| RECENT
RESEARCH TOPICS |
|
End-to-End Action Segmentation Transformer
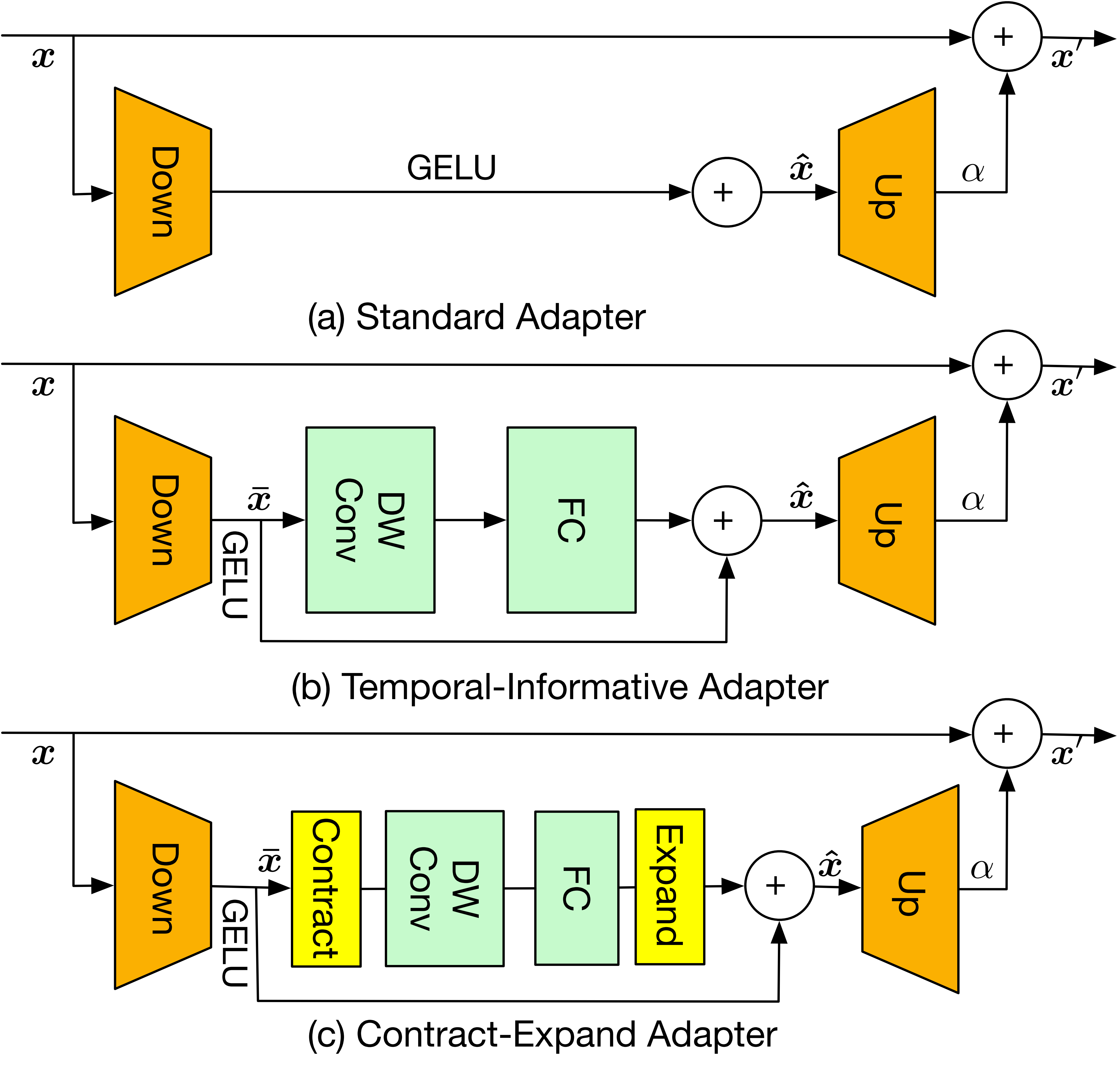
|
Prior work typically uses pre-computed frame features. We introduce the first end-to-end solution to action segmentation grounded on raw pixels with the following key contributions: (1) adapter network for backbone fine-tuning; (2) a segmentation-by-detection framework for leveraging action proposals predicted over a coarsely downsampled video; and (3) action-proposal based data augmentation for robust training.
|
|
|
Difformer for Action Segmentation

|
We explicitly model uncertainty over framewise class predictions using the Dirichlet distribution to recalibrate initially predicted frame-level class distributions through a Dirichlet diffusion process. Our formulation is analytically tractable (closed-form) and hence computationally efficient. Diffusion parameters are estimated only at a sparse set of keyframes using a lightweight module, further reducing memory and runtime costs.
|
|
|
A Dataset for Semantic and Instance Segmentation of Modern Fruit Orchards


|
We introduce the first large-scale dataset for semantic and instance segmentation of fruit trees and their branches. The dataset consists of both synthetic and real-world video data, along with synthetic tree meshes, and provides annotations of foreground instances belonging to three classes: spur, branch, and leader. The dataset is benchmarked for unsupervised domain adaptation from synthetic to real data, and fully supervised learning.
|
|
|
Attention Decomposition for Cross-Domain
Semantic Segmentation

|
We address cross-domain semantic segmentation with a new transformer that reduces the gap between the source and target domains by decomposing cross-attention in the decoder into domain-independent and domain-specific parts. This enforces the query tokens to interact with domain-independent aspects of the image tokens, shared by the source and target domains, rather than domain-specific counterparts which induce the domain gap.
|
|
|
Markov Game Video Augmentation for Action Segmentation
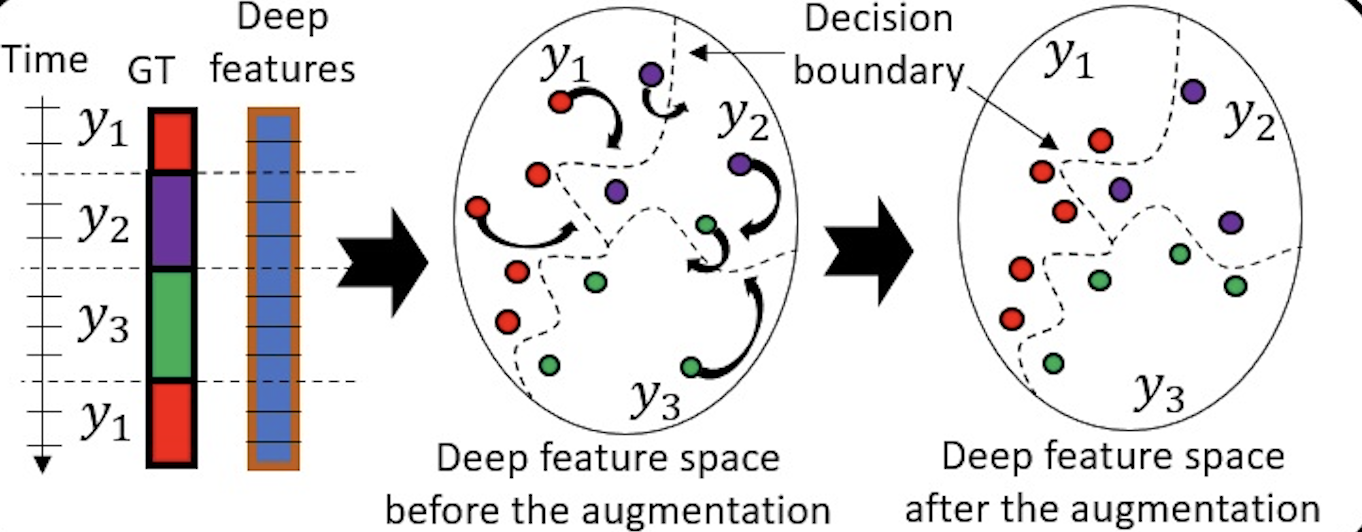
|
For training, we use reinforcement learning (RL) to augment videos in the deep feature space rather than the visual spatiotemporal domain. RL is suitable since there are no reliable oracles to supervise optimal data augmentation in the deep feature space.
|
|
|
Cross-Domain Object Detection with Transformers
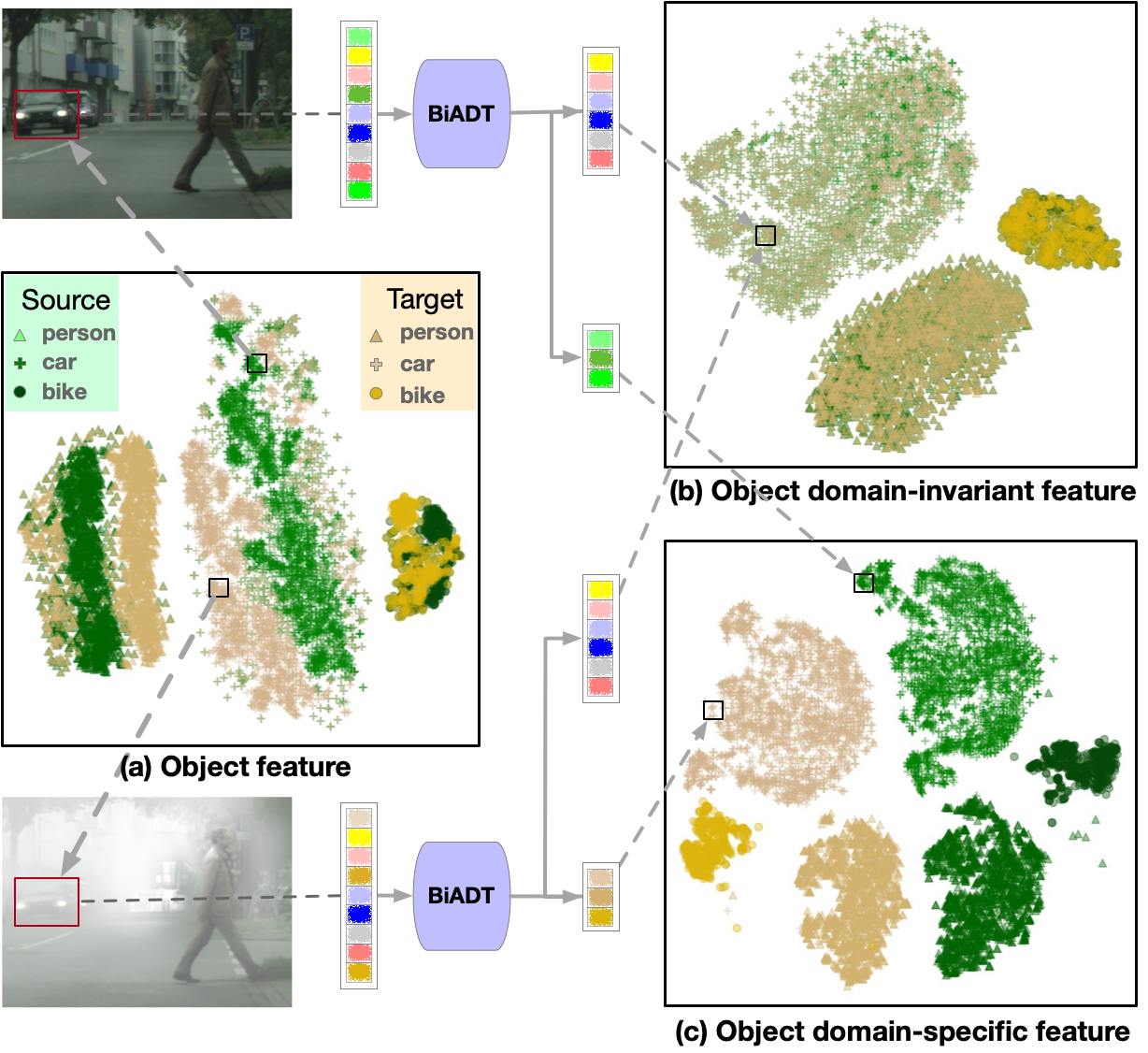
|
We explicitly estimate domain-invariant and domain-specific features in the image-token and object-token sequences for bi-directional alignment of the source and target domains. This is aimed at reducing the domain gap in domain-invariant representations, while simultaneously increasing the distinctiveness of domain-specific features.
|
|
|
Object Detection with Split Transformer
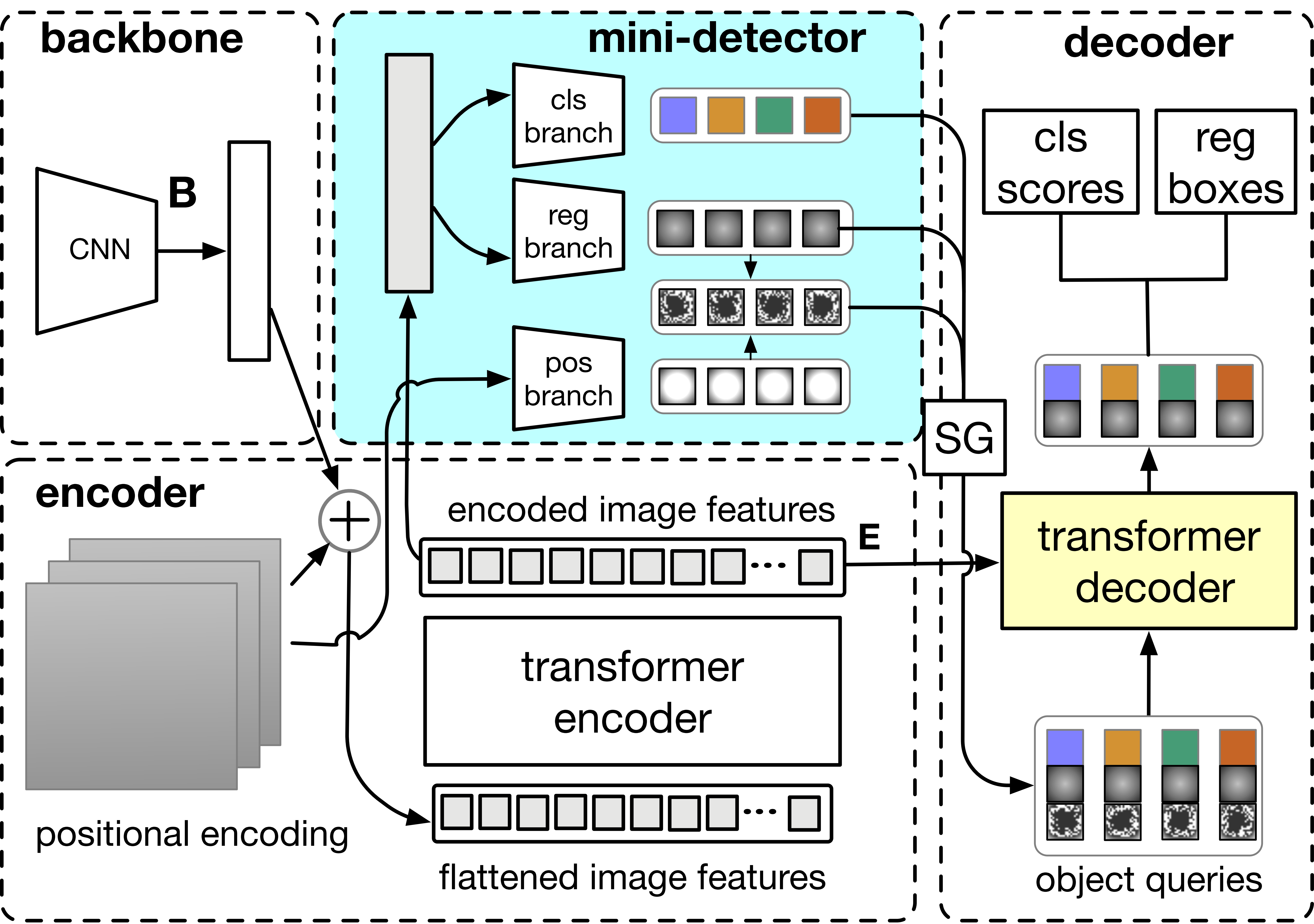
|
Self- and cross-attention in Transformers provide for high model capacity for object detection. We propose to split cross-attention into classification attention and box-regression attention, and also enable self-attention to account for pairs of adjacent object queries.
|
|
|
Incremental Few-shot Instance Segmentation

