\(\newcommand{\zerobar}{{\overline{0}}}\) \(\newcommand{\onebar}{{\overline{1}}}\)
Viterbi Algorithm and General DP
The famous Viterbi Algorithm has a rather strange history. It was originally invented by the Italian-American electrical engineer Andrew Viterbi (1935-) in 1967 as a specialized algorithm to decode convolutional codes (in information theory and signal processing). Viterbi himself did not realize that this algorithm was just a special case of dynamic programming which had been proposed in the 1950s by Richard Bellman, even though they were colleagues at UCLA in the 1960s (well, one in Math and one in EE)!
Later on, researchers started generalizing Viterbi’s special algorithm to more and more domains, and its scope became broader and broader. Today, the general Viterbi algorithm is widely used not only in signal processing and information theory, but also in language and speech processing, computational biology, and AI in general, because these fields make heavy use of dynamic programming. As an extreme case, in natural language processing (NLP), the word “Viterbi” even became an adjective meaning “best”, as in “Viterbi parse” or “Viterbi alignment”.
Viterbi himself didn’t envision or participate in any of these later developments. But this algorithm was still pivotal in his academic and business careers. He was elected to the National Academy of Engineering in 1978 and received National Medal of Science in 2008 for Viterbi algorithm. He co-founded Qualcomm in 1985 (which uses this algorithm) and consequently became super rich. In 2004 he donated $52M to USC (where he received his PhD in 1963), resulting in the naming of USC Viterbi School of Engineering.
Around 2011 when I was working at the Viterbi School, Viterbi gave a talk about the Viterbi algorithm. I was very excited, but it turned out to be the most boring talk I ever attended. He talked about the original, specialized, narrow-sense algorithm that no computer scientist could understand, without any reference to the big picture of the general-sense algorithm (well, I guess maybe he himself didn’t know too much about it!).
In my view, Viterbi probably got way too much credit for the algorithm in the general sense (which should have been given to Bellman), but on the other hand, all phones today still use his original algorithm (in the narrow sense), so he deserves quite some credit in the human history.
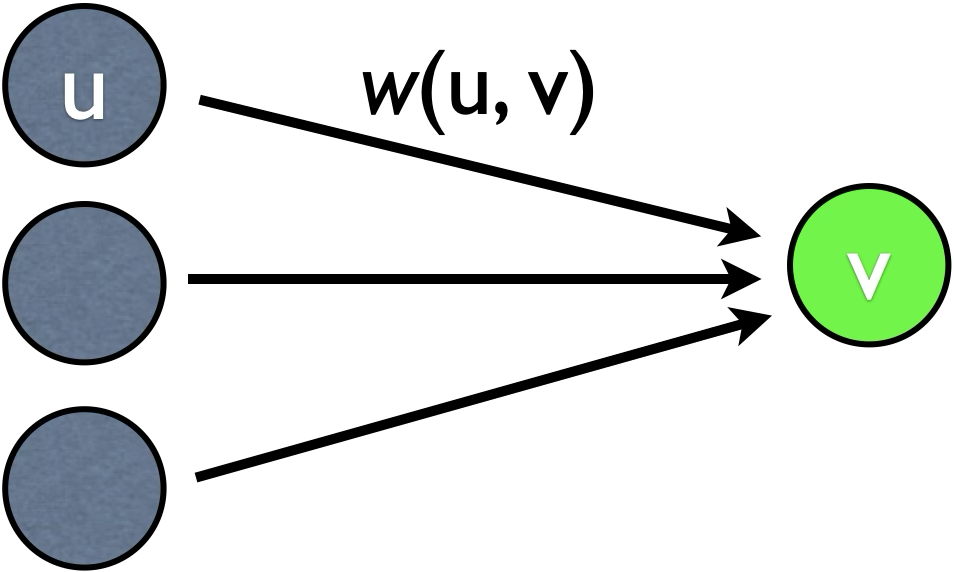
We will present the Viterbi algorithm in the most general sense, which includes other versions in many textbooks (in the fields of Algorithms, AI, NLP, and computational biology) as special cases. To be very generic, we need to describe this algorithm in the context of semirings (see Chap. 2). Given a DAG \(G=(V, E)\) with a special source node \(s\) and two semiring operators \(\oplus\) (summary) and \(\otimes\) (combination), we define the following concepts:
For example, for counting problems (e.g., number of paths), \((\oplus, \otimes)\) is \((+, \times)\), then \((\zerobar, \onebar)\) is \((0, 1)\), and \(\delta(v)\) is the number of paths from source \(s\) to node \(v\). For shortest path problems, \((\oplus, \otimes)\) is \((\min, +)\), then \((\zerobar, \onebar)\) is \((+\infty, 0)\), and \(\delta(v)\) is the shortest path length from \(s\) to \(v\). For longest path problems, just change \(\min\) to \(\max\) and \(+\infty\) to \(-\infty\).
Finally, we define \(d(v)\) to be the current estimate of the value for node \(v\). Initially, \(d(s)=\onebar\) and \(d(v)=\zerobar\) for all other nodes \(v\). Our goal is to fix \(d(v) = \delta(v)\) for all node \(v\) at the end of the Viterbi algorithm.
The way we achieve this is through updates. A generic update along an edge \((u, v)\) looks like this:
\[d(v) \oplus= d(u) \otimes w(u, v)\]
Here the C/Python-style shorthand notation \(x \oplus= y\) just means \(x = x \oplus y\). For example, if \(\oplus\) is \(+\) (in counting problems), it means \(x +\!= y\) and if \(\oplus\) is \(\min\) (in shortest path problems), it means \(x = \min(x, y)\).
