Video Segmentation by Tracking Many Figure-Ground Segments
Fuxin Li, Taeyoung Kim, Ahmad Humayun, David Tsai, and James M. Rehg
Segment Pool Tracking + Composite Statistical Inference
Summary of the method
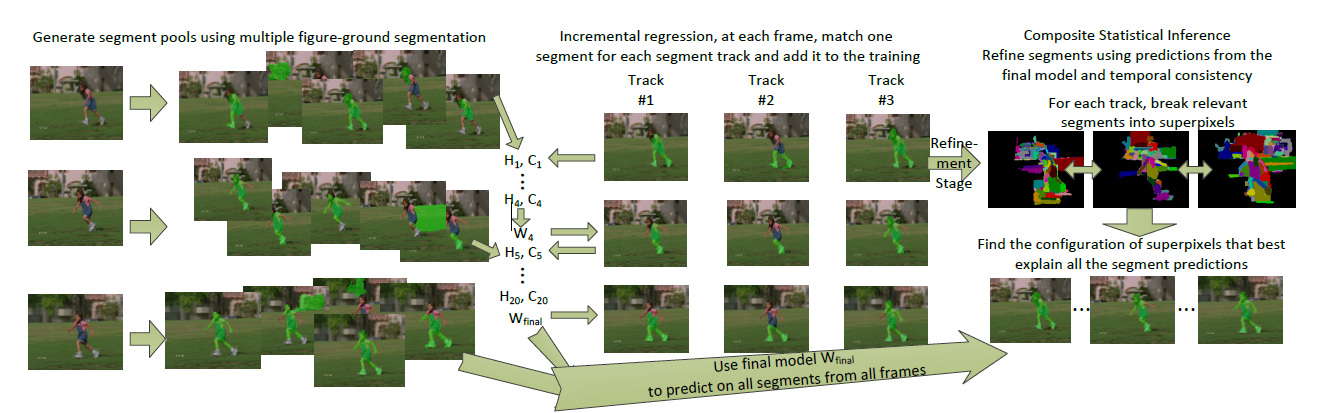
Segment Pool Tracking is the framework we presented for the video segmentation problem. The figure above illustrates the core parts of our approach. First, we generate a pool of segmentation for each frame using the CPMC method. Then, image color features (eg. Color-SIFT) are extracted and appearance models are trained incrementally to track multiple segments in consecutive frames. A main contribution is an efficient least-squares formulation to make simultaneously tracking 1,000 targets almost as efficient as tracking a single target. Since the appearance model for each target is learnt over multiple frames on many segments, it is robust to appearance changes and partial occlusions. Lastly, we use Composite Statistical Inference (CSI) to refine segment tracks by infering on high-order appearance terms while imposing temporal consistency.
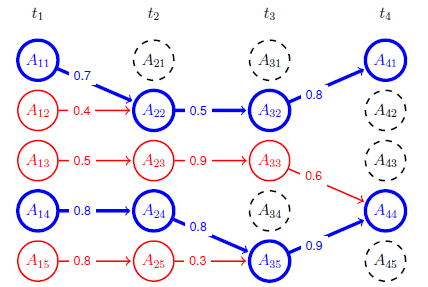
During tracking, greedy assignment is applied that serves as non-maximum suppression on segment tracks (see figure below). Tracks that are not consistent in appearance are filtered out automatically. Therefore, although we initialize with more than 1,000 tracks, on average only 60 tracks remain at the end of each sequence, while capturing most of the interesting objects.
Results of SPT and CSI on the SegTrack v2 dataset
| Image sequence | SPT | SPT+CSI | Pairwise Appearance | Lee et al. | Grundmann et al. | CPMC Best |
| | | (Using Pirsiavash et al.) | | | (Averaged Per-frame) |
|---|
| Mean per object | 62.7 | 65.9 | 55.4 | 45.3 | 51.8 | 78.6 |
| Mean per sequence | 68.0 | 71.2 | 58.6 | 57.3 | 50.8 | 80.5 |
| Girl | 89.1 | 89.2 | 83.4 | 87.7 | 31.9 | 93.5 |
| Birdfall | 62.0 | 62.5 | 47.8 | 49.0 | 57.4 | 72.2 |
| Parachute | 93.2 | 93.4 | 91.3 | 96.3 | 69.1 | 95.5 |
| Cheetah-Deer | 40.1 | 37.3 | 18.3 | 44.5 | 18.8 | 67.0 |
| Cheetah-Cheetah | 41.3 | 40.9 | 22.2 | 11.7 | 24.4 | 66.6 |
| Monkeydog-Monkey | 58.8 | 71.3 | 24.1 | 74.3 | 68.3 | 83.0 |
| Monkeydog-Dog | 17.4 | 18.9 | 16.5 | 4.9 | 18.8 | 44.6 |
| Penguin-#1 | 51.4 | 51.5 | 59.3 | 12.6 | 72.0 | 75.8 |
| Penguin-#2 | 73.2 | 76.5 | 79.1 | 11.3 | 80.7 | 90.4 |
| Penguin-#3 | 69.6 | 75.2 | 75.6 | 11.3 | 75.2 | 85.4 |
| Penguin-#4 | 57.6 | 57.8 | 47.1 | 7.7 | 80.6 | 67.6 |
| Penguin-#5 | 63.4 | 66.7 | 45.8 | 4.2 | 62.7 | 68.1 |
| Penguin-#6 | 48.6 | 50.2 | 56.7 | 8.5 | 75.5 | 76.6 |
| Drifting Car-#1 | 73.8 | 74.8 | 65.4 | 63.7 | 55.2 | 82.1 |
| Drifting Car-#2 | 58.4 | 60.6 | 59.8 | 30.1 | 27.2 | 75.3 |
| Hummingbird-#1 | 45.4 | 54.4 | 35.0 | 46.3 | 13.7 | 70.0 |
| Hummingbird-#2 | 65.2 | 72.3 | 65.8 | 74.0 | 25.2 | 82.2 |
| Frog | 65.8 | 72.8 | 69.0 | 0 | 67.1 | 87.1 |
| Worm | 75.6 | 82.8 | 59.5 | 84.4 | 34.7 | 89.8 |
| Soldier | 83.0 | 83.8 | 50.7 | 66.6 | 66.5 | 84.3 |
| Monkey | 84.1 | 84.8 | 70.9 | 79.0 | 61.9 | 88.3 |
| Bird of Paradise | 88.2 | 94.0 | 81.1 | 92.2 | 86.8 | 94.7 |
| BMX-Person | 75.1 | 85.4 | 74.5 | 87.4 | 39.2 | 86.9 |
| BMX-Bike | 24.6 | 24.9 | 30.9 | 38.6 | 32.5 | 58.5 |
| Avg. Number of Tracks | 60.0 | 60.0 | 702.8 | 10.6 | 336.6 | 1219.3 |
Citation
@inproceedings{FliICCV2013,
author = {Fuxin Li and Taeyoung Kim and Ahmad Humayun and David Tsai and James M. Rehg},
title = { Video Segmentation by Tracking Many Figure-Ground Segments},
booktitle = {ICCV},
year = {2013} }