|
We address incremental few-shot instance segmentation, where a few examples of new object classes arrive after access to training examples of old classes is not available anymore, and the goal is to perform well on both old and new classes. A new classifier based on the probit function and an uncertainty-guided bounding-box predictor are specified.
|
|
|
Weakly Supervised Amodal Segmentation

|
We want to segment both visible (modal) and occluded (amodal) object parts, while training provides only ground-truth modal segmentations. A data manipulation is used to generate occlusions in training images, and predicted amodal segmentations of the manipulated training data are used as the pseudo-ground-truth amodal segmentation masks for the standard training of Mask-RCNN. An uncertainty map is estimated for each prediction for regularizing learning such that lower segmentation loss is incurred on regions with high uncertainty.
|
|
|
FAPIS: A Few-shot Anchor-free Part-based Instance Segmenter

|
In few-shot instance segmentation, training and test images do not share the same object classes.
We explicitly model latent object parts shared across training classes, which facilitates our few-shot learning on new classes in testing.
A new network is specified for delineating and weighting
latent parts by their importance for instance segmentation.
|
|
|
Action Shuffle for Unsupervised Action Segmentation
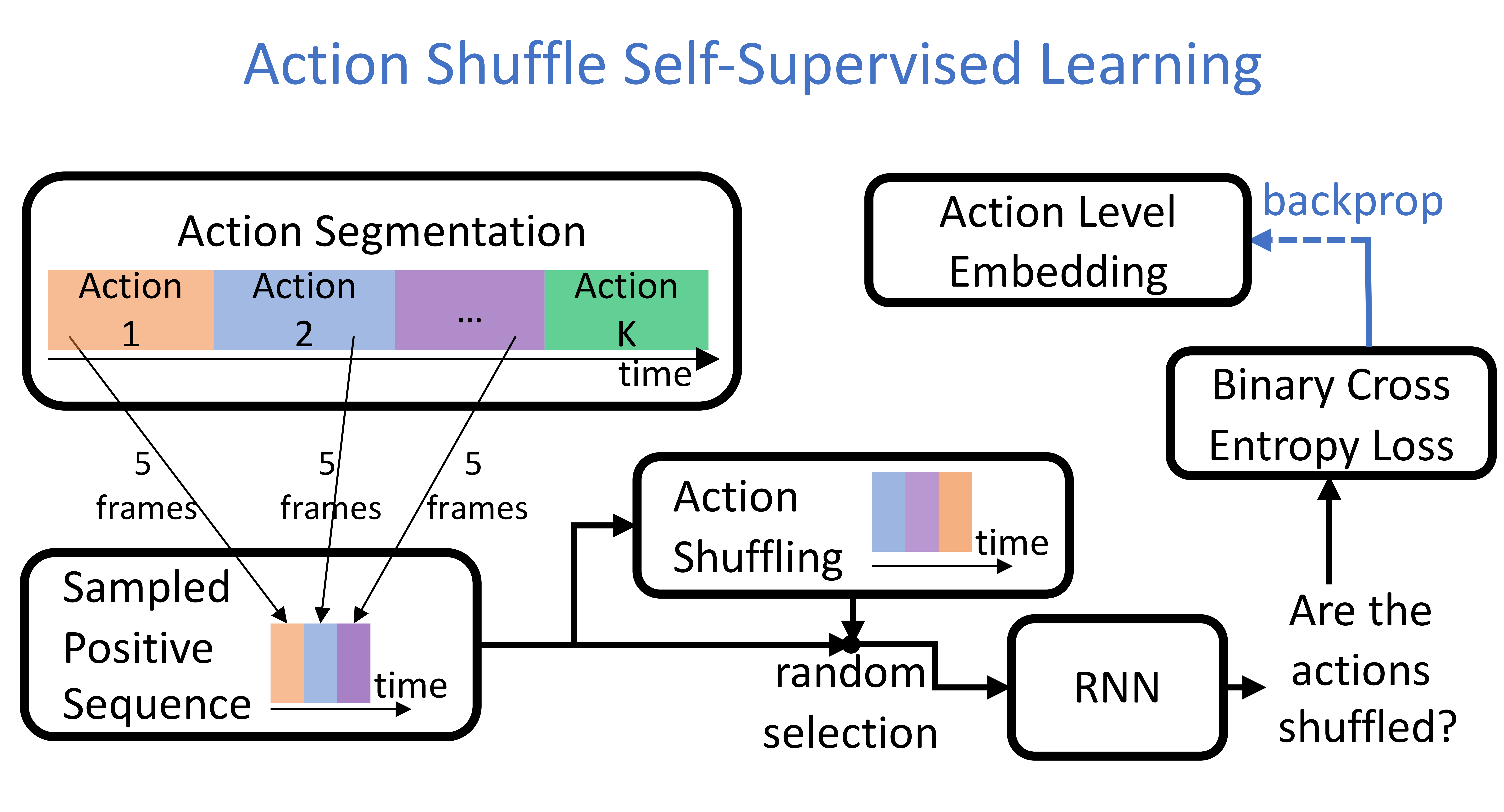
|
We specify a new self-supervised learning of a feature embedding
that accounts for both frame- and action-level structure of videos.
An RNN is trained to recognize shuffled and unshuffled action sequences.
As supervision of actions is not available,
we specify an HMM
and infer a MAP action segmentation for our self-supervised learning.
|
|
|
Anchor-Constrained Viterbi for Set-Supervised Action Segmentation
|
We address set-supervised action segmentation with a new anchor-constrained Viterbi algorithm (ACV).
The Viterbi algorithm is constrained by anchors which are salient action parts
estimated for each action.
|
|
|
Self-Supervised GAN for Unsupervised Few-shot Object
Recognition
|
We are given one large
dataset of unlabeled images, and another
smaller dataset in which we conduct
image retrieval for given queries. The
two datasets do not share object
classes. We specify a new
self-supervised learning for a GAN that
reconstructs the randomly sampled latent
codes of ``fake'' images.
|
|
|
Set-Supervised
Action Segmentation
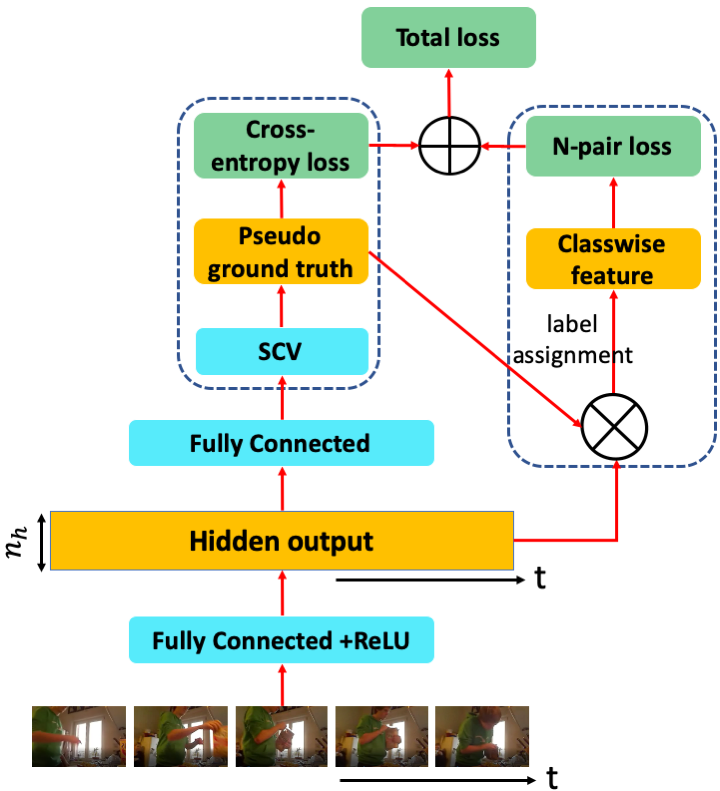
|
Training videos provide only
the ground-truth set of actions present,
but not their temporal ordering. In
training, we estimate a set-constrained
Viterbi loss from a MAP inference of an
HMM which accounts for co-occurrences
and temporal lengths of actions.
|
|
|
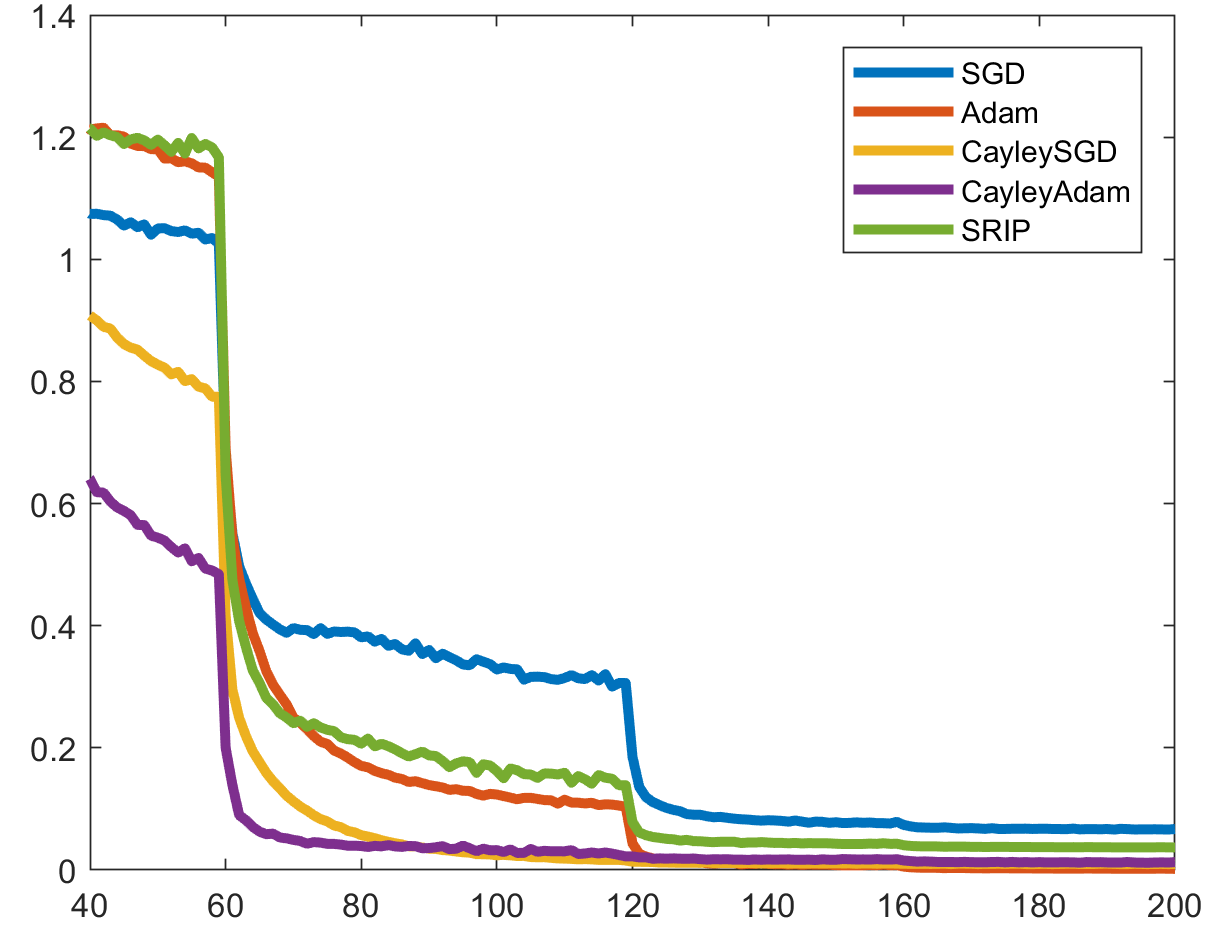
Riemannian
Optimization on the Stiefel Manifold
|
Enforcing orthonormality on
parameter matrices (e.g., of a deep
neural network) amounts to Riemannian
optimization on the Stiefel manifold. To
this end, we specify a new retraction
map based on the Cayley transform, and
implicit vector transport based on a
projection of the momentum and the
Cayley transform on the Stiefel
manifold.
|
|
|
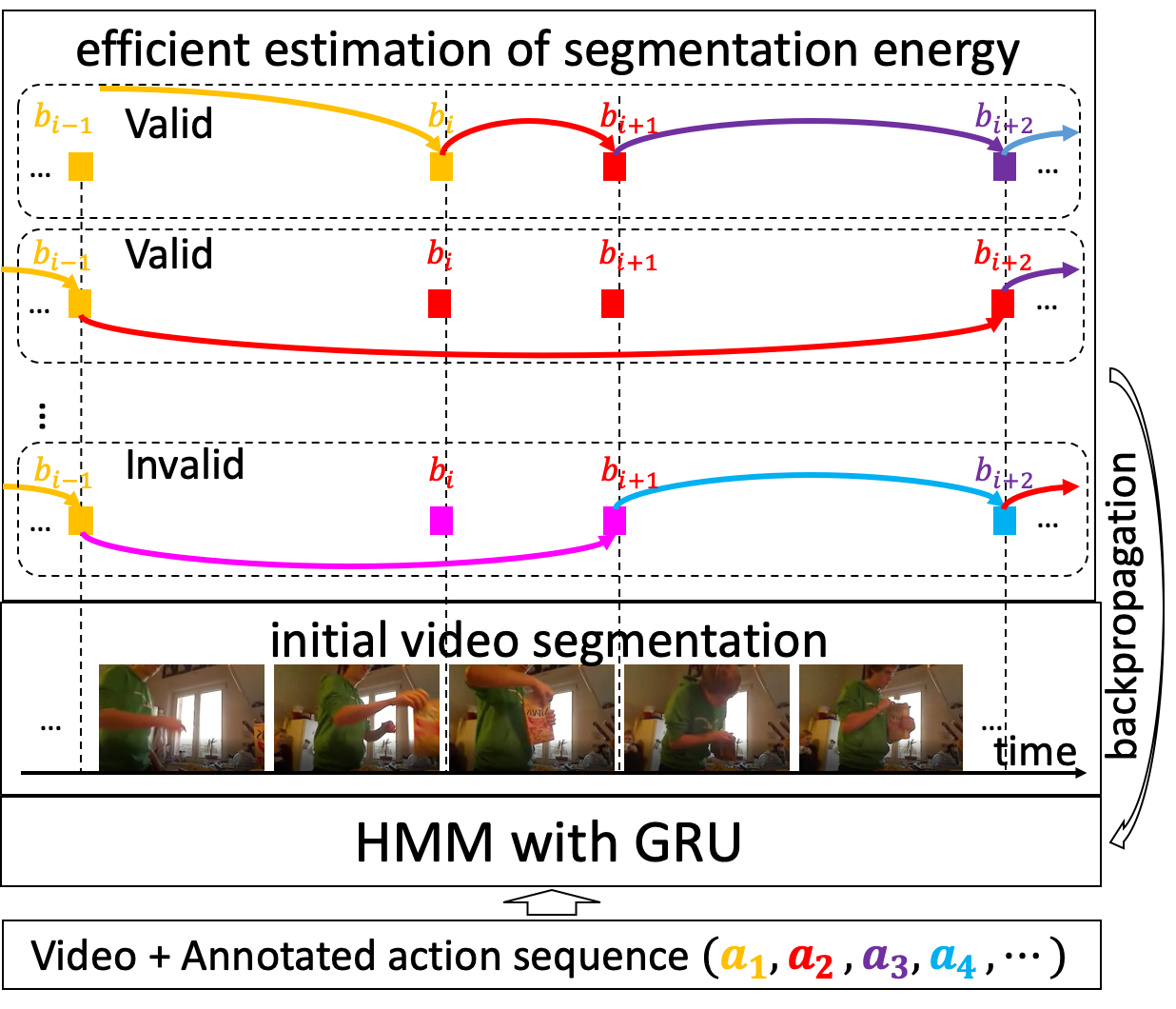
Weakly
Supervised Action Segmentation
|
Training videos provide only
the ground-truth ordering of actions
present. For learning, we specify an
efficient recursive algorithm for
computing an energy-based loss that
discriminates between all valid and
invalid video segmentations.
|
|
|
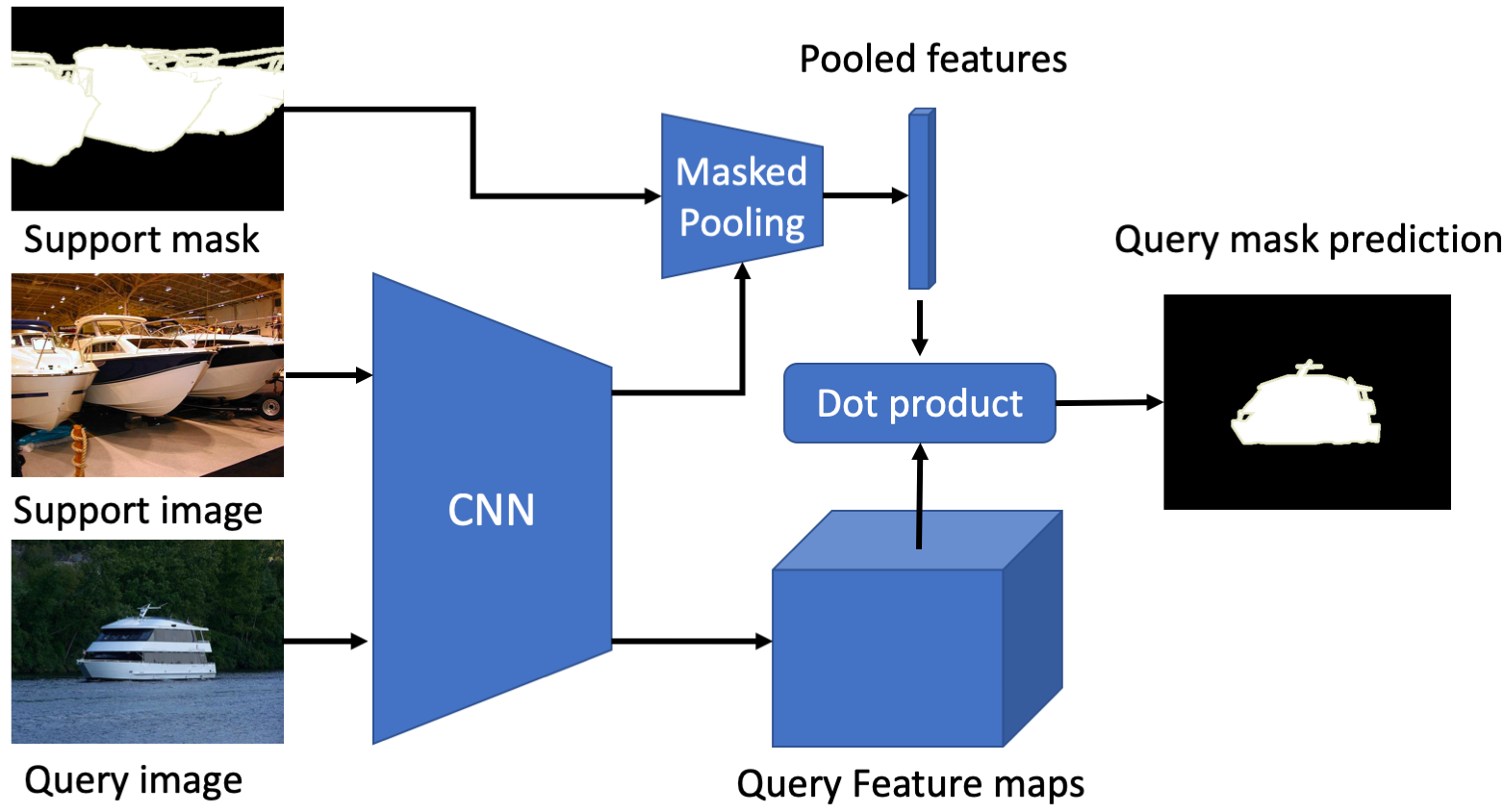
Few-Shot
Segmentation
|
We address few-shot
segmentation of foreground objects with
an ensemble of experts guided with the
gradient of loss incurred when
segmenting labeled support images.
|
|
|
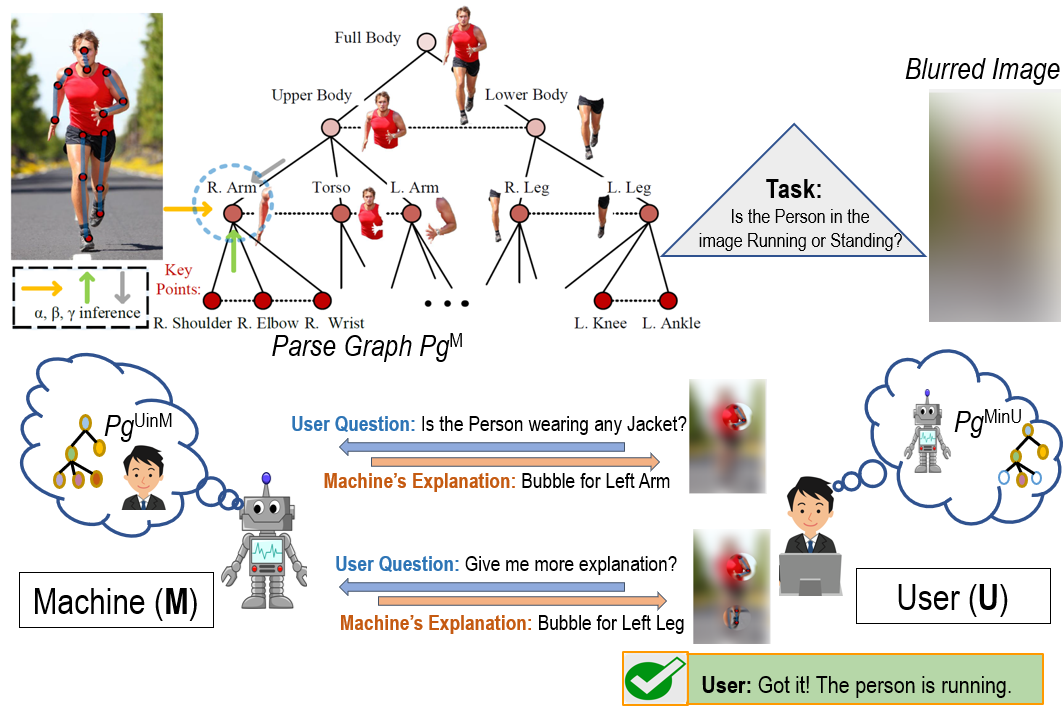
Explainable AI
with Theory of Mind
|
The Theory of Mind is used for
modeling machine's mind, human's mind as
inferred by the machine, and machine's
mind as inferred by the human, for
learning an optimal explanation policy
and evaluating human's trust in the
machine.
|
|
|
Deep Manifold
Distance Learning
|
Image distances are
efficiently estimated on a manifold of
select image representatives, using a
closed-form convergence solution of the
Random Walk, for image retrieval and
clustering.
|
|
|
Learning to
Learn Second-Order Back-Propagation Using
LSTMs
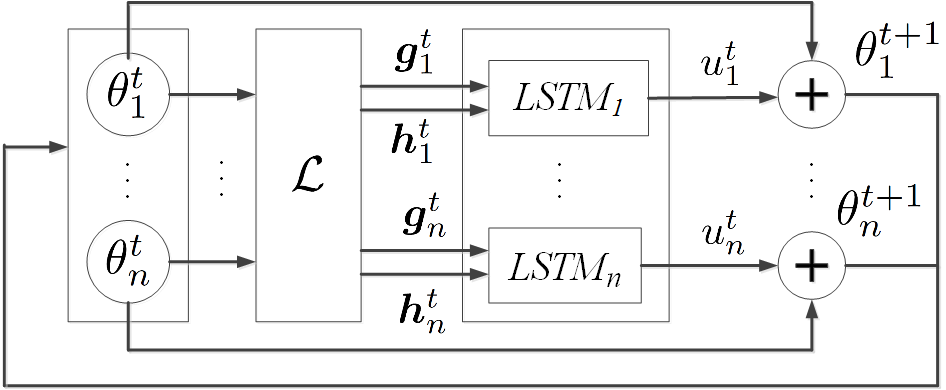
|
We derive an efficient
back-propagation for computing both
gradients and second derivatives of a
CNN’s loss. These are then input to an
LSTM for predicting optimal updates of
CNN parameters.
|
|
|
Temporal
Deformable Residual Networks for Action
Segmentation
|
Our TDRN computes deformable
temporal convolutions in two parallel
streams at short- and long-range scales
for action segmentation.
|
|
|
Boundary Flow
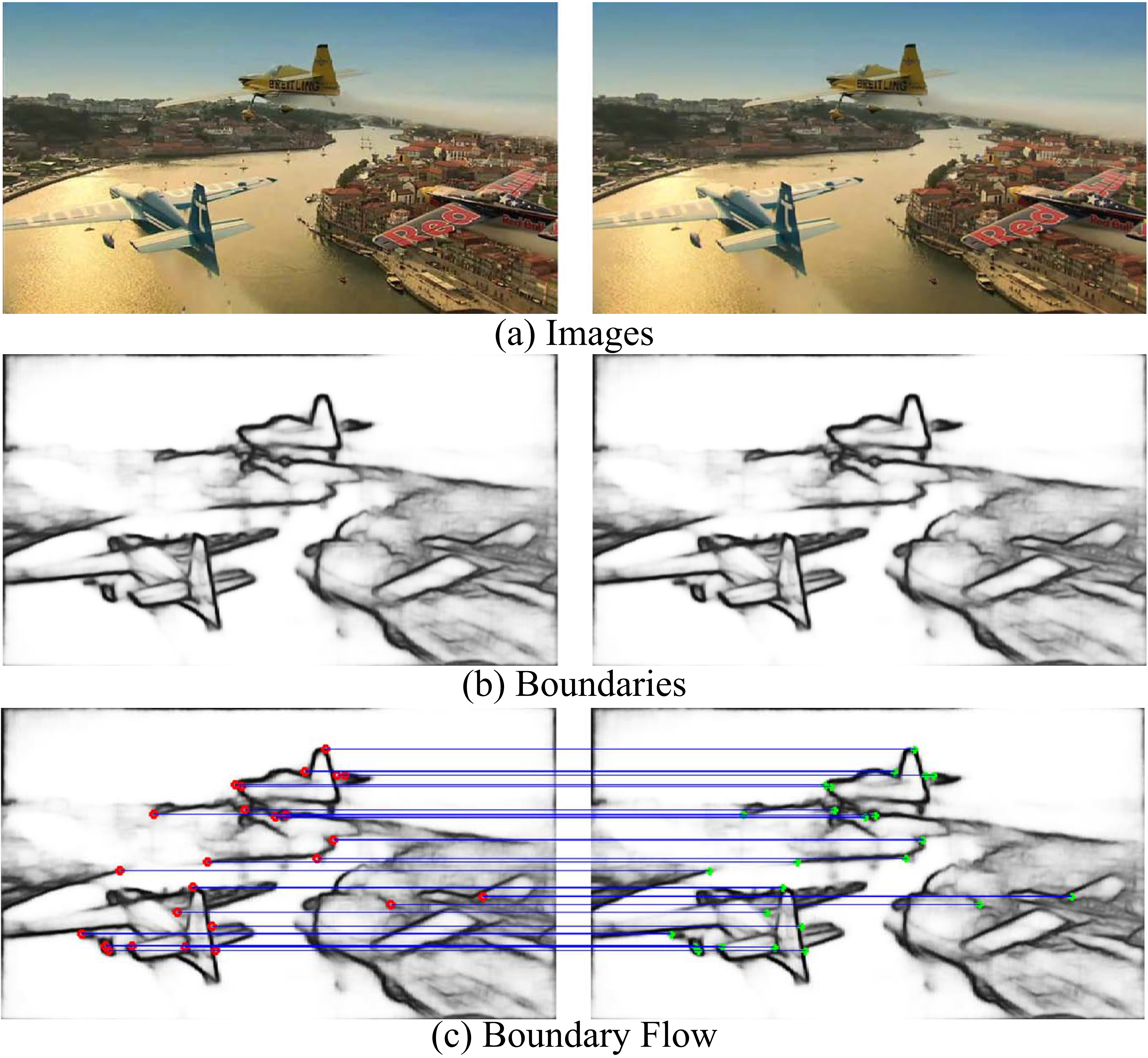
|
We specify a Siamese network
for joint estimation of object
boundaries and their motion in videos.
Boundary flow is an important mid-level
visual cue as boundaries and their flow
more explicitly indicate objects'
motions and interactions than common
dense optical flow.
|
|
|
Recognition as
HSnet Search for Informative Image Parts
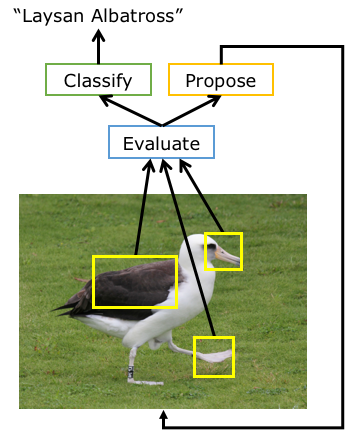
|
We specify a sequential
search for informative object parts over
a deep feature map in the image toward
fine-grained recognition.
|
|
|
Combining
Bottom-Up, Top-Down, and Smoothness Cues for
Weakly Supervised Segmentation
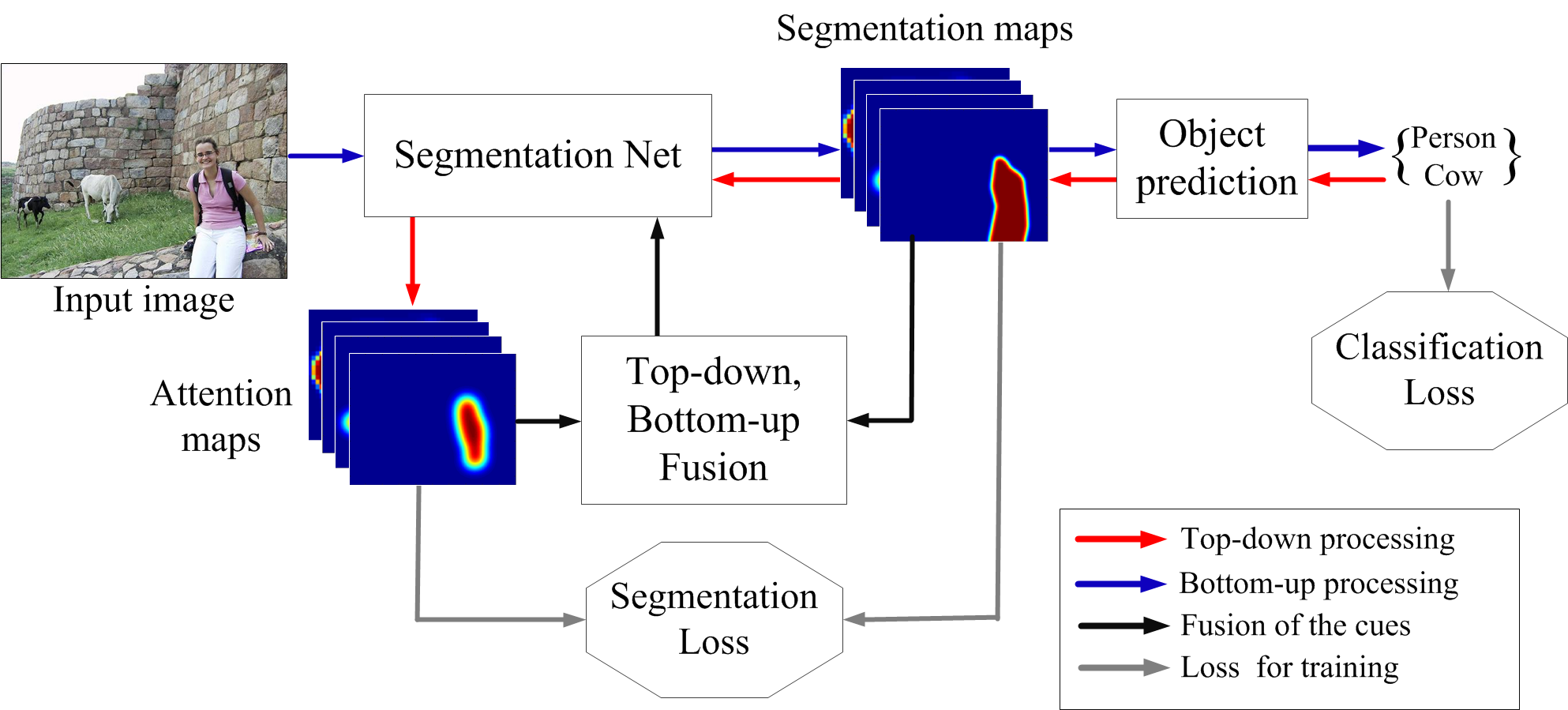
|
We fuse three processes
toward semantic segmentation -- namely,
(i) Bottom-up computation of neural
activations in a CNN for the image-level
class prediction; (ii) Top-down
estimation of attention maps of the
CNN's activations given the predicted
objects; and (iii) Lateral
attention-message passing among
neighboring neurons at the same CNN
layer.
|
|
|
Budget-Aware
Semantic Video Segmentation
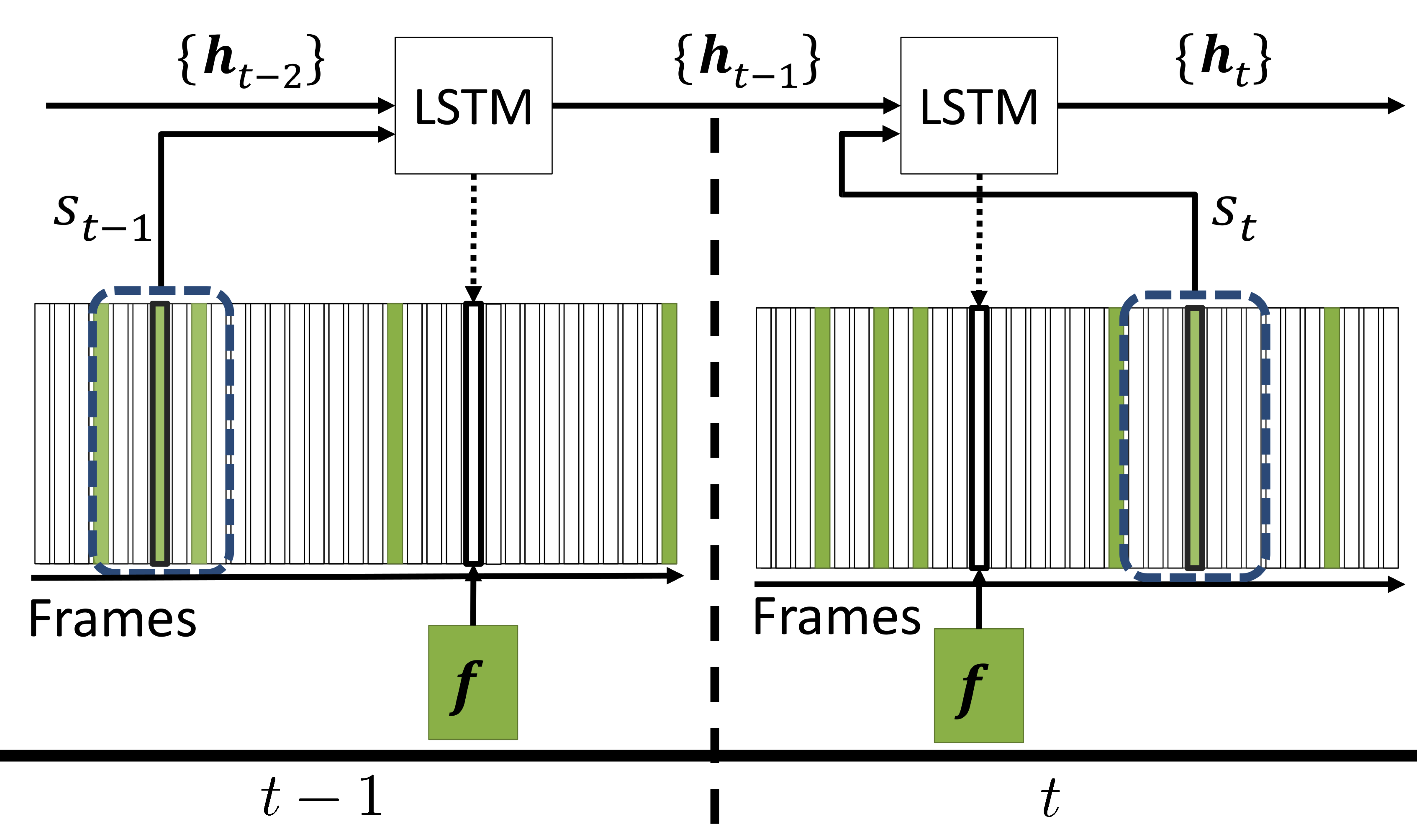
|
We learn a budget-aware
policy to optimally select a small
subset of frames for pixelwise labeling
by a CNN within a given time limit, and
then efficiently interpolate the
obtained segmentations to yet
unprocessed frames.
|
|
|
Unsupervised
Video Summarization
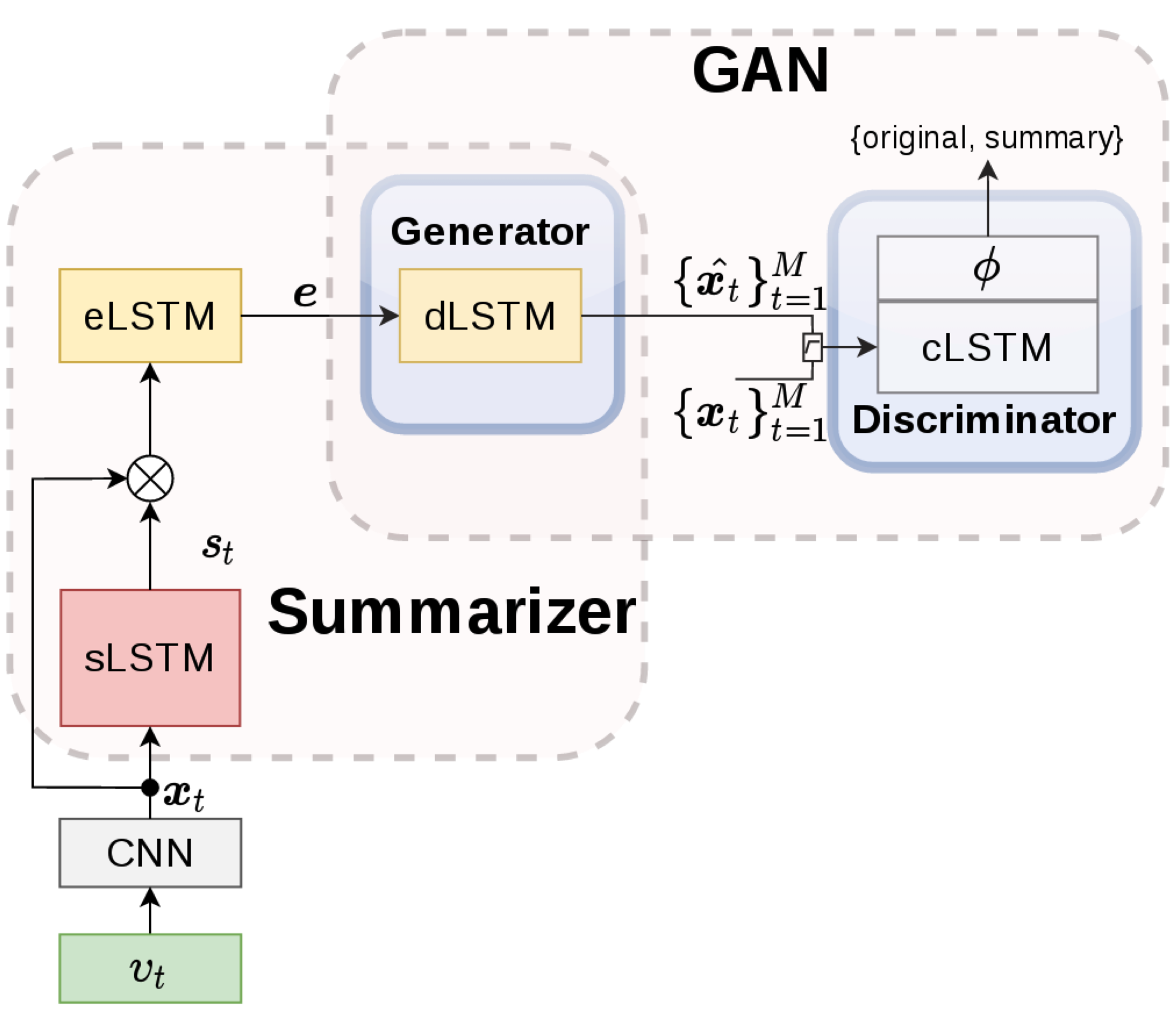
|
We use a deep generative
adversarial network to select a sparse
subset of video frames which optimally
represent the input video.
|
|
|
Confidence-Energy
Recurrent Network for Activity Recognition
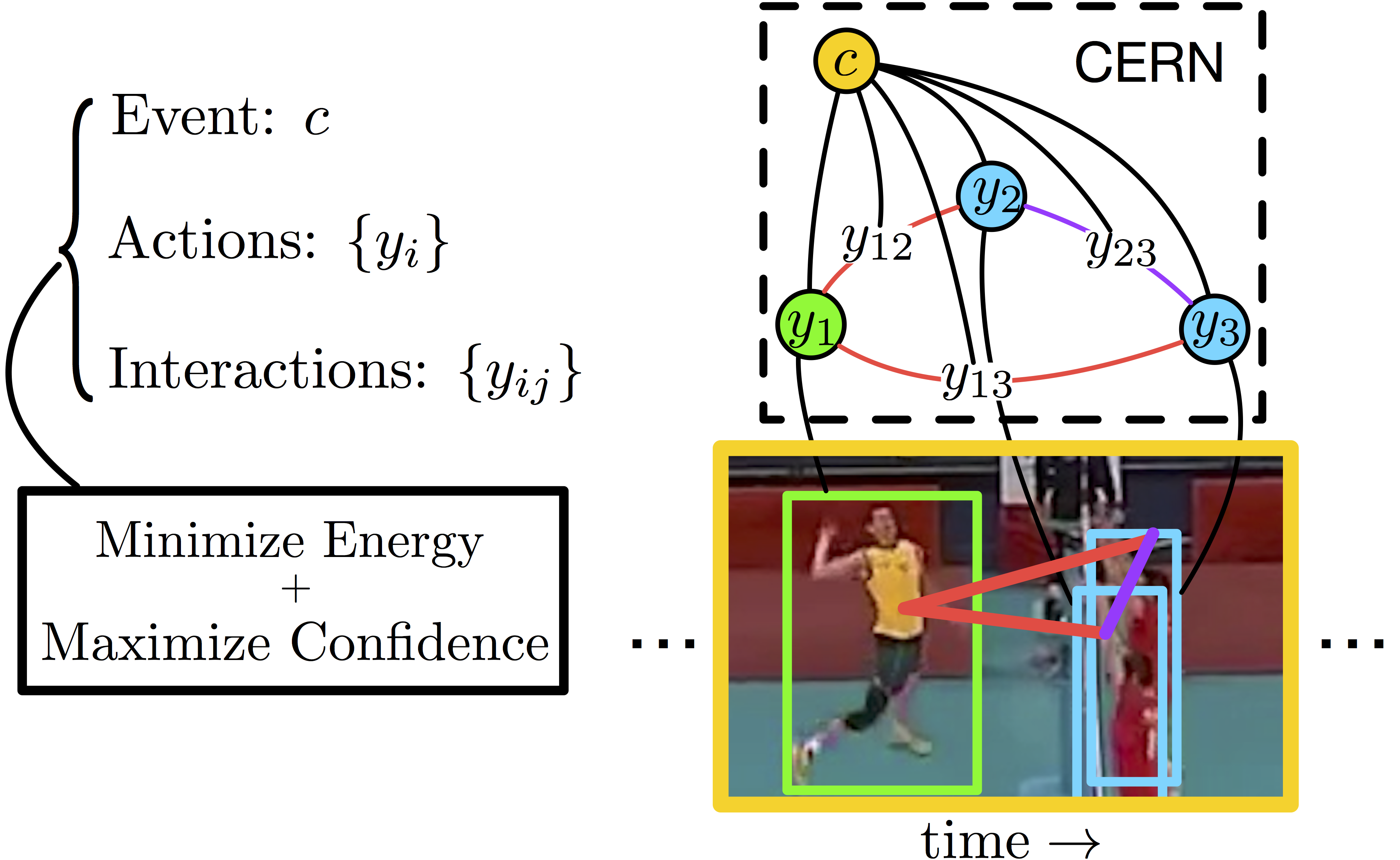
|
We use a two-level hierarchy
of Long Short-Term Memory (LSTM)
networks for predicting individual
actions, interactions, and group
activities. When estimating the energy
of our predictions, we additionally
compute p-values of the solutions, and
in this way choose the most confident
energy minima.
|
|
|
Affordance
Segmentation in Images

|
Pixels of indoor scenes are
labeled with five affordance types:
walkable, sittable, lyable, reachable,
and movable using a cascade of
convolutional neural networks (CNNs).
CNNs first extract mid-level visual
cues, including: depth map, surface
normals, and coarse semantic scene
segmentation, and then combine them
toward affordance segmentation.
|
|
|
Recurrent
Temporal Deep Field for Semantic Video
Labeling

|
A new deep architecture,
called Recurrent Temporal Deep Field
(RTDF), is specified for semantic video
labeling. RTDF is a conditional random
field that combines a deconvolution
neural network and a recurrent temporal
restricted Boltzmann machine.
|
|
|
Leveraging
Human-Skeleton Sequences for Action
Recognition in Videos
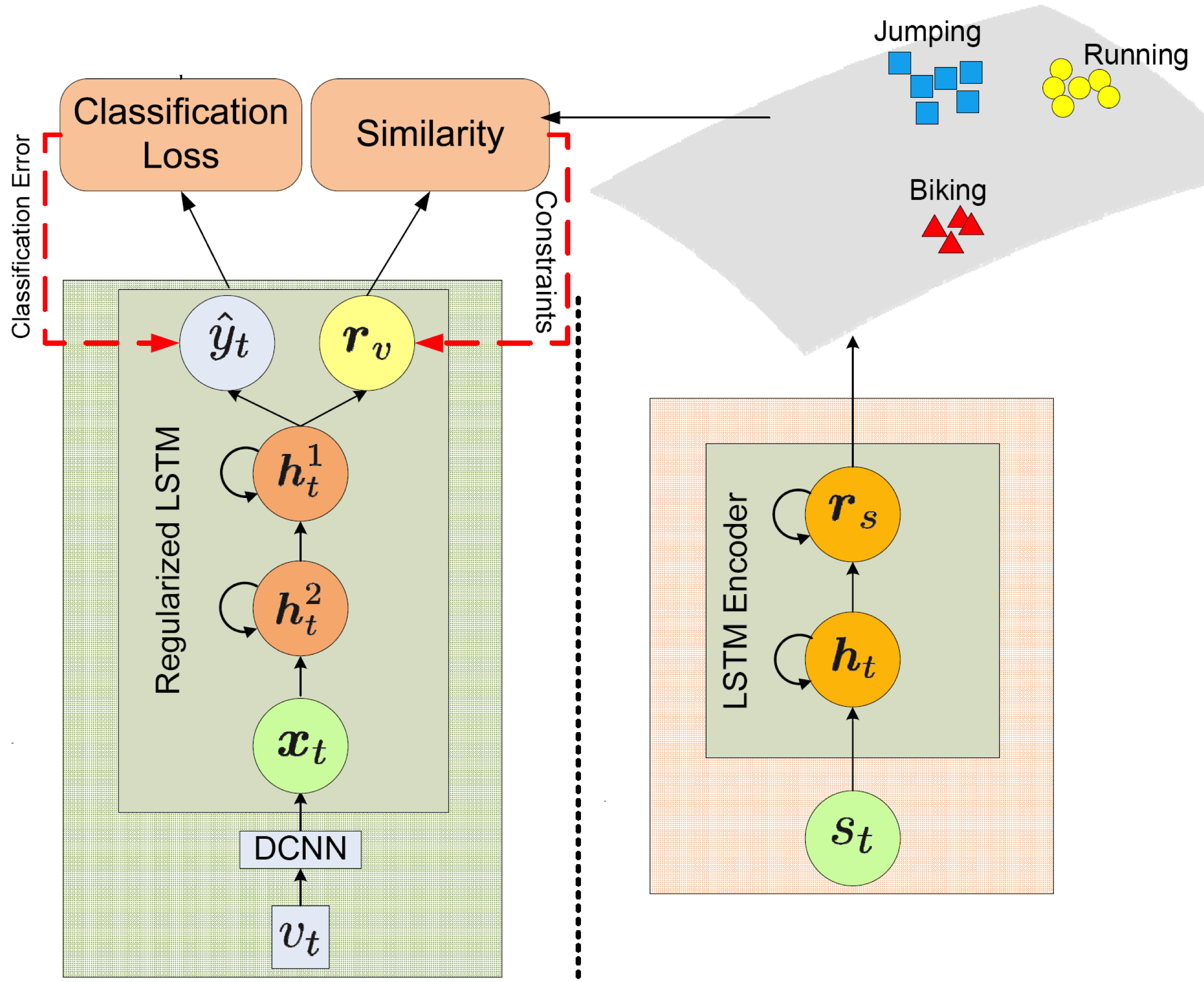
|
A large-scale action
recognition in videos can be greatly
improved by providing an additional
modality in training -- 3D
human-skeleton sequences.
|
|
|
Monocular
Depth Estimation Using Neural Regression
Forest

|
A new deep architecture --
neural regression forest (NRF) -- is
used for depth estimation from a single
image. NRF consists of regression trees,
whose each node corresponds to a
convoutional neural network (CNN).
|
|
|
Budgeted
Semantic Video Segmentation
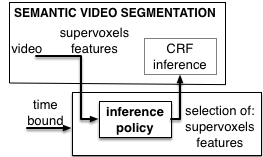
|
Our goal is to accurately
label all pixels in the video within a
specified time budget. We formulate a
new budgeted inference for a CRF that
intelligently selects the most useful
subsets of features to be extracted from
subsets of supervoxels in the video
within the time budget.
|
|
|
Continuous
Facial Behavior Estimation

|
A Doubly Sparse Relevance
Vector Machine is specified to enforce
double sparsity in the joint selection
of the most relevant training examples,
and the most important kernels
associated with facial parts for
continuous estimation of facial
behavior.
|
|
|
Semantic
Segmentation of RGBD Images with Mutex
Constraints
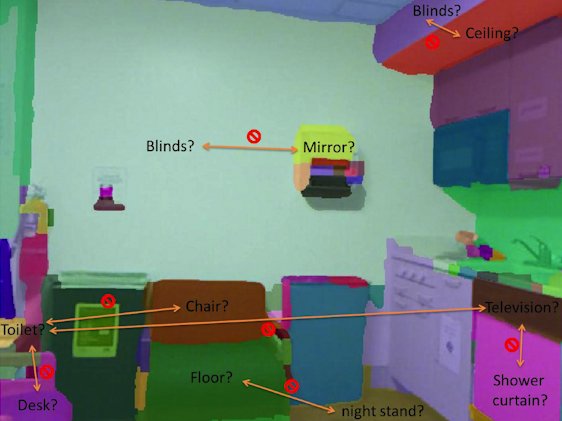
|
Pixels are assigned class
labels, such that the labeling strictly
satisfies all mutual exclusion (mutex)
constraints, and thus does not violate
common-sense physics laws. The mutex
constraints considered include: object
co-occurrence, relative height and
support relationships.
|
|
|
Tree-Cut for
Probabilistic Image Segmentation
|
Given an image and its region
tree, image segmentation is formalized
as sampling cuts in the tree using
dynamic programming. Our tree-cut model
can be tuned to sample segmentations at
a particular scale of interest, and thus
conduct a scale-specific evaluation.
|
|
|
Joint
Inference of Groups, Events and Human roles in
Aerial Videos

|
We parse low-resolution
aerial videos of large spatial areas, in
terms of detecting events, and grouping
and assigning roles to people engaged in
the events. The challenges arising from
low resolution and top-down views are
addressed by conducting joint inference
of these tasks.
|
|
|
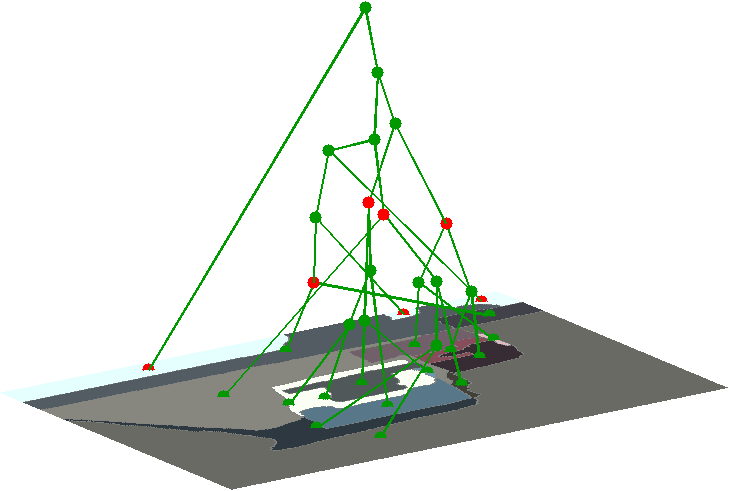
Latent Trees
for Estimating Intensity of Facial Action
Units
|
A new generative latent tree
(LT) model is specified for FAU
intensity estimation. Our new structure
learning iteratively builds LT so as to
maximize the likelihood and minimize the
model complexity. We derive closed-form
expressions of posterior marginals for
all variables in LT, and specify an
efficient bottom-up/top-down inference.
|
|
|
HC-Search for
Structured Prediction in Computer Vision
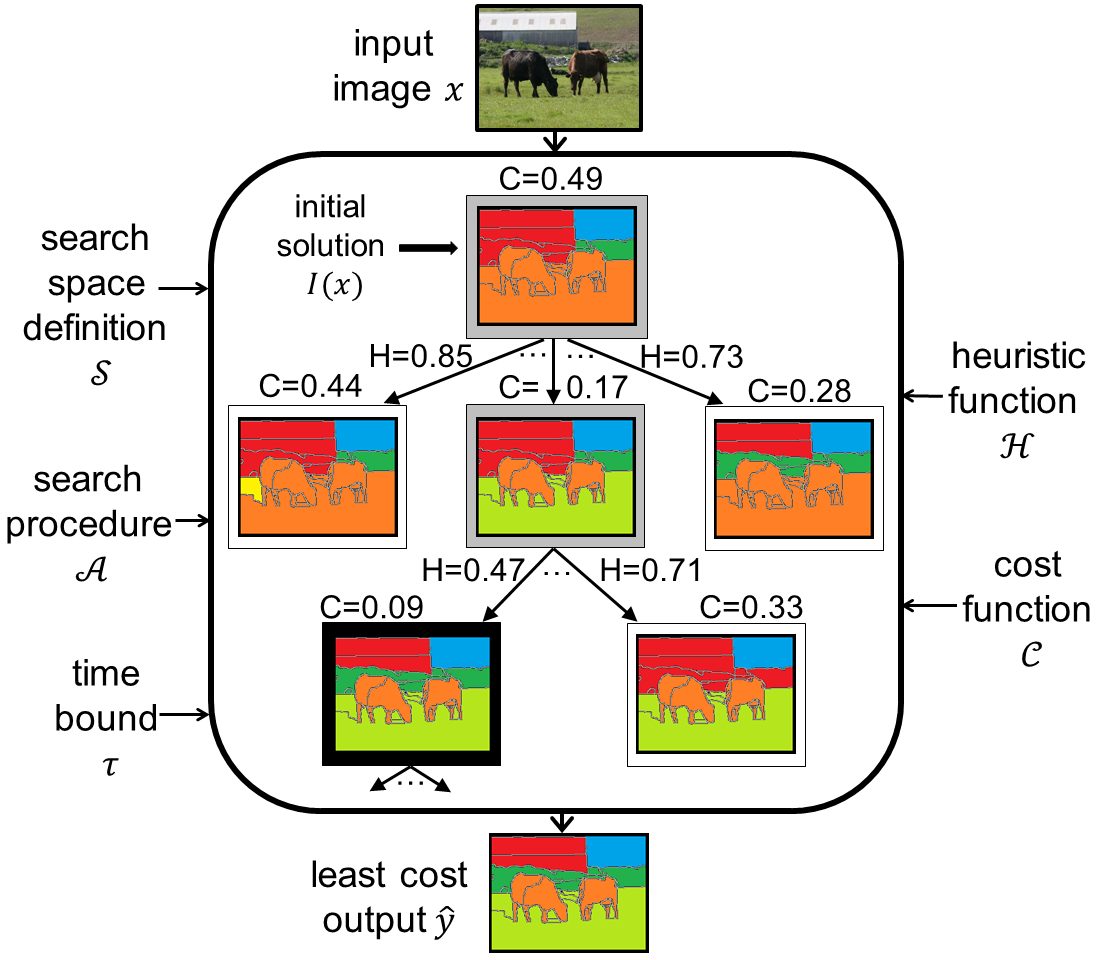
|
Semantic scene segmentation
and monocular depth estimation are
formulated as a search problem. The
search space is defined by probabilistic
sampling of plausible image
segmentations.
|
|
|
Person Count
Localization in Videos
 |
Given a video, we output for
each frame a set of: 1) Detections
optimally covering both isolated
individuals and cluttered groups of
people; and 2) Counts of people inside
these detections. This problem is a
middle-ground between frame-level person
counting, which does not localize
counts, and person detection aimed at
perfectly localizing people with
count-one detections.
|
|
|
Monocular
Extraction of 2.1D Sketch Using Constrained
Convex Optimization

