapable of generating an image of a glass of wine that’s full to the brim. Here’s how Grok responds to such a prompt:
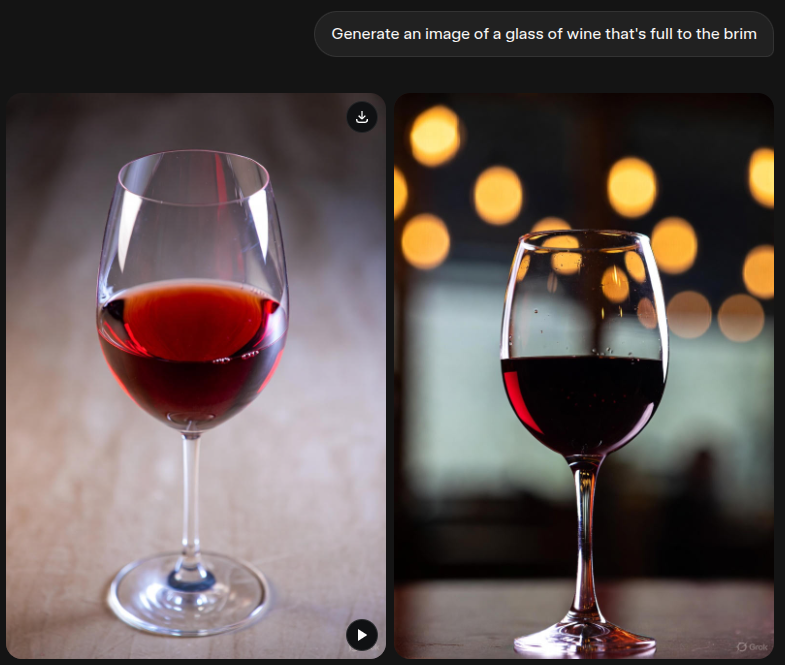
Even when you point out these mistakes to the AI system, it’ll often double down:
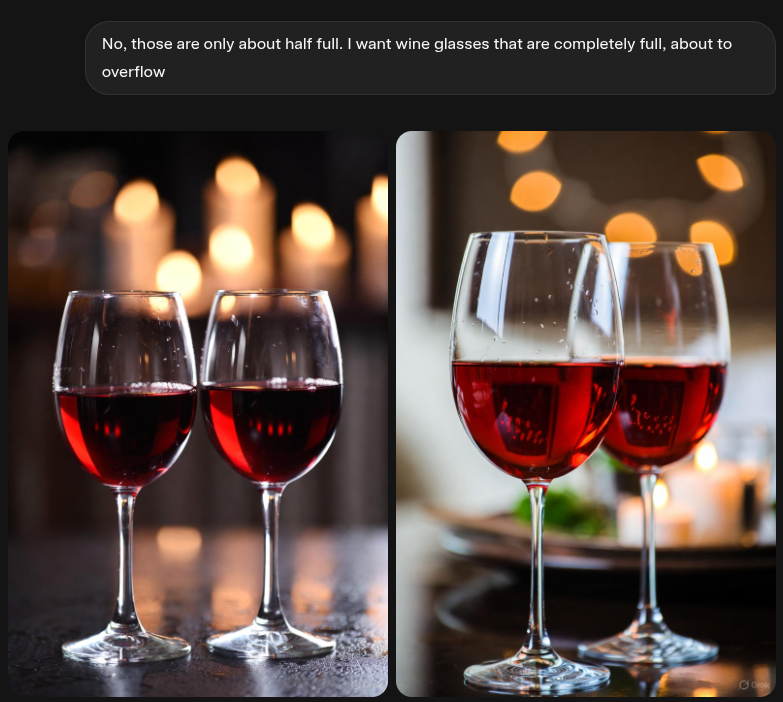
(Comically, it seems as though Grok understood that it needed to generate twice as much wine as before, but it didn’t understand that the wine still needed to be in the same number of glasses.)
Such issues are being actively researched. One possible cause is that the model learns to entangle certain concepts based on patterns in the training set. For example, if every glass of wine in the training set is half full, then the model might infer that being half full is part of the very definition of a glass of wine. That is, this is a failure to generalize to out-of-distribution data (i.e., categories of data that aren’t represented in the training set, such as glasses of wine that are full to the brim). Moreover, Grok might not even understand which part is the “glass” and which part is the “wine” (those concepts might also be entangled in the representation somehow), which would make it quite difficult to generate a glass that’s full of wine.
There are many other limitations of modern AI systems with entire subfields of active research dedicated to solving each one. A few more examples include: