
- 2026/2: The SamplingDesign paper by undergraduate student Wei Yu Tang (now PhD student at USC) published by Nature Communications.
- 2025/8: With his groundbreaking Science paper on mRNA design, PhD alumni He Zhang (graduated 2022) became the second computer scientist ever to publish first-author papers in both Nature and Science (he was also the first author of our Nature paper on mRNA design). Only David Silver of AlphaGo has done that before as a computer scientist.
- 2024/03: My Nature paper was featured in this College of Engineering story.
- 2024/02: We (PI Huang, co-PI Mathews) were one of the 9 teams nationwide to receive major funding for interdisciplinary RNA research. See news release from NSF/NIH.
- 2023/11: I gave a Distinguished Lecture at UW Paul Allen School of CSE (video).
- 2023/10: I gave an invited talk at the 11th mRNA Health Conference, co-organized by 2023 Nobel Laureate Katalin Kariko. Dr. Kariko commented on my work in her keynote.
- 2023/05: Landmark Nature paper (pre-)published (as an accelerated article preview); see also Nature news. I reduced mRNA design to lattice parsing (1961, Bar-Hillel construction, i.e., "the intersection of context-free and regular languages is still context-free").
- 2023/03: My first PhD student Ashish Vaswani (1st-author of the Transformer paper) was featured in this USC story about ChatGPT.
- 2022/11: LinearSampling published by Nucleic Acids Research.
- 2021/11: LinearTurboFold published by PNAS. First PNAS paper from OSU College of Engineering.
- 2021/07: Delivered ISMB 2021 Integrative RNA COSI Keynote.
- 2021/06: Delivered CVPR 2021 Invited Talk.
- 2020/04: two ACL 2020 papers and one ISMB 2020 paper (linearpartition) accepted.
- 2019/06: Delivered ACL 2019 Keynote Speech (attended by 2000+ researchers).
- 2019/05: We have 3 ACL 2019 papers accepted.
- 2019/05: LinearFold is accepted by ISMB 2019 (top conference in bioinformatics and comp. bio.) and will appear in Bioinformatics in July.
- 2019/04: I was recognized as one of the most influential NLP researchers in the past ten years (2007-2017) by the CS citation index Aminer from Tsinghua University.
- 2018/10: groundbreaking work in simultaneous translation -- first practical system that achieves high quality and low latency (done at Baidu Research). Media coverage by IEEE Spectrum, MIT Technology Review, FORTUNE, etc. Also covered by two podcasts: Data Skeptic and Eye on AI.
- 2018/09: Ph.D. student Mingbo Ma defended (4th PhD graduate) and will become a Research Scientist at Baidu Research (Silicon Valley).
- 2018/08: 4 papers (3 long, 1 short) in EMNLP 2018.
- 2018/07: Funded by NSF, NIH, and Intel.
- 2018/05: SIGMOD 2018 Best Paper Finalist.
- 2018/03: csrankings.org ranks OSU 15th in NLP (mostly our group), 20th in broad AI, and 36th in CS (in the US).
- 2018/02: We released the world's fastest RNA secondary structure prediction server, powered by the first linear-time prediction algorithm, based on our earlier work in computational linguistics. It is orders of magnitude faster than existing ones, with comparable or even higher accuracy. Code on Github.
- 2017/10: Serving as an Senior Area Chair (syntax/parsing) for ACL 2018.
- 2017/09: I'm giving an invited talk at EMNLP 2017 Workshop on Structured Prediction. [slides]
- 2017/07: three papers accepted by EMNLP 2017. I had my first first-author paper after a 5-year gap; it feels great getting back to real work!
- 2017/06: Ph.D. alumni Ashish Vaswani's recent work on attention received a lot of attention itself, bringing a revolution in deep learning for NLP.
- 2017/06: Ph.D. student Mingbo Ma participated in the WMT 2017 competition on multimodal translation, and achieved the best TER score among 15 systems on the English+Image->German COCO task (the hardest task in that competition, since it's into German rather than French, and tested on out of domain images).
- 2017/05: Ph.D. student Kai Zhao successfully defended and accepted a rare Research Scientist offer from Google Research (NYC).
- 2017/05: We were part of the OSU team in the DARPA Explanable AI (XAI) grant ($6.5M total).
- 2017/01: We are hosting Oregon's first and only University site for North American Computational Linguistics Olympiad (NACLO)!
- 2016/12: Ph.D. student James Cross successfully defended, and joined Facebook as a Research Scientist.
- 2016/11: James's EMNLP 2016 paper received an Honorable Mention for Best Paper (and unanimous full-score reviews).
- 2016/07: Ph.D. alumni (USC) Ashish Vaswani joined Google Brain as a Research Scientist.
- 2015/09: Postdoc Feifei Zhai joined IBM T. J. Watson as a Research Staff Member.
- 2015/09: Our group moved to Oregon State University after three years at the City University of New York.
- 2015/07: We received a Yahoo! Faculty Engagement Award.
I am most interested in the theoretical and algorithmic aspects of biology and language, and many of my NLP/bio papers draw unexpected connections from theoretical computer science, e.g., my synchronous binarization algorithm (binarizing a synchronous context-free grammar in linear-time) was inspired by Graham Scan for Convex Hull, my LinearDesign algorithm (optimal mRNA design) uses the intersection between context-free and regular languages, and my k-best parsing algorithms are often featured in my Algorithms courses.
On the other hand, my recent work in NLP pioneered the field of simultaneous translation, turning it from obscurity to spotlight. See my ACL 2019 Keynote and CVPR 2021 Invited Talk.
Listing of my papers on Google Scholar, Semantic Scholar, and a subset (top conferences) in csrankings.org.
Recent and Past Talks [playlist]
 Linear-Time Algorithms for RNA Folding and mRNA Design to Fight COVID-19.
Linear-Time Algorithms for RNA Folding and mRNA Design to Fight COVID-19.
- U. of Washington Allen School of Computer Science (UW/CSE), Distinguished Lecture Series (Nov. 2023).
[youtube]
- Allen Inst. of AI (AI2) (Nov. 2023) [youtube]
- 11th mRNA Health Conference (co-organized by Nobel Laureate Katalin Kariko) (Oct. 2023). [youtube]
- Dr. Kariko's comment on my work in her keynote (she referred to me as "the mathematician")
- Tsinghua University AIR (in Chinese) (Sep. 2022). [youtube] [bilibili]
- Bayer (Aug. 2022).
- Columbia University NLP Seminar (Apr. 2022). [youtube (missing the first 5 minutes)]
- Pfizer (Nov. 2021).
- University of Edinburgh Inst. for Language, Cognition and Computation (ILCC) Seminar (Nov. 2021).
- ISMB 2021 iRNA COSI Keynote (July 2021). [youtube]
- U. of Washington Allen School of Computer Science (UW/CSE), Distinguished Lecture Series (Nov. 2023).
[youtube]
-
Simultaneous Translation: Recent Advances and Remaining Challenges.
-
ACL 2019 Keynote.
[slides (keynote)]
[slides (pdf)]
[video (livecongress)] [youtube]
- Updated version: CVPR 2021 Invited Talk [youtube].
-
ACL 2019 Keynote.
[slides (keynote)]
[slides (pdf)]
[video (livecongress)] [youtube]
-
Linguistis Meets Biology: LinearFold: Linear-Time Prediction of RNA Secondary Structures.
Invited talk at Univ. of Rochester Medical School (Bioinfo. Cluster), Stanford Medical School (EternaCon 2018), and 2nd Southern California NLP Symposium.
[slides] -
Human-Inspired Structured Prediction for Language and Biology.
Invited talk at UC Santa Cruz. [slides] -
Breakthrough in Simultaneous Translation.
Invited talk at Stanford and Google. [slides] -
Marrying Dynamic Programming with Recurrent Neural Nets for Structured Prediction.
Invited talk at EMNLP 2017 Workshop on Structured Prediction. [slides] - Scalable Large-Margin Structured Prediction: Theory and Algorithms. ACL 2014/2015 Tutorials.
slides.
- Structured Learning with Inexact Search.
Talks given at UMass Amherst, IBM, Columbia, Rochester, etc.
slides.
- Dynamic Programming for Incremental Parsing.
Talks given at UCSD, Google, JHU, MIT, IBM, etc.
slides and video from the talk at JHU CLSP Seminar (Sep 2010). - Tree-based and Forest-based Translation.
Talks given at BBN, CUHK, Berkeley, Pomona, etc.
slides.
- Forest-based Algorithms in NLP (thesis work).
Talks given at MIT, Google, Stanford, CMU, etc.
- version 1 (includes cube pruning, but no forest-based translation):
video from the CLSP seminar talk at JHU (on vimeo) (April 2008).
video from the Google techtalk (on youtube) (March 2008). slides. - version 2 (includes forest-based translation but no cube pruning; ≈thesis defense):
slides from the LTI seminar talk at CMU (May 2009).
- version 1 (includes cube pruning, but no forest-based translation):
Selected Recent Work
(for the full list please visit my Google Scholar page)- 2026
- Wei Yu Tang, Ning Dai, Tianshuo Zhou, David H. Mathews, Liang Huang (2026). Sampling-based Continuous Optimization with Coupled Variables for RNA Design.
Nature Communications. earlier arXiv version - Tianshuo Zhou, David H. Mathews, and Liang Huang (2026).
Probabilistic RNA Designability via Interpretable Ensemble Approximation and Dynamic Decomposition.
In Proceedings of ISMB 2026. Also in Bioinformatics. earlier arXiv version
- Wei Yu Tang, Ning Dai, Tianshuo Zhou, David H. Mathews, Liang Huang (2026). Sampling-based Continuous Optimization with Coupled Variables for RNA Design.
- 2025
- Ning Dai, Tianshuo Zhou, Wei Yu Tang, David H. Mathews, Liang Huang (2025).
Messenger RNA Design for Ensemble Free Energy via Probabilistic Lattice Parsing.
In Proceedings of ISMB 2025. Also in Bioinformatics, vol. 41. [slides] - Tianshuo Zhou, Apoorv Malik, Wei Yu Tang, David H. Mathews, Liang Huang (2025).
Scalable and Interpretable Identification of Minimal Undesignable RNA Structure Motifs with Rotational Invariance
In Proceedings of RECOMB 2025. [code] [server]
- Ning Dai, Tianshuo Zhou, Wei Yu Tang, David H. Mathews, Liang Huang (2025).
Messenger RNA Design for Ensemble Free Energy via Probabilistic Lattice Parsing.
- 2024
- Tianshuo Zhou, Wei Yu Tang, David H. Mathews, and Liang Huang (2023).
Undesignable RNA Structure Identification via Rival Structure Generation and Structure Decomposition.
In Proceedings of RECOMB 2024. - Apoorv Malik, Liang Zhang, Milan Gautam, Ning Dai, Sizhen Li, He Zhang, David H. Mathews, Liang Huang (2024).
LinearAlifold: Linear-Time Consensus Structure Prediction for RNA Alignments.
Journal of Molecular Biology, 436 (17).
- Tianshuo Zhou, Wei Yu Tang, David H. Mathews, and Liang Huang (2023).
Undesignable RNA Structure Identification via Rival Structure Generation and Structure Decomposition.
- 2023
- He Zhang, Liang Zhang, Ang Lin, Congcong Xu, ..., Hangwen Li, David H. Mathews, Yujian Zhang, and Liang Huang (2023). Algorithm for Optimized mRNA Design Improves Stability and Immunogenicity.
Nature (621), 396-403 (first published as Accelerated Article Preview in May 2023).
Nature News: Remarkable AI tool for mRNA Design (by Dr. Elie Dolgin) [local copy].
Nature News & Views: A tool for optimizing mRNA sequence (by Prof. Anna Blakney) [local copy].
(LinearDesign paper: solving optimal mRNA design via the classical NLP concept of lattice parsing) - Tianshuo Zhou, Ning Dai, Sizhen Li, Max Ward, David H. Mathews, and Liang Huang (2023).
RNA Design via Structure-Aware Multi-Frontier Ensemble Optimization.
In Proceedings of ISMB 2023; journal version in Bioinformatics, 2023. - He Zhang, Sizhen Li, Ning Dai, Liang Zhang, David H Mathews, Liang Huang (2023).
LinearCoFold and LinearCoPartition: linear-time algorithms for secondary structure prediction of interacting RNA molecules
Nucleic Acids Research, 51 (18).
- He Zhang, Liang Zhang, Ang Lin, Congcong Xu, ..., Hangwen Li, David H. Mathews, Yujian Zhang, and Liang Huang (2023). Algorithm for Optimized mRNA Design Improves Stability and Immunogenicity.
- 2022
- He Zhang, Sizhen Li, Liang Zhang, David Mathews, and Liang Huang (2022).
LazySampling and LinearSampling: Fast Stochastic Sampling of RNA Secondary Structure with Applications to SARS-CoV-2.
Nucleic Acids Research, 51 (2).
[preprint] [code] [server] - He Bai, Renjie Zheng, Junkun Chen, X. Li, M. Ma, and Liang Huang (2022).
A3T: Alignment-Aware Acoustic and Text Pretraining for Speech Synthesis and Editing.
In Proceedings of ICML 2022. - Hui Zhang, Tian Yuan, Junkun Chen, Xintong Li, Renjie Zheng, et al., Liang Huang (2022).
PaddleSpeech: An Easy-to-Use All-in-One Speech Toolkit.
In Proceedings of NAACL 2022: Demo Track. Best Demo Paper Award.
[code] [demo video] - He Zhang, Liang Zhang, Kaibo Liu, Sizhen Li, David H. Mathews, and Liang Huang (2022).
Linear-Time Algorithms for RNA Structure Prediction.
In RNA Structure Prediction. Methods in Molecular Biology series, Vol. 2586, Springer. [pdf]
- He Zhang, Sizhen Li, Liang Zhang, David Mathews, and Liang Huang (2022).
LazySampling and LinearSampling: Fast Stochastic Sampling of RNA Secondary Structure with Applications to SARS-CoV-2.
- 2021
- Sizhen Li, He Zhang, L. Zhang, K. Liu, B. Liu, David Mathews, and Liang Huang (2021). LinearTurboFold: Linear-Time Global Prediction of Conserved Structures for RNA Homologs with Applications to SARS-CoV-2.
Proceedings of the National Academy of Sciences (PNAS), 118 (52).
[code] [web server] - Junkun Chen, Renjie Zheng, Atsuhito Kita, Mingbo Ma, and Liang Huang (2021).
Improving Simultaneous Translation by Incorporating Pseudo-References with Fewer Reorderings.
In Proceedings of EMNLP 2021. - Renjie Zheng, Junkun Chen, Mingbo Ma, and Liang Huang (2021).
Fused Acoustic and Text Encoding for Multimodal Bilingual Pretraining and Speech Translation.
In Proceedings of ICML 2021. - S. Li, Jingbo Zhou, T. Xu, Liang Huang, F. Wang, H. Xiong, W. Huang, Dejin Dou, and Hui Xiong (2021).
Structure-aware Interactive Graph Neural Networks for the Prediction of Protein-Ligand Binding Affinity.
In Proceedings of KDD 2021 - Junkun Chen, Mingbo Ma, Renjie Zheng, and Liang Huang (2021).
Direct Simultaneous Speech-to-Text Translation Assisted by Synchronized Streaming ASR.
In Proceedings of ACL 2021: Findings.
- Sizhen Li, He Zhang, L. Zhang, K. Liu, B. Liu, David Mathews, and Liang Huang (2021). LinearTurboFold: Linear-Time Global Prediction of Conserved Structures for RNA Homologs with Applications to SARS-CoV-2.
- 2020
- He Zhang, Liang Zhang, David H. Mathews, Liang Huang (2020).
LinearPartition: Linear-Time Approximation of RNA Folding Partition Function and Base Pairing Probabilities.
Proceedings of ISMB 2020; journal version in Bioinformatics, July, 2020.
[web server] [code] [talk] - Mingbo Ma, Baigong Zheng, Kaibo Liu, Renjie Zheng, H Liu, Kainan Peng, Ken Church, Liang Huang (2020).
Incremental Text-to-Speech Synthesis with Prefix-to-Prefix Framework.
In Proceedings of EMNLP 2020: Findings. - Renjie Zheng, Mingbo Ma, Baigong Zheng, Kaibo Liu, Jiahong Yuan, Ken Church, Liang Huang (2020).
Fluent and Low-latency Simultaneous Speech-to-Speech Translation with Self-adaptive Training.
In Proceedings of EMNLP 2020: Findings. - Renjie Zheng, Mingbo Ma, Baigong Zheng, Kaibo Liu, Liang Huang (2020).
Opportunistic Decoding with Timely Correction for Simultaneous Translation.
In Proceedings of ACL 2020. - Baigong Zheng, Kaibo Liu, Renjie Zheng, Mingbo Ma, and Liang Huang (2020).
Simultaneous Translation Policies: From Fixed to Adaptive.
In Proceedings of ACL 2020.
- He Zhang, Liang Zhang, David H. Mathews, Liang Huang (2020).
LinearPartition: Linear-Time Approximation of RNA Folding Partition Function and Base Pairing Probabilities.
- 2019
- Liang Huang, He Zhang*, Dezhong Deng*, Kai Zhao, Kaibo Liu, David Hendrix, David Mathews (2019).
LinearFold: Linear-Time Approximate RNA Folding by 5'-to-3' Dynamic Programming and Beam Search.
Bioinformatics, Vol. 35, July 2019, ISMB 2019 Proceedings.
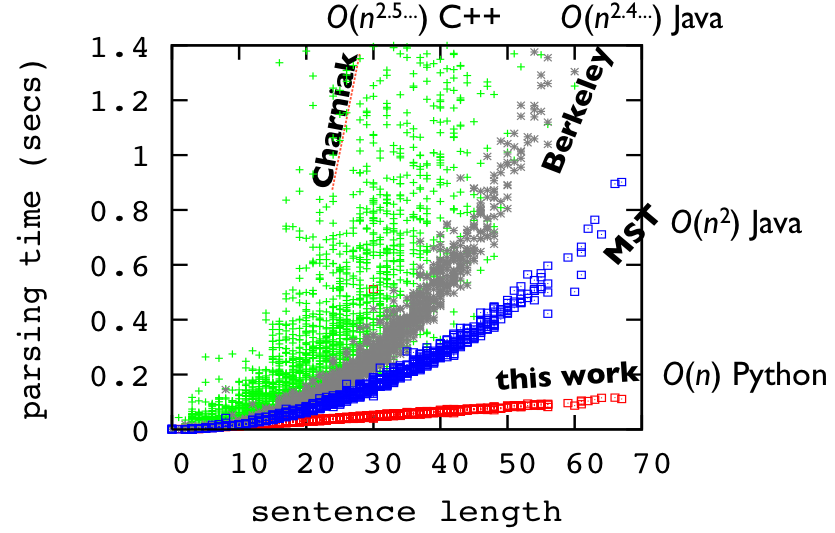
The first linear-time algorithm for (global) RNA folding; first major speedup in 40 years; orders of magnitude faster than existing cubic-time ones.
[web server] [code] [slides] - Mingbo Ma*, Liang Huang*, Hao Xiong, Renjie Zheng, Kaibo Liu, Baigong Zheng,
Chuanqiang Zhang, Zhongjun He, H. Liu, X. Li, H. Wu, Haifeng Wang (2019).
STACL: Simultaneous Translation with Integrated Anticipation and Controllable Latency using Prefix-to-Prefix Framework.
Proceedings of ACL 2019.
[demos and media reports] - Baigong Zheng, Renjie Zheng, Mingbo Ma, Liang Huang (2019).
Simultaneous Translation with Flexible Policy via Restricted Imitation Learning.
In Proceedings of ACL 2019. - Hairong Liu, Mingbo Ma, Liang Huang, Hui Xiong, Zhongjun He (2019).
Robust Neural Machine Translation with Joint Textual and Phonetic Embedding.
In Proceedings of ACL 2019. - Baigong Zheng, Renjie Zheng, Mingbo Ma, Liang Huang (2019).
Simpler and faster learning of adaptive policies for simultaneous translation.
In Proceedings of EMNLP 2019. - Renjie Zheng, Mingbo Ma, Baigong Zheng, Liang Huang (2019).
Speculative Beam Search for Simultaneous Translation.
In Proceedings of EMNLP 2019. - Mingbo Ma, Renjie Zheng, Liang Huang (2019).
Learning to Stop in Structured Prediction for Neural Machine Translation.
In Proceedings of NAACL 2019.
- Liang Huang, He Zhang*, Dezhong Deng*, Kai Zhao, Kaibo Liu, David Hendrix, David Mathews (2019).
LinearFold: Linear-Time Approximate RNA Folding by 5'-to-3' Dynamic Programming and Beam Search.
Bioinformatics, Vol. 35, July 2019, ISMB 2019 Proceedings.
- 2018
- Renjie Zheng, Mingbo Ma, and Liang Huang (2018).
Multi-Reference Training with Pseudo-References for Neural Translation and Text Generation.
In Proceedings of EMNLP 2018. - Yilin Yang, Liang Huang, and Mingbo (2018).
Breaking the Beam Search Curse: A Study of (Re-)Scoring Methods and Stopping Criteria for Neural Machine Translation.
In Proceedings of EMNLP 2018. - Wen Zhang, Liang Huang, Yang Feng, Lei Shen, and Qun Liu (2018).
Speeding Up Neural Machine Translation Decoding by Cube Pruning.
In Proceedings of EMNLP 2018. - Jiaji Huang, Yi Li, Wei Ping, and Liang Huang (2018).
Large-Scale Neural Language Models.
In Proceedings of EMNLP 2018. -
P. Danaee, M. Rouches, M. Wiley, D. Deng, L. Huang, and D. Hendrix (2018).
bpRNA: large-scale automated annotation and analysis of RNA secondary structure.
Nucleic Acids Research (2018), 46 (11): 5381-5394. - Juneki Hong and Liang Huang (2018).
Linear-Time Constituency Parsing with RNNs and Dynamic Programming.
In Proceedings of ACL 2018. [slides] - B. McCamish, V. Ghadakchi, A. Termehchy, B. Touri, and L. Huang (2018).
The Data Interaction Game.
In Proceedings of SIGMOD 2018. Best Paper Finalist.
- Renjie Zheng, Mingbo Ma, and Liang Huang (2018).
Multi-Reference Training with Pseudo-References for Neural Translation and Text Generation.
- 2017-2015
- Tianze Shi, Liang Huang, and Lillian Lee (2017).
Fast(er) Exact Decoding and Global Training for Transition-Based Dependency Parsing via A Minimal Feature Set.
In Proceedings of EMNLP 2017. [arXiv] [slides] - Kai Zhao and Liang Huang (2017).
Joint Syntacto-Discourse Parsing and the Syntacto-Discourse Treebank.
In Proceedings of EMNLP 2017. [arXiv] [poster] [data] - Liang Huang, Kai Zhao, and Mingbo Ma (2017).
When to Finish? Optimal Beam Search for Neural Text Generation (modulo beam size).
In Proceedings of EMNLP 2017. [arXiv] [poster] - Mingbo Ma, Liang Huang, Bing Xiang, and Bowen Zhou (2017).
Group Sparse CNNs for Question Classification with Answer Sets.
In Proceedings of ACL 2017. [slides] [poster] - James Cross and Liang Huang (2016).
Span-Based Constituency Parsing with a Structure-Label System and Provably Optimal Dynamic Oracles.
In Proceedings of EMNLP 2016. [code] [slides] [video] [bib]
Best Paper Honorable Mention. (received unanimous full-score reviews; first neural parser to advance the state-of-the-art of constituency parsing.) - James Cross and Liang Huang (2016).
Incremental Parsing with Minimal Features Using Bi-Directional LSTM.
In Proceedings of ACL 2016. [arXiv] [bib] [poster] [slides] - Kai Zhao, Liang Huang, and Mingbo Ma (2016).
Textual Entailment with Structured Attentions and Composition.
In Proceedings of COLING 2016. [arXiv] [code] [slides] - Feifei Zhai, Liang Huang and Kai Zhao (2015).
Search-Aware Tuning for Hierarchical Phrase-based Decoding.
In Proceedings of EMNLP 2015. - Mingbo Ma, Liang Huang, Bing Xiang, and Bowen Zhou (2015).
Dependency-based Convolutional Neural Networks for Sentence Embedding.
In Proceedings of ACL 2015. [slides] [code] [bib] - Kai Zhao and Liang Huang (2015).
Type-Driven Incremental Semantic Parsing with Polymorphism.
In Proceedings of NAACL 2015. [slides] - Haitao Mi and Liang Huang (2015).
Shift-Reduce Constituency Parsing with Dynamic Programming and POS Tag Lattice.
In Proceedings of NAACL 2015. - I. Naim, Y. Song, Q. Liu, L. Huang, H. Kautz, J. Luo, and D. Gildea (2015).
Discriminative Unsupervised Alignment of Natural Language Instructions with Corresponding Video Segments.
In Proceedings of NAACL 2015. - Wenbin Jiang, Yajuan Lv, Liang Huang, and Qun Liu (2015).
Automatic Adaptation of Annotations.
Computational Linguistics, 41 (1), pp. 119-147.
- Tianze Shi, Liang Huang, and Lillian Lee (2017).
Fast(er) Exact Decoding and Global Training for Transition-Based Dependency Parsing via A Minimal Feature Set.
- machine translation
- Lemao Liu and Liang Huang (2014).
Search-Aware Tuning for Machine Translation.
In Proceedings of EMNLP 2014. [slides] [Taro's talk video] (Thanks Taro!) - Kai Zhao, Liang Huang, Haitao Mi, and Abe Ittycheriah (2014).
Hierarchical MT Training using Max-Violation Perceptron.
In Proceedings of ACL 2014. [Kai's talk video] - Heng Yu, Liang Huang, Haitao Mi, and Kai Zhao (2013).
Max-Violation Perceptron and Forced Decoding for Scalable MT Training.
In Proceedings of EMNLP 2013. [slides] [poster] [spotlight]
This is the first successful effort of large-scale discriminative training for MT, with +2.0/+1.5 BLEU improvements over MERT/PRO. - Ashish Vaswani, Liang Huang and David Chiang (2012). Smaller Alignment Models for Better Translations: Unsupervised Word Alignment with the L0-norm.
In Proceedings of ACL 2012. [Ashish's code (a patch on GIZA++)]
- Lemao Liu and Liang Huang (2014).
Search-Aware Tuning for Machine Translation.
- parsing algorithms
- Kai Zhao, James Cross, and Liang Huang (2013).
Optimal Incremental Parsing via Best-First Dynamic Programming.
In Proceedings of EMNLP 2013. - Yoav Goldberg, Kai Zhao and Liang Huang (2013).
Efficient Implementation for Beam Search Incremental Parsers.
To appear in Proceedings of ACL 2013 (short paper).
- Kai Zhao, James Cross, and Liang Huang (2013).
Optimal Incremental Parsing via Best-First Dynamic Programming.
- machine learning
- Hao Zhang, Liang Huang, Kai Zhao, and Ryan McDonald (2013).
Online Learning with Inexact Hypergraph Search.
In Proceedings of EMNLP 2013. - Kai Zhao and Liang Huang (2013).
Minibatch and Parallelization for Online Structured Learning.
To appear in Proceedings of NAACL 2013. - Liang Huang, Suphan Fayong, and Yang Guo (2012).
Structured Perceptron with Inexact Search.
In Proceedings of NAACL 2012. [slides] [see also in software tab]
- Hao Zhang, Liang Huang, Kai Zhao, and Ryan McDonald (2013).
Online Learning with Inexact Hypergraph Search.
- information extraction
- Qi Li, Heng Ji, and Liang Huang (2013).
Joint Event Extraction via Structured Prediction with Global Features.
To appear in Proceedings of ACL 2013.
- Qi Li, Heng Ji, and Liang Huang (2013).
Joint Event Extraction via Structured Prediction with Global Features.
Older Representative Publications (organized by techniques)
- linear-time incremental parsing/translation with dynamic programming
- Liang Huang and Kenji Sagae (2010).
Dynamic Programming for Linear-time Incremental Parsing.
In Proceedings of ACL 2010. [slides] [see also in software tab] [bib]
Nominated for the Best Paper Award. (received unanimous full-score reviews.) - Liang Huang and Haitao Mi (2010).
Efficient Incremental Decoding for Tree-to-String Translation.
In Proceedings of EMNLP 2010. [slides] [bib] - Ashish Vaswani, Haitao Mi, Liang Huang and David Chiang (2011).
Rule Markov Models for Fast Tree-to-String Translation.
In Proceedings of ACL 2011. [slides by ashish] [bib]
- Liang Huang and Kenji Sagae (2010).
Dynamic Programming for Linear-time Incremental Parsing.
- forest and hypergraphs, exact and approximate k-best dynamic programming (cube pruning)
- Liang Huang and David Chiang (2005).
Better k-best Parsing.
In Proceedings of IWPT 2005. [slides] - Liang Huang and David Chiang (2007).
Forest Rescoring: Faster Decoding with Integrated Language Models.
In Proceedings of ACL 2007. [slides]
Nominated for the Best Paper Award. - Liang Huang (2008).
Forest Reranking: Discriminative Parsing with Non-Local Features.
In Proceedings of ACL 2008. [slides]
Received the Best Paper Award [link]. (received unanimous full-score reviews)
Recognized in ACL 2012 as the most-cited paper published in 2008 within the ACL Anthology.
- Liang Huang and David Chiang (2005).
Better k-best Parsing.
- syntax-directed translation and its forest-based extensions
- Liang Huang, Kevin Knight, and Aravind Joshi (2006).
Statistical Syntax-Directed Translation with Extended Domain of Locality.
In Proceedings of AMTA 2006. [slides] - Haitao Mi, Liang Huang, and Qun Liu (2008).
Forest-based Translation.
In Proceedings of ACL 2008. [slides] - Haitao Mi and Liang Huang (2008).
Forest-based Translation Rule Extraction.
In Proceedings of EMNLP 2008. [slides]
Nominated for the Best Paper Award. (received unanimous full-score reviews).
- Liang Huang, Kevin Knight, and Aravind Joshi (2006).
Statistical Syntax-Directed Translation with Extended Domain of Locality.
- binarization of synchronous grammars.
- Liang Huang, Hao Zhang, Daniel Gildea, and Kevin Knight (2009).
Binarization of Synchronous Context-Free Grammars.
Computational Linguistics, 35 (4). Conference version appeared at NAACL 2006.
(The core linear-time synchronous binarization algorithm was inspired by the Graham Scan for Convex Hull. It was a rather unexpected connection.)
[slides]
- Liang Huang, Hao Zhang, Daniel Gildea, and Kevin Knight (2009).
Binarization of Synchronous Context-Free Grammars.
- grammars and dynamic programming for computational biology
-
Adam Lucas, Liang Huang, Aravind Joshi, and Ken Dill (2007). Statistical Mechanics of Helix Bundles using a Dynamic Programming Approach.
J. Am. Chem. Soc. (JACS), 129 (14), pp. 4272-4281.
- Ken Dill, Adam Lucas, Julia Hockenmaier, Liang Huang, David Chiang, and Aravind Joshi (2007). Computational Linguistics: a new tool for exploring biopolymer structures and statistical mechanics. Polymer, 48 (15), pp. 4289-4300.
-
Adam Lucas, Liang Huang, Aravind Joshi, and Ken Dill (2007). Statistical Mechanics of Helix Bundles using a Dynamic Programming Approach.
J. Am. Chem. Soc. (JACS), 129 (14), pp. 4272-4281.
For a more complete list you can visit my google scholar page (or by year). Some time in the future I will compile a real publication list, but for the time-being please use google scholar. You can also use Semantic Scholar (by AI2) to see the influences of my work.
Some lesser-known work:
 K-best Knuth Algorithm.
Tech Report, 2005.
K-best Knuth Algorithm.
Tech Report, 2005.This brief note develops a k-best extension of the powerful Knuth (1977) algorithm, which itself extends the classical Dijkstra (1959) shortest-path from graphs to directed hypergraphs (AND-OR graphs) and context-free grammars. My extension was quite straightforward, following a simple k-best Dijkstra extension by Mohri and Riley (2002), combined with the lazy k-best frontier idea from my k-best CKY parsing work (Huang and Chiang, 2005). I thought this algorithm was only of theoretical interest, and was surprised (and glad) when Pauls and Klein (2009) further developed it to "k-best A* parsing" by adding admissible heuristics, which won the ACL 2009 Best Paper Award.
See also [3] below on the relationship between A*, Knuth, and Dijkstra.
As a side note, the k-best parsing algorithms (Huang and Chiang, 2005) were used in the award winning papers in ACL 2005, NAACL 2006, ACL 2008, and ACL 2009.
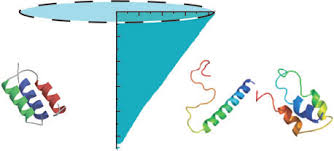 Statistical Mechanics of Helix Bundles using a Dynamic Programming Approach,
with Adam Lucas, Aravind Joshi, and Ken Dill.
Statistical Mechanics of Helix Bundles using a Dynamic Programming Approach,
with Adam Lucas, Aravind Joshi, and Ken Dill.
J. Am. Chem. Soc. (JACS), 129 (14), pp. 4272-4281.I used to work on computational biology during my PhD, which resulted in this paper. Although published in the top chemistry journal, it does not get much attention at all, which I believe was due to the difficulty of the technique (dynamic programming) for a chemistry audience (a computational biology audience would have been much better -- they use DP a lot, e.g. Smith-Waterman is edit-distance; even CKY is widely used in comp-bio). (more DP details such as function operators left to the Supplement).
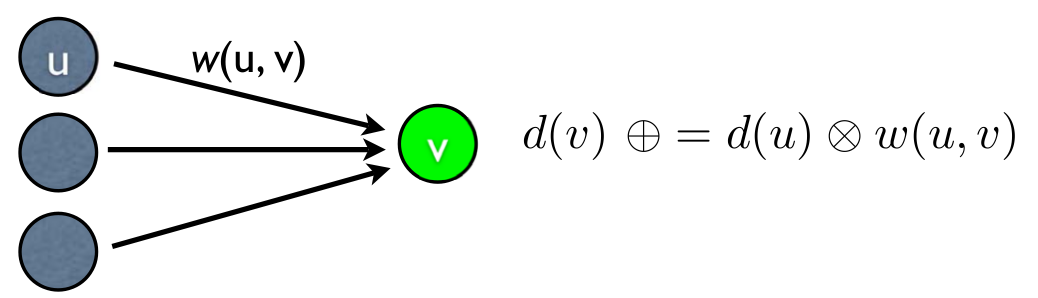 Tutorial: Advanced Dynamic Programming in Semiring and Hypergraph Frameworks.
Tutorial: Advanced Dynamic Programming in Semiring and Hypergraph Frameworks.
NAACL 2009 and COLING 2008. [slides] (based on my candidacy exam and Chapter 2 of my thesis)I present a unified algebraic theory of dynamic programming based on monotonic weight functions, semirings (distributivity implies monotonicity), and hypergraphs (distributivity is the key to factorization). Here DP includes both Viterbi-style (topological order, requires acyclicity of the graph) and Dijkstra-style (best-first, requires superiority of the semiring); also DP includes both optimization (using idempotent semirings) and summation/expection (using inside/expectation semirings). This view of DP is much broader than those in the textbooks. The only implementation paradigm not covered in my framework is "memoized top-down recursion", which, as the CLRS book also pointed out (Sec. 15.1), could also be viewed as the DFS version of topological sort (whereas Viterbi, or bottom-up, resembles a BFS version of topological sort). A* search on graphs and hypergraphs (e.g. A* parsing) are also discussed as generalizations of Dijkstra 1959 and Knuth 1977.
It was the most popular tutorial in both COLING 08 and NAACL 09.
 The Art of Algorithms and Programming Contests, with Rujia Liu.
The Art of Algorithms and Programming Contests, with Rujia Liu.
Tsinghua University Press, 2003. Baidu Baike entry (in Chinese). National Best Seller in CS.We wrote this book in college while I was training alongside the SJTU team which won the World Champions for the first time. When it was first published I had just come to the States and was no longer active in the programming contest community, so I had no clue that it would become a best-seller in the field of programming contests (I initially thought it would only sell about a thousand copies). I wrote one of the three chapters of the book, the one on computational geometry, my second favorite topic in algorithms after dynamic programming.
After many years of hiatus, I finally resumed contest coaching, at USC (encouraged by David Kempe) and later at CUNY (encouraged by Jerry Waxman), helping the former win its first Southern California Regionals in 2011 (and again in 2012), and helping the latter achieve its best ranking in Greater New York Regionals in 10 years. I developed a course in CUNY to train for ACM/ICPC (and also for job interviews as a by-product), which became students' favorite class in the CS Dept. I hope to write a new book based on the course notes (with Python code for each problem). I really think ACM/ICPC should allow Python in all Regionals and the World Finals (many Regionals in the US already support Python, including my current region, the Pacific Northwest). I also advocate for more algorithmic problems in the Regionals (esp. in the US), and more geometry problems in the Finals.

Current teaching at Oregon State: [lightboard teaching videos] [algorithms book]
- Spring 2026: AI 100, AI for Everyone Canvas Ed Registra
- Spring 2026: CS 514, Algorithms (graduate) (66 students)
- Winter 2026: AI 100, AI for Everyone
- Fall 2025: AI 534, Machine Learning (e-campus) (140 students)
- Spring 2025: CS 514, Algorithms (graduate) (65 students)
- Fall 2024: AI 534, Machine Learning (e-campus) (105 students)
- Spring 2024: CS 325, Algorithms (110 students)
- Spring 2024: CS 514, Algorithms (graduate) (75 students)
- Fall 2023: AI 534, Machine Learning (e-campus) (75 students)
- Spring 2023: CS 325, Algorithms (95 students)
- Fall 2022: CS 514, Algorithms (70 students)
- Fall 2022: AI 539, Natural Language Processing
- Spring 2022: CS 513, Applied Machine Learning (e-campus)
- Spring 2021: CS 519, Applied Machine Learning (e-campus)
- Spring 2020: CS 519, Applied Machine Learning (e-campus)
- Fall 2019: CS 325, Algorithms (150 students)
- Fall 2019: CS 539, Natural Language Processing
- Spring 2019: CS 519, Applied Machine Learning (e-campus)
- Spring 2018: CS 519, Applied Machine Learning (e-campus)
- Winter 2018: CS 519, Algorithms (MS/MEng-level)
- Fall 2017: CS 534, Machine Learning (75 students)
- Spring 2017: CS 519, Natural Language Processing (34 students)
- Fall 2016: CS 519, Algorithms (MS/MEng-level) (51 students)
- Spring 2016: CS 519, Scientific Writing and Presentation (31 students)
- Winter 2016: CS 480, Translators (Compilers) (75 studens)
- Fall 2015: CS 321, Theory of Computation (136 students)
Past Teaching at CUNY:
- Fall 2014: CS 71010, Programming Languages, Graduate Center.
- Fall 2014: LING 83600/CS 84010, Natural Language Processing, Graduate Center.
- Fall 2014: CS 3813/780, Advanced Programming, Queens College.
- Spring 2014: CS 3813/780, Advanced Programming (new course, training for programming contests and job interviews), Queens College.
- Fall 2013: CS 71010, Programming Languages, Graduate Center.
Modeled after: CIS 500, Fall 2003 at Penn (by B. Pierce, the best instructor I've ever had). - Fall 2013: CS 87100, Scientific Writing and Presentation (new course), Graduate Center.
- Spring 2013: CS 84010, Machine Learning (A Geometric Approach), Graduate Center.
- Spring 2013: LING 83600/CS 84010, Natural Language Processing, Graduate Center.
- Fall 2012: CS 3813/780, Python Programming, Queens College.
Past Teaching at USC:
- Spring 2012: CS 570, Analysis of Algorithms.
- Spring 2012: CS 561, Artificial Intelligence (in Prolog), with Kenji Sagae.
- Fall 2011: CS 562, Statistical Natural Language Processing, with David Chiang.
- Spring 2011: CS 599, Machine Translation (new course), with David Chiang and Kevin Knight.
- Fall 2010: CS 562, Statistical Natural Language Processing, with Kevin Knight.
- Spring 2010: CS 544, Natural Language Processing (with Hovy, Hobbs, and Kozareva).
- Fall 2009: CS 562, Statistical Natural Language Processing, with David Chiang.
- Nominated for the Viterbi Engineering School Teaching Prize, 2012.
Past Teaching at Penn:
- CSE 399: Python Programming (new course, Spring 2006)
Chosen by the Department to be the first graduate student ever to teach a course. - Recitation Instructor, CSE 320, Algorithms (Spring 2005, Prof. Sanjeev Khannna)
- Recitation Instructor, CSE 262, Automata and Formal Language Theory (Fall 2004, Prof. Jean Gallier).
- Awarded University Graduate Teaching Prize, 2005.
[more details]
I am very fortunate to have been working with the following students:
- PhD Students:
- Zetian Wu, BS, Physics, ZJU; MS, DS, JHU. Joined Fall 2022. Working on sign language translation.
- Milan Gautam, BS, ECE, Nepal. Joined Winter 2024. Working on RNA design.
- Feipeng Yue, BS, CS, Dalian U. of Technology. MS, OSU. Joined Winter 2025. Working on mRNA design.
- Bowen Xie, BS, CS, UESTC. Joined Winter 2026. Working on RNA design.
- JasonFred Ngwa, BS, Biochemistry and BS, CS, Clarkson U. To join in Fall 2026.
- MS Students:
- Apoorv Malik. Joined Winter 2023.
- Undergraduate Students:
ACL Group Alumni:
- PhD Graduates (12):
- (#12, OSU, 2026, compbio+NLP) Ning Dai, BS, CS, Fudan. Interned at Tencent AI Lab and Bytedance AI Lab. Defended June 2026.
- (#11, OSU, 2026, compbio) Tianshuo Zhou, BS, Civil, Southeast; MS, CS, Nanjing. Worked at Bytedance. Joined Summer 2022. Defended Jan 2026. First-author papers: 2 ISMB + 2 RECOMB.
- (#10, OSU, 2022, NLP) Junkun Chen, BS, CS, Central South; MS, CS, Fudan. Interned at Bytedance AI Lab. Joined Fall 2019. Defended Dec. 2012. Best Demo Paper Award, NAACL 2022. First job: Sr. Applied Scientist, Microsoft Research.
- (#9, OSU, 2022, compbio) Sizhen Li, BS, EE, MS, CS, BUPT. Interned at Bytedance AI Lab and Baidu Research USA. Joined Fall 2019. Defended Nov. 2022. Published the first PNAS paper in the history of OSU College of Engineering. First job: Research Scientist, Sanofi. (de facto co-advisor: Prof. David Mathews of Rochester).
- (#8, OSU, 2022, compbio+NLP) Juneki Hong (co-advised by David Hendrix), BS, CS, JHU; MS, CS, CMU. Joined Fall 2016. Defended June 2022. First job: NLP Algorithm Engineer, Bytedance.
- (#7, OSU, 2022, compbio) Liang Zhang, BS, EE, Nankai; MS, EE, HKUST; MS, Finance, LBS. Joined Spring 2019. Defended May 2022.
- (#6, OSU, 2021, compbio) He Zhang, BS/MS, Beihang. MS, OSU, 2018. Returned to PhD program, 2020. Defended Sep. 2021. First job: Research Scientist at Baidu Research USA. (de facto co-advisor: Prof. David Mathews of Rochester).
- (#5, OSU, 2020, NLP) Renjie Zheng, BS/MS, CS, Tongji. Joined ACL Group in Fall 2017 (officially Winter 2018). Interned at Fudan University and Baidu Research. Defended Mar. 2020. First job: Research Scientist at Baidu Research USA.
- (#4, OSU, 2018, NLP) Mingbo Ma, BS, EE, Jilin. Joined ACL Group in 2013. Interned at IBM TJ Watson, Apple, and Baidu Research. Defended Sep. 2018. First job: Research Scientist at Baidu Research USA. Now Tech Lead Manager, Tiktok.
- (#3, OSU, 2017, NLP) Kai Zhao, BS, CS, USTC. Joined ACL Group in 2012. Interned at IBM TJ Watson, MSR, and Google Research. 11 ACL/EMNLP/NAACL papers. Defended May 2017. First job: Research Scientist at Google (NYC).
- (#2, OSU, 2016, NLP) James Cross, BA, French and BS, CS, Auburn; JD, NYU. Member of NY Bar. Interned at IBM TJ Watson and Facebook. Best Paper Honorable Mention at EMNLP 2016. Thesis defended Dec. 2016. First job: Research Scientist at Facebook AI (now FAIR).
- (#1, USC, 2014, NLP) Ashish Vaswani (co-advised by David Chiang). Interned at IBM TJ Watson and Google Research. Thesis defended May 2014. First job: Research scientist at USC/ISI. Current job: Senior Research Scientist at Google Brain. First author of the attention is all you need paper.
- Postdocs (2)
- (#2, CUNY) Feifei Zhai (Ph.D., CAS/IA), postdoc, 2014--2015. First job: research staff member at IBM TJ Watson.
- (#1, CUNY) Lemao Liu (Ph.D., Harbin), postdoc, 2013--2014. First job: researcher at NICT, Nara, Japan.
- MS Thesis Graduates (4)
- Matthew Meyn, BS, Music, Santa Clara; BS, CS, OSU (e-campus). Defended CS MS Thesis, June 2019.
- He Zhang, BS/MS, EE, Beihang. Defeneded CS MS thesis, Sep 2018. First job: Research Engineer at Baidu Research USA.
- Kaibo Liu, BS, Physics, PKU; MS, EE, PKU. Defended CS MS thesis, Dec 2018. First job: Research Engineer at Baidu Research USA.
- Luyao Zhang, BS, ZJU; PhD, USC. Defended CS MS thesis, Sep 2016. First job: CS Lecturer, Oregon State.
- Undergraduates (partial list)
- Wei Yu Tang. Double major in Math and CS with 4.0 GPA. Started USC QCB PhD in Fall 2024. Published first author paper in Nature Communications.
- Otso Barron. Captain, Oregon State ACM/ICPC teams. President, ACM Student Chapter. Started CMU CSD PhD in Fall 2025 (first from Oregon State).
My past summer interns include Sasha Rush (Ph.D., MIT, now Prof. at Harvard), Yoav Goldberg (Ph.D., Ben Gurion, now Prof. at Bar Ilan), Heng Yu (Ph.D., CAS/ICT, now with Samsung), and Zhuoran Yu (M.S., NYU, now with Google NYC's NLP research team).
To prospective students: please use csrankings.org for a data-driven and more up-to-date CS ranking than the purely subjective and totally obsolete US News system. If you look at the past ten years (2007--2017), we are ranked 15th in NLP (mostly our group), 18th in vision, 21st in narrow AI (AAAI/IJCAI), and 20th in broad AI. So the AI group is super strong. Other strong groups include Software Engineering (11th), Crypto (15th), and HCI (23rd). The overall CS ranking is 36th and is improving.
CV [Apr. 2024]
Education
Ph.D., Computer Science, University of Pennsylvania, 2008.
B.S., Computer Science, Shanghai Jiao Tong University, 2003. summa cum laude. (minor studies in French and English)
Professional Experience
Professor (by courtesy) of Biochemistry/Biophysics, College of Science, Oregon State University, 2024/1--present.
Professor of Computer Science, School of EECS, Oregon State University, 2023/9--present. (Assoc. Prof., 2020--2023; Asst. Prof., 2015--2020)
Distinguished Scientist and Head, Institute of Deep Learning USA, Baidu Research USA, 2018/6--2019/3 and 2021/9--2020/3 and various part-time periods in between (on leave from OSU).
Research Scientist (part-time), IBM Watson Group, 2014/6--2017/1.
Assistant Professor, Queens College and Graduate Center, City University of New York (CUNY), 2012/8--2015/8.
Research Assistant Professor, University of Southern California (USC) and Information Sciences Institute (ISI), 2009/7--2012/8.
Research Scientist, Google Research (Mountain View), 2009/1--7.
Visiting Scholar, Hong Kong Univ. of Science and Technology, 2008/10--2008/11.
Visiting Scholar, Institute of Computing Technologies, Chinese Academy of Sciences, 2007/10--2008/1.
Summer Intern, USC/ISI, 2005/5--10 and 2006/5--10.
Awards / Honors
Best Demo Paper Award, NAACL 2022.
Keynote, iRNA (Integrative RNA Biology) COSI, ISMB 2021
Invited Talk, CVPR 2021
Keynote, ACL 2019 (first ACL keynote by a Chinese NLP researcher)
Best Paper Finalist, SIGMOD 2018.
Best Paper Honorable Mention, EMNLP 2016 (Cross and Huang, 2016).
Best Paper Finalist, EMNLP 2008 (Mi and Huang, 2008)
Best Paper Finalist, ACL 2010 (Huang and Sagae, 2010).
Best Paper Award, ACL 2008 (Huang, 2008).
(one of the four single-author best paper awards in ACL history.)
Best Paper Finalist, ACL 2007 (Huang and Chiang, 2007)
Google Faculty Research Award, 2010.
Google Faculty Research Award, 2013.
Yahoo! Faculty Research and Engagement Award, 2015.
Regional Champions (as Faculty Advisor for USC), ACM Int'l Collegiate Programming Contest (ICPC), 2011.
University Prize for Graduate Student Teaching, University of Pennsylvania, 2005.
[more details]
Selected Service
Action Editor, Transactions of the ACL (TACL), 2021--
NSF Panelist, 2014, 2015, 2017 x 2, 2019 x 2, 2022
Grant Reviewer, Foreign NSFs: Hong Kong (RGC), 2017; Canadian (NSERC), 2017; Dutch (NWO), 2017; Israeli (ISF), 2015
Area Chair (sentence-level semantics), ACL 2019
Area Chair (syntax and parsing), EMNLP 2018
Senior Area Chair (syntax and parsing), ACL 2018
Area Chair (syntax and parsing), IJCNLP 2017
Area Chair (syntax and parsing), EMNLP 2016
Area Chair (machine translation), ACL 2014
Area Chair (syntax and parsing), ACL 2012
Program Co-Chair, IWPT 2013
Textbook Reviewer, Cambridge Univ. Press, 2016, and Oxford Univ. Press, 2010
Brief bio for talk announcements
Liang Huang is a Professor of Computer Science and (by courtesy) Biochemistry/Biophysics at Oregon State University. Until recently he was also a Distinguished Scientist at Baidu Research USA. He received his PhD in 2008 from the University of Pennsylvania. He is best known for his work on efficient algorithms and provable theory in computational linguistics and their applications in computational biology, where several of his algorithms have become textbook standards or have been published in prestigious journals like Nature (2023) and PNAS (2021). His recognitions include ACL 2019 Plenary Keynote, ISMB 2021 Integrative RNA Biology Keynote, CVPR 2021 Invited Talk, ACL 2008 Best Paper Award (sole author), EMNLP 2016 Best Paper Honorable Mention, NAACL 2022 Best Demo Paper Award, several best paper nominations (ACL 2007, EMNLP 2008, ACL 2010, SIGMOD 2018), two Google Faculty Research Awards (2010 and 2013), and a University Teaching Prize at Penn (2005). He also co-authored a best-selling textbook in China on algorithms for programming contests. His work on simultaneous translation and mRNA design has been covered by numerous media reports.
{kind=link}
Linear-Time RNA Folding Toolkits
This whole package of linear-time RNA folding algorithms (GitHub; web server) includes:- LinearFold (ISMB 2019) -- MFE/Viterbi folding
- LinearPartition (ISMB 2020) -- partition function, marginal probabilities, and MEA
- LinearTurboFold (PNAS 2021) -- homologous folding (alternating align and fold)
- LinearSampling (NAR 2022) -- stochastic sampling
LinearDesign: optimal mRNA design
TBASpan-based Parsers
By now, span-based parsing has become the dominant paradigm in neural constituency parsing.- Span-based Neural Constituency Parser (EMNLP 2016 Best Paper Honorable Mention) [Github (James Cross)]
- Linear-Time Span Parser (ACL 2018) [Github (Juneki Hong + me)]
Linear-Time Dynamic Programming Parser (with Max-Violation Perceptron Trainer)
This parser is described in the following two papers:
- Liang Huang and Kenji Sagae (2010).
Dynamic Programming for Linear-Time Incremental Parsing.
Proceedings of ACL 2010. Best Paper Nominee. - Liang Huang, Suphan Fayong, and Yang Guo (2012).
Structured Perceptron with Inexact Search.
Proceedings of NAACL 2012.
- Extremely fast linear-time parsing (about 0.04 seconds per sentence).
- Dynamic programming and forest output (encodes exponentially many trees).
- k-best output (Huang and Chiang, 2005).
Trainer Features:
- Flexibility in defining new feature templates (my Python code compiles your feature definition language into a dynamically generated Python snippet).
- Max-Violation Perceptron Training (Huang et al 2012).
- Parallelized Perceptron Training (McDonald et al 2010).
Download from here.
Download from github repo.
Python Sparse Vector
Written in C as a Python extension module based oncollections.defaultdict.
Much faster and slimmer (4 times less memory usage) than David Chiang's svector.
Builtin support for averaged parameters in online learning (e.g. perceptron, MIRA, etc.).
Note: for decoding (e.g. parsing), defaultdict is fast enough (mine is even faster by doing dot-product in C, which is also possible via Cython), but for learning (e.g. perceptron), defaultdict becomes terrible on big data because Python float/int are immutable, which caused too many unnecessary hash operations. Using my hvector can make your learner up to 5 times faster.
Download: hvector version 1.0 (Jan 2013).
Forest-Reranking Parser
This parser/reranker is described in the following paper:- Liang Huang (2008). Discriminative Parsing with Non-Local Features.
Proceedings of ACL 2008. (Best Paper Award)
errata: Following Charniak, the dev set was section 24, not section 22.
- The forest-dumping version of Charniak parser.
- The forest reranker.
- The perceptron trainer.
Important: If you're using 64-bit Ubuntu, it is recommended that you install Python from source code (see Python.org). The default Python2.7 in those Ubuntus (at least 12.04) has an obscure floating point problem which gives inconsistent results.
Papers which use multiple pieces of my software: there are many papers from other researchers which use a certain piece of my software, but there are also some which combine different pieces together, for example:
- Le and Zuidema (EMNLP 2015), The Forest Convolutional Network: Compositional Distributional Semantics with a Neural Chart and without Binarization, using my dependency parser's forest output, pruned by my forest pruner; quite unexpected -- even I haven't used them together.

 x2
x2

We gratefully acknowledge the support from external funding agencies.
- NSF Molecular Foundations of Biotech (MFB) ($1.5M), PI (co-PI: David Mathews of Rochester), 2024-2027. News Release. MFB is a strategic interdisciplinary initiative between MPS (Chem, Phys, Math), BIO/MCB, CISE/IIS, and ENG/CBET.
- NSF CISE/IIS/RI small, sole PI, 2020-2023. simultaneous translation.
- NSF CISE/IIS/RI small, sole PI, 2018-2021. marrying deep learning with dynamic programming.
- NIH R01, co-I, 2018-. PI: Robert Tanguay.
- Intel, PI, 2018-.
- HP Seedling, PI, 2017.
- DARPA Explanable AI (XAI), co-PI, 2017--2021. PI: Alan Fern.
- Yahoo! Faculty Research and Engagement Award, sole PI, 2015--2016.
- NSF CISE/IIS/RI EAGER, sole PI, 2014--2017.
- Google Faculty Research Award, sole PI, 2013--2014.
- DARPA DEFT, co-PI, 2012--2016. PI: Andrew Rosenberg.
- Google Faculty Research Award, PI, 2010--2011.
- OSU EECS Collaboration Fund, 2016--2017
- PSC-CUNY Enhanced Research Award, 2013--2014
- USC Viterbi School of Engineering Fund, 2011--2012
School of EECS, Oregon State University
1148 Kelley Engineering Center (KEC)
Corvallis, OR 97331
541-737-4694 (o)
liang dot huang dot sh at gmail or liang dot huang at oregonstate dot edu.
Simultaneous Translation

Also covered by two podcasts:

NLP-inspired RNA folding and design for COVID
 ("Remarkable AI tool for mRNA design")
("Remarkable AI tool for mRNA design")
 ("A tool for optimizing mRNA")
("A tool for optimizing mRNA")
Classical Music
I am a big fan of Classical Music. The composers I admire the most are Johann Sebastian Bach (whose music is so mathematical), Peter Ilych Tchaikovsky (whose melodic talent is second only to Mozart), and Antonin Dvorak (whose music blends Bohemia with America). I also love, among others, (in chronological order) Luigi Boccherini, Wolfgang Mozart, Ludwig van Beethoven, Felix Mendelssohn, Giacomo Puccini, and Sergei Rachmaninoff. Yes, I do have a preference for Baroque, Slavic, and melodic beauty ("lyricism").On the other hand, I don't have a taste or much respect for Richard Wagner (whom I found rather disgusting) or Franz Lizst. Compared to Frederic Chopin or Nicolo Paganini, Lizst has almost nothing original to himself (like comparing Clementi to Mozart). I don't like Haydn either: he is innovative in form, but his melodic talent is certainly not comparable to those I love. Even "his" most beautiful work, String Quartet Op. 3 No. 5 that contains the famous 2nd movement Andante Cantabile ("the Serenade") is now firmly attributed to Hoffstettter (an admirer of Haydn). When I first heard that movement without knowing this, I was like, "There is no way Haydn could have written this!" Some people even called Boccherini "Haydn's wife" (in terms of stylistic similiarity); to me that's bullshit -- Boccherini wrote many achingly beautiful themes (such as this and that) that Hadyn could never have written. Brahms, on the other hand, does have superb melodic talent, but he is so reluctant in showing it.
I think the ideal teaching style in computer science
should be something like this "illustrated lecture" below
(passionate, and demo on your instrument (the computer) as much as you can):
A Personal History of Languages
I grew up speaking Wu, but in a multilingual environment. Back in the old days, Shanghai was just as multicultural as New York City today with speakers and communities of all kinds of languages or dialects. When I grew up, my parents spoke Shanghainese, and my grandparents Ningbonese, which I understood but could not speak well; the majority of our neighbors, however, spoke yet another distinctive language called Lower Yangtze Mandarin, which is a "linear interpolation" between Wu and Northern Mandarin, and because of this "interpolation" nature I am still fluent in it today. I started learning Standard Mandarin as a de facto first foreign language in the elementary school, but like most of my peers, I ended up with a heavy southern accent. During college I took up French seriously and got admitted into one of the Grandes Ecoles in Paris, but forgot all of it after moving to the US; those memories somehow all came back when I later took up Spanish and Italian. On the other thand, living in the US helped me get rid of my heavy accent in Mandarin where finally the "training data" around me had more native samples than non-native ones. Living here also exposed me to other Chinese languages and dialects which I never heard back in Shanghai, such as the Upper Yangtze Mandarin (aka "Sichuan"), Cantonese, and Hokkien (aka "Taiwanese"), and more interestingly, various English and Spanish dialects. I still enjoy learning new languages and dialects today.Latin Resources
If you've studied at least one Romance languages (French, Italian, Spanish, Portugues, Romanian, etc.), then Latin shouldn't be too hard. Studying Latin has many benefits, but to me the sound changes in Latin and descendant languages really helped me understand more about Indo-European. Just the hard-vs-soft "c" alone tells you so much about Indo-European history, Centum vs. Satem split, etc. Here is a great guide on Latin pronunciation written by a fellow computational linguist Michael Covington (yes, you probably knew him for the "Convington algorithm", an O(n^2) algorithm for dependency parsing).Enjoy some beautiful music in Latin (Operatic Pop or Catholic):
My interests in Latin were, once again, influenced by David Chiang.
What to do when stuck in traffic jam...
Well, driving in LA is like hell, so my former colleagues at ISI had developed various ways of doing something useful while stuck on the freeways. The NLP group at ISI, being a set of language lovers, is particularly fond of listening to the Pimsleur language programs while driving (someone even got a ticket!), which is arguably the best language learning tool, and I myself did it for Spanish which worked out great. However, Pimsleur doesn't work that well for Japanese and much worse for Chinese where the writing systems are (partially or completely) not phonetic which means you do have to read on the page. You might be able to do some simple Japanese conversations with Pimsleur, but reading kanas and kanjis requires different training; Chinese is much worse which made Pimsleur basically useless even for basic conversations because of homonyms and tones (Jon May used to complain about similar-sounding words such as yiyue "January", yiyuan "hospital", and yinyue "music"; the tones are also different but most westerners can't perceive it). In the same logic, Pimsleur works the best for Italian and Spanish, where the spellings are the most regular (phonemic orthography). Jason Riesa did it for Persian (among the many languages he studied) and claimed it to be really easy partly because it's a well-behaved Indo-European (which makes sense).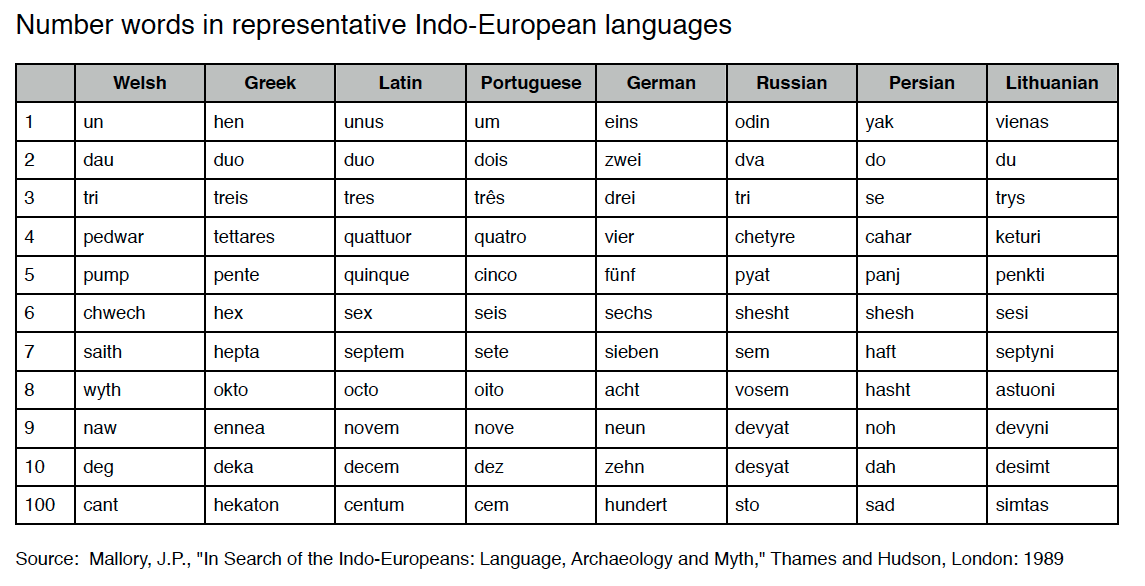{kind=link}
Besides Pimsleur, I also listened to a great many The Teaching Company courses while driving, which has a large catelog of courses in all subjects, and they made it in a way that you can get much of it just by listening (which you can do while cooking, jogging, etc) although they also have videos if you wanna study more carefully. The two professors I recommend the most are Robert Greenberg of UC Berkeley for classical music and music theory, and John McWhorter of Columbia for linguistics.
Both Pimsleur and Teaching Company CDs are extremely expensive, but you can borrow them from local libraries.
Coursera Courses
For English-language courses, I liked this one in particular: Buddhism and Modern Psychology, by Robert Wright of Princeton, and all courses by Curtis (String Quartet, Beethoven Piano Sonatas, and Western Music History).For Chinese-language courses, I am deeply moved by the two from Lu, Shih-Hao of National Taiwan University: Shiji, and Qin Shi Huang. I wish he could offer more online and I think Taiwanese students are so lucky to be able to sit in his classrooms; compared to those in Taiwan, many history/humanities professors in the mainland are just a joke (except a handful of real scholars, such as Gao, Hua who wrote How did the Red Sun Rise). For those learning algorithms and programming, the one by PKU is recommended; Liu Jiaying is a real fun teacher.
History of Science
As you can tell I am most interested in historical things: historical geography, historical linguistics, and history of science and mathematics. Here is my old collection on aesthetics of mathematics (essays by C.N. Yang, M. Atiyah, T. Gowers, A. Connes, and T. Tao) and a special subcollection on Paul Erdos.Michael Atiyah on the Art of Mathematics and interview video.
I highly recommend the two documentaries by the Hungarian-American George Csicsery on legendary mathematicians: N is a Number on Paul Erdos, and Counting from Infinity on Yitang Zhang. In the Erdos film, many scenes were shot on the Penn campus (the Math/Physics building DRL in particular) as he visited Prof. Herbert Wilf frequently. In the Yitang film, I love the way he speaks, with a heavy but cute Shanghainese accent, even though he moved to Beijing when he was 13. He is my model as a pure scholar (who does not need recognition or funding) and a dedicated teacher.
Aravind Joshi's Legacy in Computational Biology
Talk Shows
People that I learned the most from
So far I have been extremely grateful to these people from whom I learned a great deal of:- David Chiang
- Dan Gildea
- Kevin Knight
- David Mathews
- Ryan McDonald
- Fernando Pereira
- Qun Liu
- Benjamin Pierce
- Shang-Hua Teng
Policitians that I despise the most
- Winston Churchill
- Margaret Thatcher
- Ronald Reagon