|
We partition the image into
regions, and estimate their depth
ordering in the scene. This is cast as a
constrained convex optimization problem,
and solved within the optimization
transfer framework. Our new optimization
transfer admits a closed-form expression
of the duality gap, and thus allows
explicit computation of the achieved
accuracy.
|
|
|
HiRF:
Hierarchical Random Field for Collective
Activity Recognition in Videos
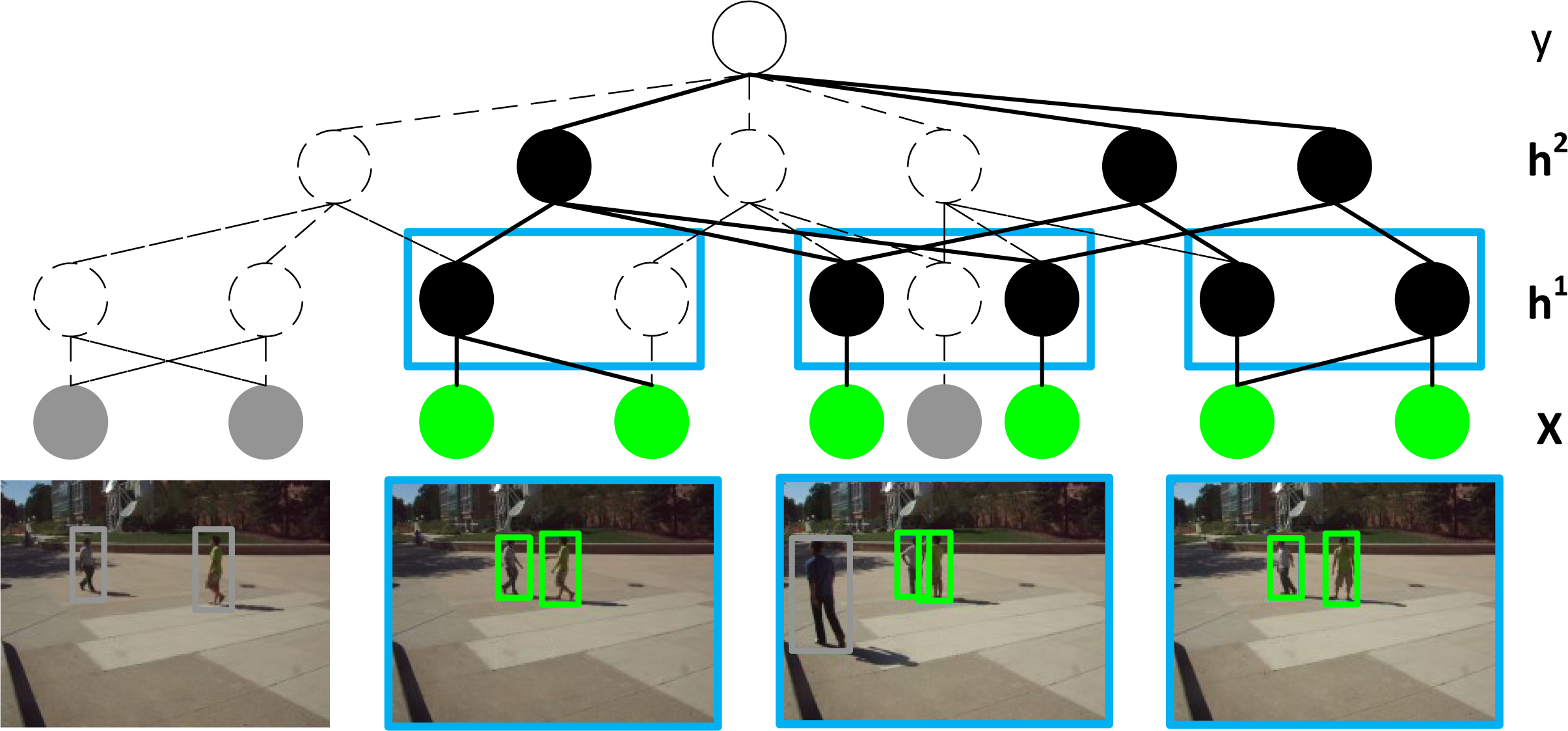
|
We formulate Hierarchical
Random Field (HiRF) for activity
recognition. HiRF establishes strictly
hierarchical links between all
variables, discarding
the common lateral temporal connections.
This enables an efficient
bottom-up/top-down inference.
|
|
|
Multi-Object
Tracking via Constrained Sequential Labeling
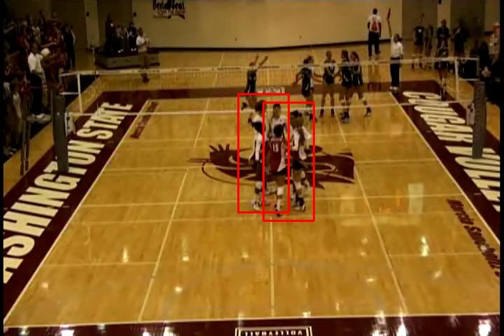 |
Constrained sequential
labeling (CSL) assigns object
identifiers to supervoxels, while
respecting domain constraints. CSL is
well-suited for simultaneous labeling
and fixing noisy merges and splits of
our mid-level features, which cannot be
handled in a principled manner by
traditional network flow approaches. CSL
is efficient due to contraint
propagation.
|
|
|
Scene Labeling
Using Beam Search Under Mutex Constraints
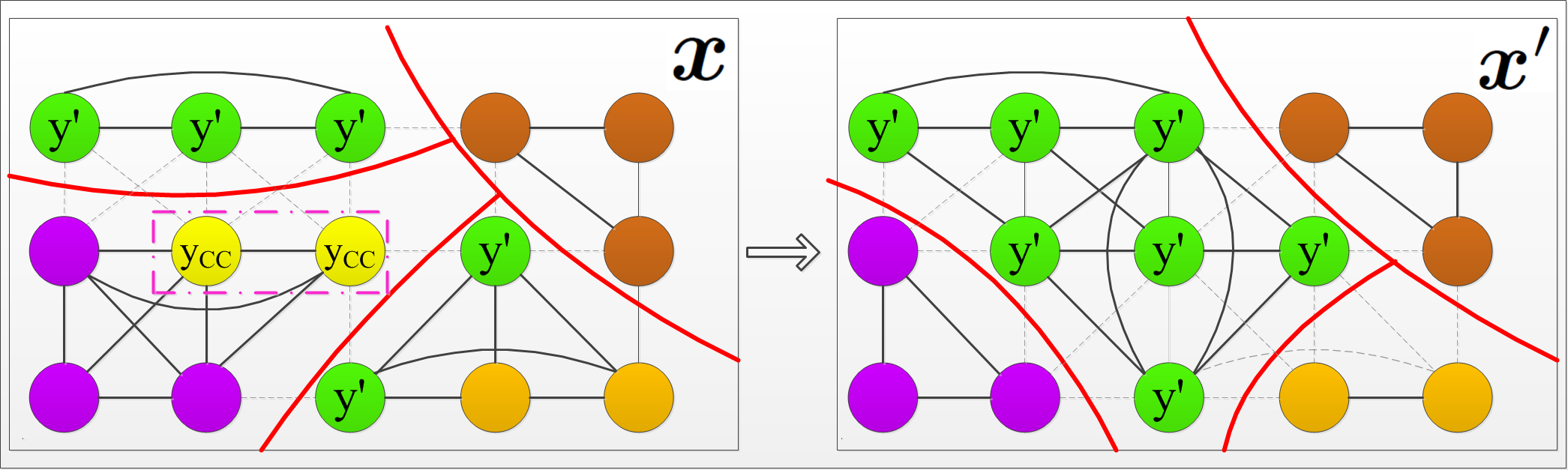
|
We cast scene labeling as
quadratic program (QP) with mutual
exclusion (mutex) constraints on class
label assignments. The QP is solved
efficiently using beam search,
which explicitly accounts for spatial
extents of objects, and guarantees that
all mutex constraints from domain
knowledge are satisfied.
|
|
|
Play Type
Recognition in Real-World Football Video
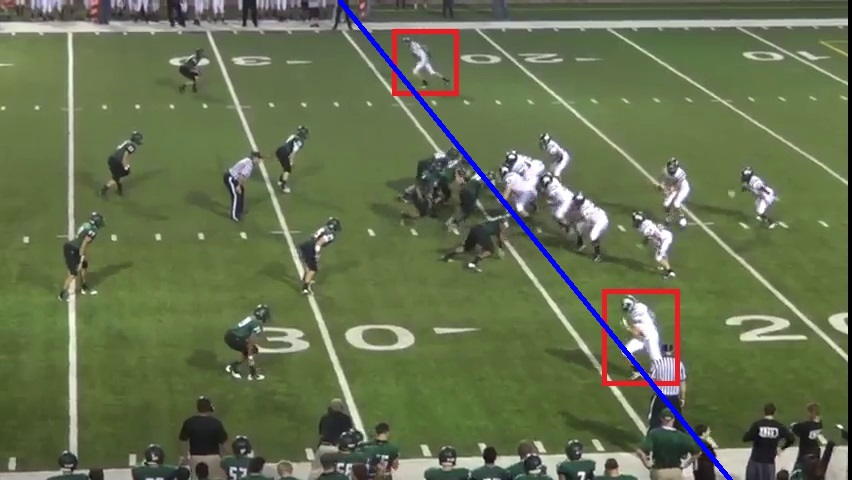
|
Given a video sequence of
plays of a football game, we integrate
responses of the play-level detectors
with global game-level reasoning to
overcome huge variations in camera
viewpoint, motion, and distance from the
field, as well as amateur camerawork
quality.
|
|
|
Inferring Dark
Matter and Dark Energy from Videos
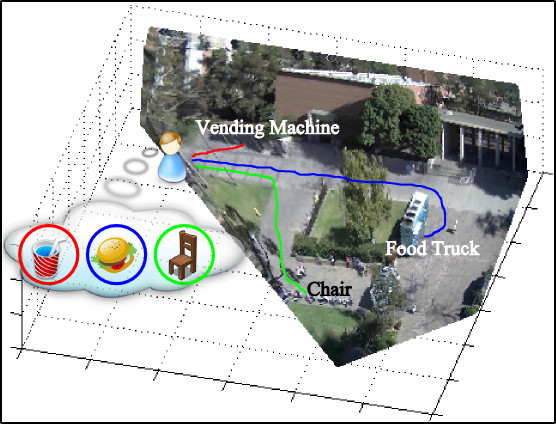 |
Functional objects do not have
discriminative appearance and shape, but
can be viewed as "dark matter",
emanating "dark energy" that affects
people’s trajectories in the video. For
localizing functional objects, we
analyze noisy behavior of people in the
scene using agent-based, probabilistic
Lagrangian mechanics.
|
|
|
Latent
Multitask Learning for View-Invariant Action
Recognition

|
When each viewpoint of a given
set of action classes is specified as a
learning task then multitask learning
appears suitable for achieving view
invariance in recognition. We extend the
standard multitask learning to allow
identifying: (1) latent groupings of
action views (i.e., tasks), and (2)
discriminative action parts, along with
joint learning of all tasks.
|
|
|
Monte Carlo
Tree Search for Scheduling Activity
Recognition
|
Querying an activity in a long
video footage may require running a
multitude of detectors, and tracking
their detections. We use Monte Carlo
Tree Search to optimally schedule a
sequence of detectors and trackers to be
run, and where they should be applied in
the space-time volume.
|
|
|
SLEDGE:
Sequential Labeling of Image Edges for
Boundary Detection