The crucial condition is that whenever you update along an edge \((u, v)\), you should make sure \(d(u)\) is already fixed to its final value \(\delta(u)\), so that the update only happens once along this edge. Otherwise, if \(d(u)\) itself later gets updated, you will need to re-update \(d(v)\) along this edge, and these repeated updates will greatly slow down the runtime.
We will see that in both Viterbi and Dijkstra, the above condition holds (but due to very different reasons), so that each edge is indeed used for update (at most) once. This is why Viterbi and Dijkstra are both very efficient. By contrast, some more complex algorithms such as Bellman-Ford involve repeated updates (e.g., to handle negative edges).
A real-life analogy is that on all flights, you were always told that in case of emergency, tie your own air mask before helping others.
Now we can finally present the Viterbi algorithm, which performs two steps:
Why is it correct? Well, it’s due to acyclicity and topological order. You can prove by induction that when visiting \(v\) in the topological order, all nodes before \(v\) in the topological order have already been visited and thus fixed, which includes all prerequisites \(u\) of \(v\) where \((u,v)\in E\).
Note that this notion of Viterbi is so general that it works for all semirings, and therefore, this algorithm can be used to
Thus almost all DP algorithms we have seen so far are instances of Viterbi.
For example, in 0-1 knapsack, we are filling a two-dimensional table \((w, i)\), and we can write two orders to fill this table using two nested for loops:
for w = 1 to W:
for i = 1 to n:
...Or swap the two loops:
for i = 1 to n:
for w = 1 to W:
...From the Viterbi point of view, the only difference between the two is the topological order (row first or column first). In fact, there are many other topological orders (such as diagonal first). So a bottom-up implementation of DP (like the two above) explicitly states a predefined topological order (often by nested for loops), while a top-down implementation uses DFS to figure out the topological order on the fly.
A very natural (and common) variant is to update along outgoing edges rather than incoming edges:
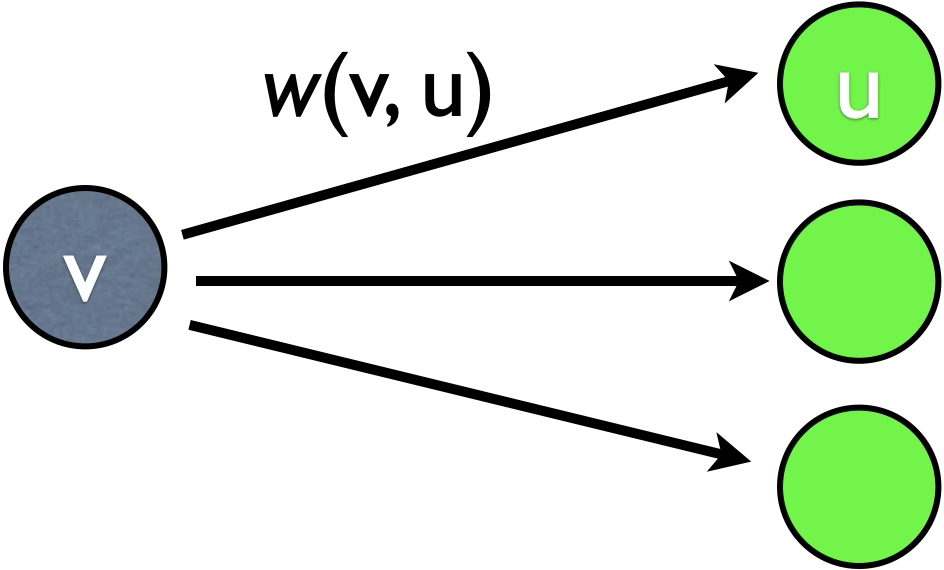
This version is probably even easier to understand than the standard version above. The invariant here is that when visiting \(v\) in the topological order, \(d(v)\) is already fixed because all nodes that can influence \(v\) must be before \(v\) in the topological order and have all been visited already.
Another variant eluded to above corresponds to the top-down implementation of DP (i.e., memoization). The Viterbi interpretation is to recursively solve the problem along an implicit topological order induced by DFS (but we don’t need the explicit order). Here is the pseudocode:
def Viterbi(V, E, t): # t is target node
def solve(v): # memoized recursion
if v not in d: # already computed?
for each u->v edge in E: # solve prereqs first
d[v] \oplus= solve(u) \otimes w(u, v)
return d[v]
d = {} # cache
return solve(t) # from target nodeYou might be wondering, is all DP basically Viterbi? Well, no, there are DP instances beyond Viterbi:
First, there is DP on hypergraphs, such as number of BSTs and RNA folding. The latter is isomorphic to many other famous problems such as matrix-chain multiplication, context-free parsing, optimal BST, and optimal triangulation. But we can call them “Genearlized Viterbi on Directed Acyclic Hypergraphs (DAHs)”; this is, of course, generalizing Viterbi to the very extreme. So, in a way, this case is still very much Viterbi in spirit (i.e., based on the topological order).
Secondly, there is best-first DP using BFS/Dijkstra. It turns out we can also solve many DP problems using BFS (unweighted graph) or Dijkstra (non-negative weighted graph), such as coins, edit distance, and sequence alignment. These problems are often shortest-path problems on graphs with non-negative edges (or can be converted to such problems). The key difference is that instead of topological order, we use a best-first (or breadth-first) order to explore nodes, and this is often faster on many problems. This case, however, is genuinely beyond Viterbi.
The bottom line is, the general notion of Viterbi includes the most common use cases of DP. Most of the DP you will ever use in your work is likely within Viterbi. The essence of Viterbi is the topological order among subproblems, so that when solving a particular subproblem, all the smaller subproblems that it depends on have already been solved. This last sentence summarizes the connections between divide-and-conquer, DP, and graph algorithms, and is probably the most important observation you can take away from this course.