
This page was last updated: May 20, 2025
Note:
The flip machines do not have GPU cards in them, so CUDA and OpenCL will not run there.
(You can compile there, you just can't run.)
If your own system has a GPU, you can try using that.
You can also use rabbit or the DGX machine.
Also, CUDA is an NVIDIA-only product.
It will not run on Intel or AMD GPUs.
Note: as there are two inputs to the tests you will run here (NUMTRIALS and BLOCKSIZE), this is a Pivot Table project.
Monte Carlo simulation is used to determine the range of outcomes for a series of parameters, each of which has a probability distribution showing how likely each option is to happen. In this project, you will take a scenario and develop a Monte Carlo simulation of it, determining how likely a particular output is to happen.
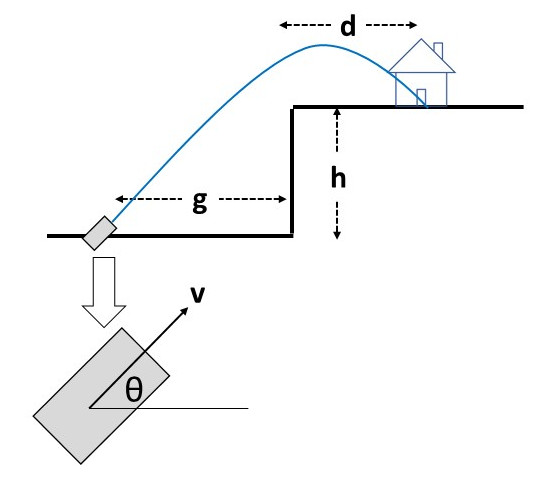
A castle sits on top of a cliff. An amateur band of merceneries is attempting to destroy it.
Normally this would be a pretty straightforward geometric calculation, but these are amateurs. What makes them amateurs you ask? It's because they are not very good at estimating distances, and not very good at aiming their cannon. They can only determine the 5 input parameters within certain ranges.
Your job is to figure out the probability that these doofuses will actually hit the castle. This is a job for multicore Monte Carlo simulation!
| Variable | Meaning | Range |
|---|---|---|
| g | Ground distance to the cliff face | 20. - 30. |
| h | Height of the cliff face | 10. - 20. |
| d | Upper deck distance to the castle | 10. - 20. |
| v | Cannonball initial velocity | 10. - 30. |
| θ | Cannon firing angle in degrees | 70. - 80. |
Same as Project #1.
Get the skeleton code here:
proj05.cu
Left-click on it to see it.
Right-click on it to download it.
Here are .h files you will need (right-click to download each one):
exception.h
helper_functions.h
helper_cuda.h
helper_image.h
helper_string.h
helper_timer.h
On rabbit, here is a working bash script:
#!/bin/bash
for t in 1024 4096 16384 65536 262144 1048576 2097152
do
for b in 8 32 64 128 256
do
/usr/local/apps/cuda/cuda-10.1/bin/nvcc -DNUMTRIALS=$t -DBLOCKSIZE=$b -o proj05 proj05.cu
./proj05
done
done
On the DGX system, here is a working sbatch script:
#!/bin/bash
#SBATCH -J MonteCarlo
#SBATCH -A cs475-575
#SBATCH -p classgputest
#SBATCH --gres=gpu:1
#SBATCH -o montecarlo.out
#SBATCH -e montecarlo.err
#SBATCH --mail-type=BEGIN,END,FAIL
#SBATCH --mail-user=mjb@oregonstate.edu
for t in 2048 8192 131072 2097152
do
for b in 8 16 32 64 128
do
/usr/local/apps/cuda/11.7/bin/nvcc -DNUMTRIALS=$t -DBLOCKSIZE=$b -o proj05 proj05.cu
./proj05
done
done
You can (and should!) write scripts to run the benchmark combinations. If you want to pass in benchmark parameters, the way you did it in g++ (-DNUMTRIALS=$t) notation works fine in nvcc.
Before you use the DGX, do your preliminary development on the rabbit system. It is a lot friendlier because you don't have to run your program through a batch submission. If you have time, take your final performance numbers on the DGX! They will be wonderfully higher than what you got on rabbit.
You can also take your benchmark numbers on your own machine.
In Project #1, you counted the number of times the cannonball hit the castle by saying numHits++. In Project #5, there is no single numHits on the GPU. So, now you will keep an array of hits in GPU memory. Your kernel will put either a 0 or a 1 there for each trial, then send the array back to the CPU, then your CPU program will add them all up.
Remember that CUDA is an NVIDIA-only product. It will not run on Intel or AMD GPUs.
Your commentary PDF should:
| Feature | Points |
|---|---|
| Correct probability | 10 |
| Performance table | 20 |
| Graph of performance vs. NUMTRIALS with multiple curves of BLOCKSIZE | 20 |
| Graph of performance vs. BLOCKSIZE with multiple curves of NUMTRIALS | 20 |
| Commentary -- explain the trends of the curves | 30 |
| Potential Total | 100 |