|
We sequentially label image
edges as "on" or "off" object
boundaries. A visited edge is labeled as
boundary based on evidence of its
perceptual grouping with already
identified boundaries. We use both local
Gestalt cues, and the global Helmholtz
principle of non-accidental grouping.
Image edges are extracted with our new
detector that finds salient pixel
sequences which separate distinct
textures within the image.
|
|
|
Hough Forest
Random Field for Object Recognition and
Segmentation
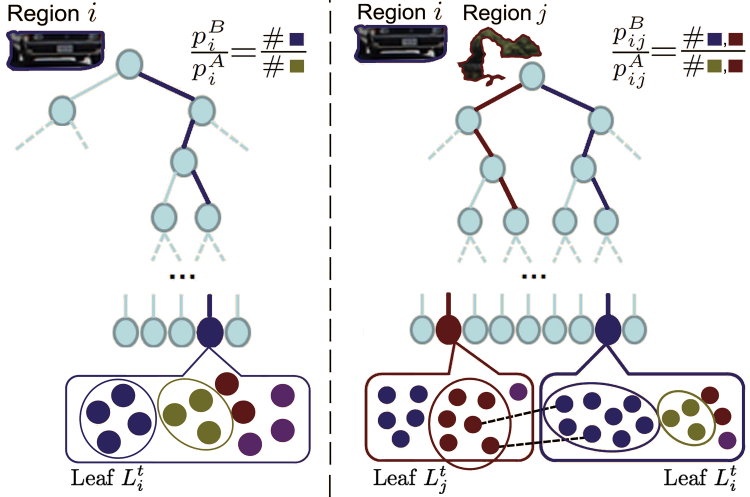
|
We combine Hough forest (HF)
and conditional random field (CRF) into
HFRF to assign labels of object classes
to image regions. HF captures intrinsic
and contextual properties of objects as
class histograms in the leaf nodes. This
evidence is used in CRF inference for
non-parametric density estimation of the
posteriors. Theoretical error bounds of
HF and HFRF applied to a two-class
object detection and segmentation are
also presented.
Personal use of
this material is permitted.
However, permission to
reprint/republish this material
for advertising or promotional
purposes or for creating new
collective works for resale or
redistribution to servers or
lists, or to reuse any
copyrighted component of this
work in other works must be
obtained from the IEEE.
|
|
|
Cost-Sensitive
Top-down/Bottom-up Inference for Multiscale
Activity Recognition
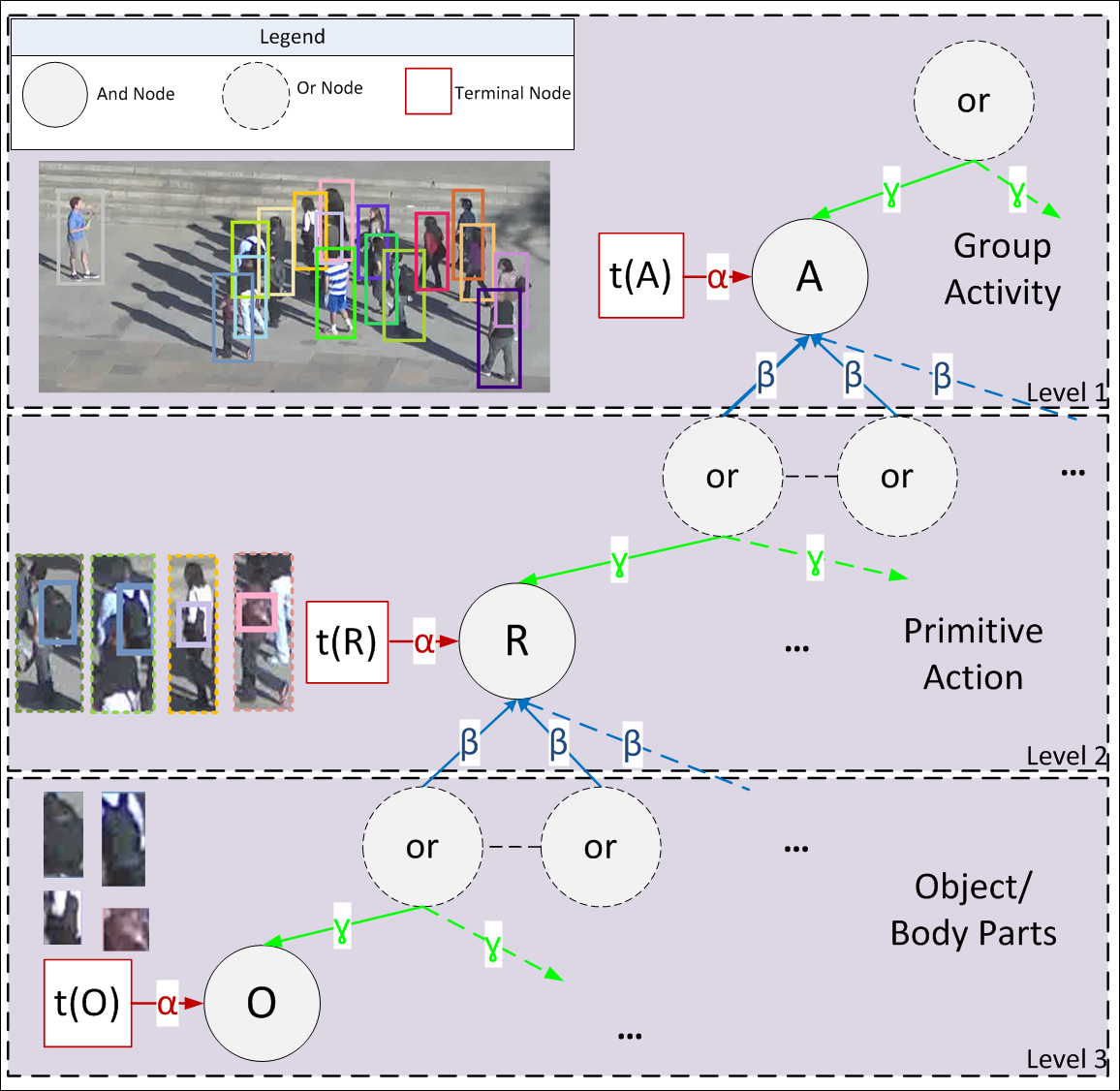
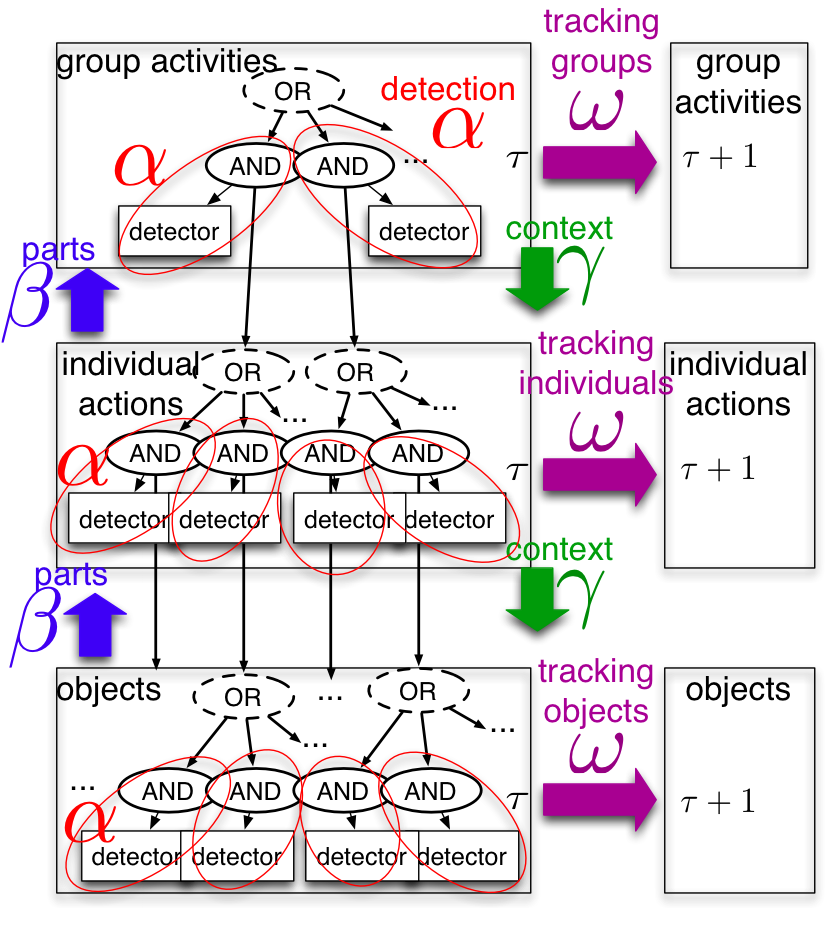
|
While prior work typically
addresses activity recognition at a
single scale, we jointly model group
activities, individual actions, and
participating objects with an AND-OR
graph, and exploit its hierarchical
structure for efficient inference. An
explore-exploit strategy is used to
adaptively zoom-in or zoom-out for
cost-sensitive inference.
|
|
|
Human Actions
as Stochastic Kronecker Graphs
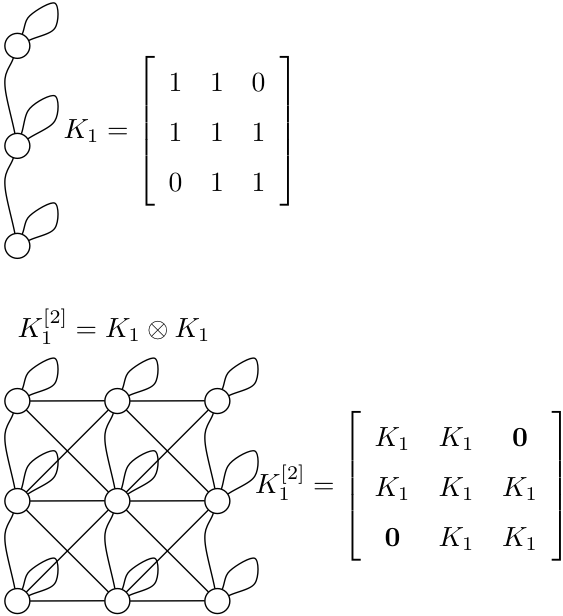
|
A human activity can be
viewed as a space-time repetition of
activity primitives. Given a set of
primitives, and an affinity matrix of
their probabilistic grouping, we
formulate that a video of the activity
is probabilistically generated by a
sequence of the Kronecker products of
the affinity matrix.
|
|
|
Sum-Product
Networks for Modeling Activities with
Stochastic Structure
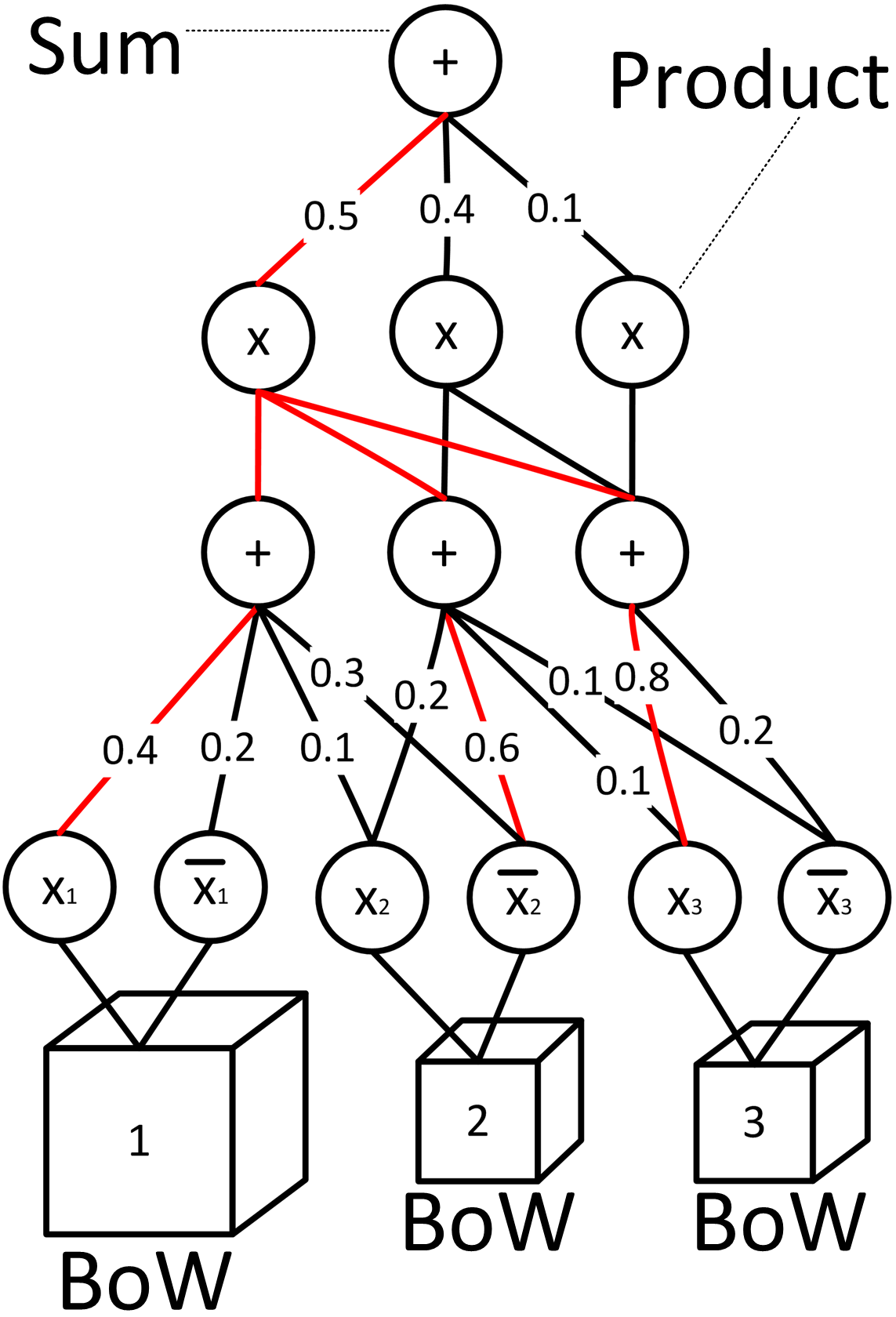
|
Activities with stochastic
structure are characterized by variable
space-time arrangements of
subactivities, and may be conducted by a
variable number of actors. We use
sum-product networks (SPN) to model such
activities. The products are aimed at
encoding particular configurations of
activity parts, and the sums serve to
capture their alternative
configurations. A new Volleyball dataset
is collected and annotated.
|
|
|
Learning
Spatiotemporal Graphs of Human Activities
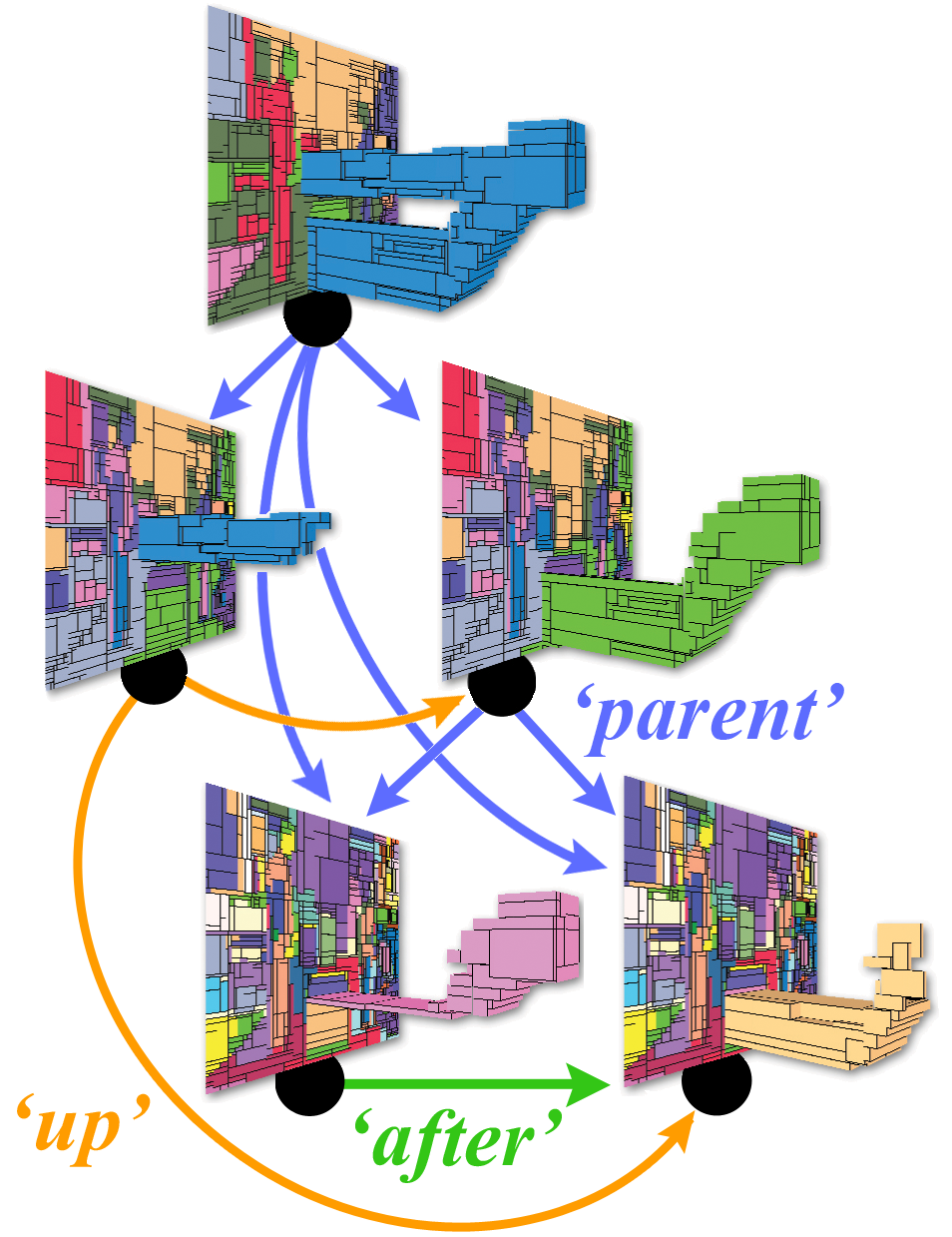
|
Given a set of spatiotemporal
graphs, we learn their model graph, and
pdf's associated with nodes and edges of
the model. The model graph adaptively
learns from data relevant video segments
and their spatiotemporal relations. We
present a novel weighted-least-squares
formulation of learning a structural
archetype of graphs. The model is used
for video parsing.
|
|
|
From Contours
to 3D Object Detection and Pose Estimation

|
We address view-invariant
object detection and pose estimation
using contours as basic object features.
A top-down feedback from inference warps
the image, so the bottom-up extraction
of contours could better collectively
summarize relevant visual information
and match our 3D object model, under
arbitrary non-rigid shape deformations
and affine projection.
|
|
|
A Chains Model
for Localizing Participants of Group
Activities in Videos
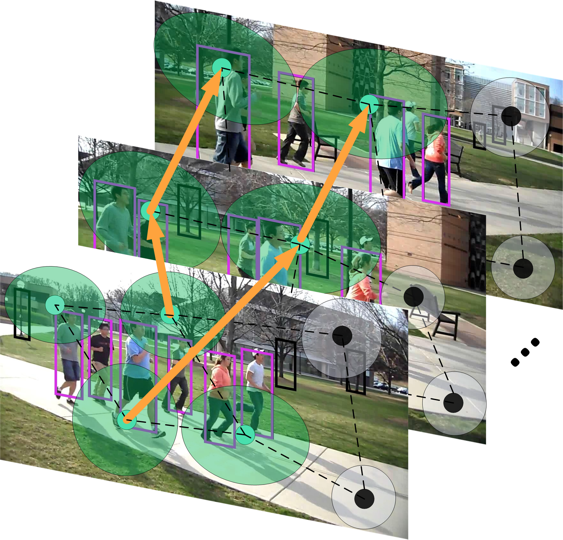
|
We address recognition of
group activities in a given video,
localization of video parts where these
activities occur, and detection of
actors involved in them. A new
generative chains model is formulated to
organize a large number of video
features in an ensemble of chains,
starting and ending at the end points of
the time interval occupied by the target
activity.
|
|
|
Scene Shape
from Texture of Objects

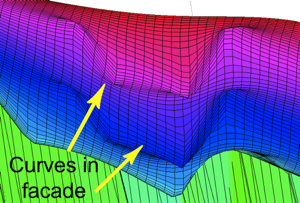 |
We estimate the 3D shape of a
scene from texture arising from a
spatial repetition of objects in the
image. Unlike existing work, our
monocular estimation does not use domain
knowledge about the layout of common
scene surfaces. We also show that
reasoning about texture of objects in
the scene improves object detection.
|
|
|
Multiobject
Tracking as Maximum Weight Independent Set
 
|
We prove that the data
association problem -- the core of
tracking -- can be formulated as finding
the maximum-weight independent set
(MWIS) of non-adjacent tracklets in a
graph. We present a new, polynomial-time
MWIS algorithm, and prove that it
converges to an optimum.
|
|
|
Probabilistic
Event Logic for Interval-Based Event
Recognition
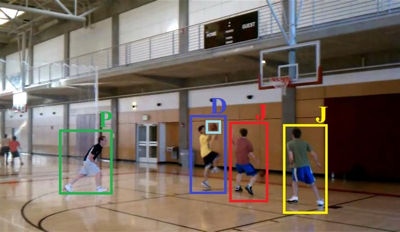 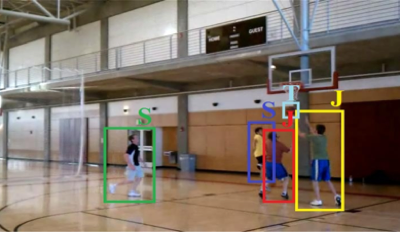
|
We introduce probabilistic
event logic (PEL) for representing both
hard and soft temporal constraints among
events. A PEL knowledge base consists of
confidence-weighted formulas from a
temporal event logic, and specifies a
joint distribution over the occurrence
time intervals of all events. Our MAP
inference for PEL addresses the
scalability issue of reasoning about all
time intervals in video, by leveraging
the spanning-interval data structure. A
spanning interval compactly represents
entire sets of time intervals without
enumerating them.
|
|
|
(RF)^2 --
Random Forest Random Field
 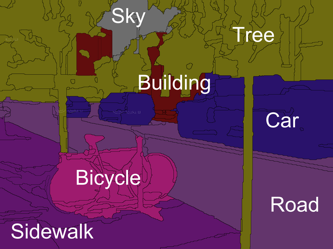
|
We combine random forest (RF)
and conditional random field (CRF) to
address multiclass object recognition
and segmentation. Inference of (RF)^2
uses Metropolis-Hastings jumps which
depend on two ratios of the proposal and
posterior distributions. Our key idea is
to directly learn these ratios using RF.
|
|
|
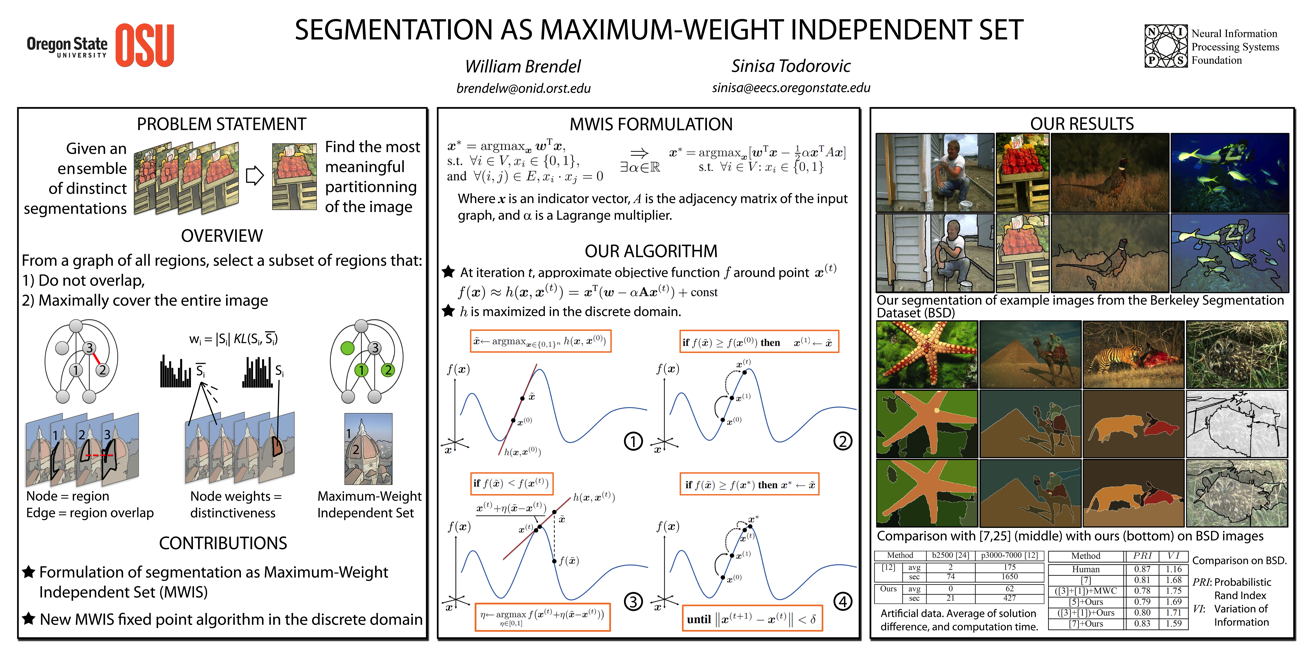
Segmentation
as Maximum-Weight Independent Set
 |
Given an image, and an
ensemble of its distinct low-level
segmentations, we identify visually
"meaningful" segments in the ensemble.
This is formalized as the maximum-weight
independent set (MWIS) problem. We
formulate a new MWIS iterative
algorithm, where each iteration solves a
Taylor expansion of the MWIS objective
function in the discrete domain.
|
|
|
Activities as
Time Series of Human Postures
 |
We show that certain human
actions can be represented by short time
series of codewords. The codewords
represent still snapshots of human-body
parts in their discriminative postures,
and objects that people interact with
while performing the activity. This
carries many advantages for developing a
robust, efficient, and scalable activity
recognition system.
|
|
|
From a Set of
Shapes to Object Discovery
 |
We show that shape is
expressive and discriminative enough to
provide robust object discovery in the
midst of background clutter. We build a
graph that captures spatial layouts of
edges extracted from a set of images,
and conduct its multicoloring by a new
coordinate ascent Swendsen-Wang cut. The
resulting clusters of edges delineate
the boundaries of distinct objects
discovered in the image set.
|
|
|
Monocular
Extraction of 2.1D Sketch
 |
Given a segmentation and
T-junctions of an image, we estimate the
depth layers of the scene. The
estimation is formalized as a quadratic
optimization so the resulting 2.1D
sketch is smooth in all image areas
except on region boundaries.
|
|
|
Video Painting
with Space-Time Varying Style Parameters
 |
An input video is rendered by
applying a distinct painting style to
each spatiotemporal tube, corresponding
to a moving object in the video.
Spatiotemporal segmentation allows
the user a control to vary
painting styles in 2D space and time,
and thus convey rich semantic
content, e.g., emotions, illusion,
chaos, etc.
|
|
|
Toward Optimal
Feature Selection through Local Learning
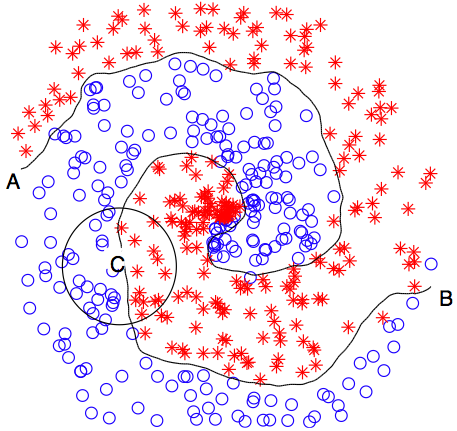 |
Given data with a huge number
of irrelevant features (> 10 6),
select features relevant to data
classification. We decompose a nonlinear
problem into a set of locally linear
ones, and then globally learn feature
relevance within the large margin
framework.
|
|
|
Video Object
Segmentation by Tracking Regions
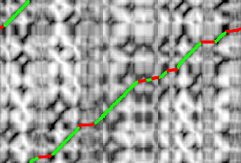 |
Given an arbitrary video,
segment all moving and static objects
present. We transitively match contours
of image regions across the frames such
that the resulting tracks are locally
smooth.
|
|
|
Texel-based
Texture Segmentation
 |
Given an arbitrary image,
discover and segment all distinct
texture subimages. We use the meanshift
to simultaneously estimate the pdf of
texel appearance and the pdf of texel
placement.
|
|
|
Matching
Hierarchies of Deformable Shapes
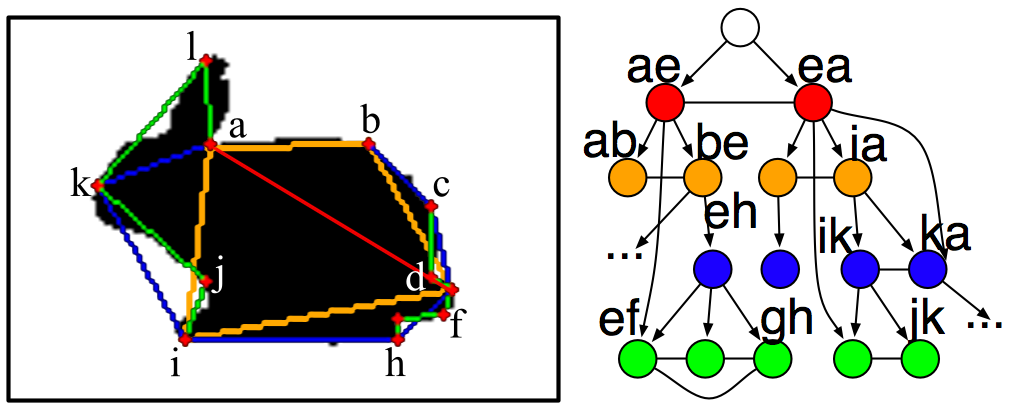 |
Shapes are represented by
graphs whose nodes correspond to shape
parts, and edges capture their neighbor
and part-of interactions. Shape matching
is formulated as finding the subgraph
isomorphism that minimizes a quadratic
cost.
|
|
|
Dictionary-Free
Categorization
Using Evidence Trees
 |
How to categorize images
showing very similar object categories?
We mathematically prove that it is
better to use class evidence accumulated
from all image features than to use a
majority voting of class decisions made
on each individual feature.
|
|
|
Scale-invariant
Region-based
Hierarchical Image Matching
 |
Find correspondences between
similar objects in images captured under
large variations in scale. Scale
invariance is achieved by decoupling the
scales of objects from those of scenes,
and by down-weighting the contributions
of fine-resolution details to matching.
|
|
|
Learning
Subcategory Relevances for Category
Recognition
 |
Detections of distinct object
categories provide different degrees of
evidence for recognition of more
complex, parent categories. This is
estimated using local learning.
|
|
|
Connected
Segmentation Tree
- A Joint
Representation of Region Layout and Hierarchy
-
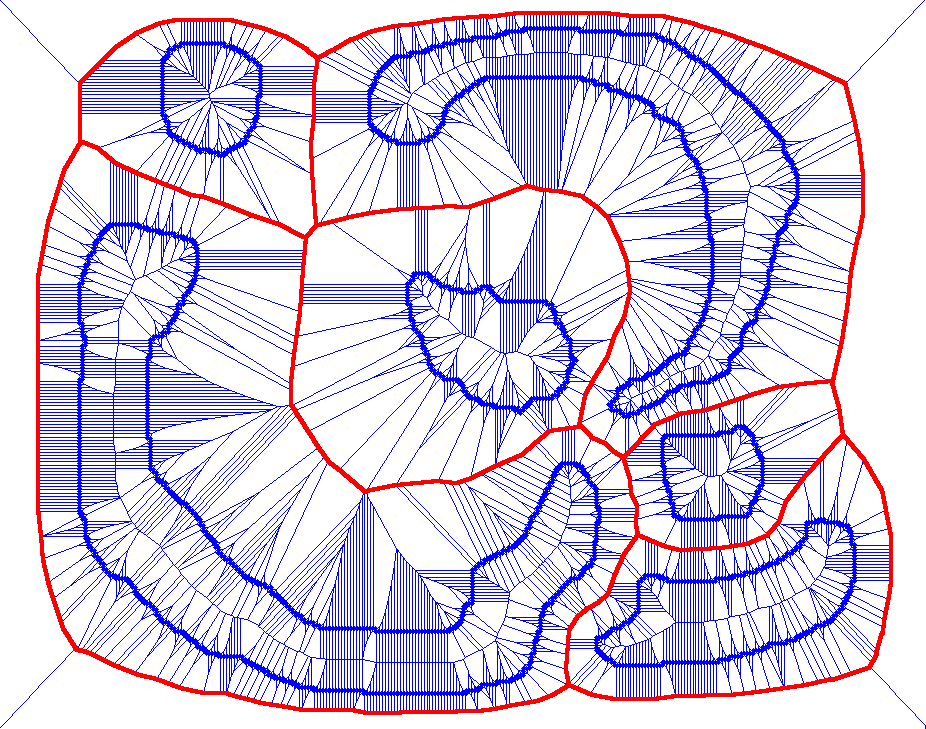 |
CST is a hierarchy of region
adjacency graphs. The CST model of an
object category is learned by
simultaneously searching for both the
most salient regions, and the most
salient containment and neighbor
relationships of regions across training
images.
|
|
|
Extracting
Texels in 2.1D Natural Textures
 |
Given an image of 2.1D
texture, learn without any supervision a
generative model of the entire
(unoccluded) texel. Learning involves
concurrent estimation of the
texel-subtexel structure, and the pdf's
of each texel part from only partially
visible texels in the image.
|
|
|
Taxonomy of
Categories Present in Arbitrary Images
 |
Given an
arbitrary (unlabeled) image set, learn
the models of all visual categories
present, and their inter-category
relationships, i.e., their taxonomy. The
taxonomy recursively defines categories
as spatial configurations of (simpler)
subcategories each of which may be
shared by many categories.
|
|
 |
The hoofed animals dataset
contains very similar categories that
share a number of similar parts. Each
image may contain multiple instances of
multiple categories. Animals are
articulated, non-rigid objects,
appearing at different scales amidst
clutter, and may be partially occluded.
|
|
 |
The images show homogeneous,
frontally viewed, natural, 2.1D
textures, where: (1) Texels are only
statistically similar to each other; (2)
Texel placement is random; (3)
Repetition of subtexels define a finer
grain texture coexisting with the main
texture; (4) Due to texel overlap, texel
contours form complex patterns (e.g.,
several edges meet at one point), and
overlapping texels have low contrasts,
all of which makes texel segmentation
difficult.
|
|
|
Unsupervised
Category Modeling, Recognition and
Segmentation
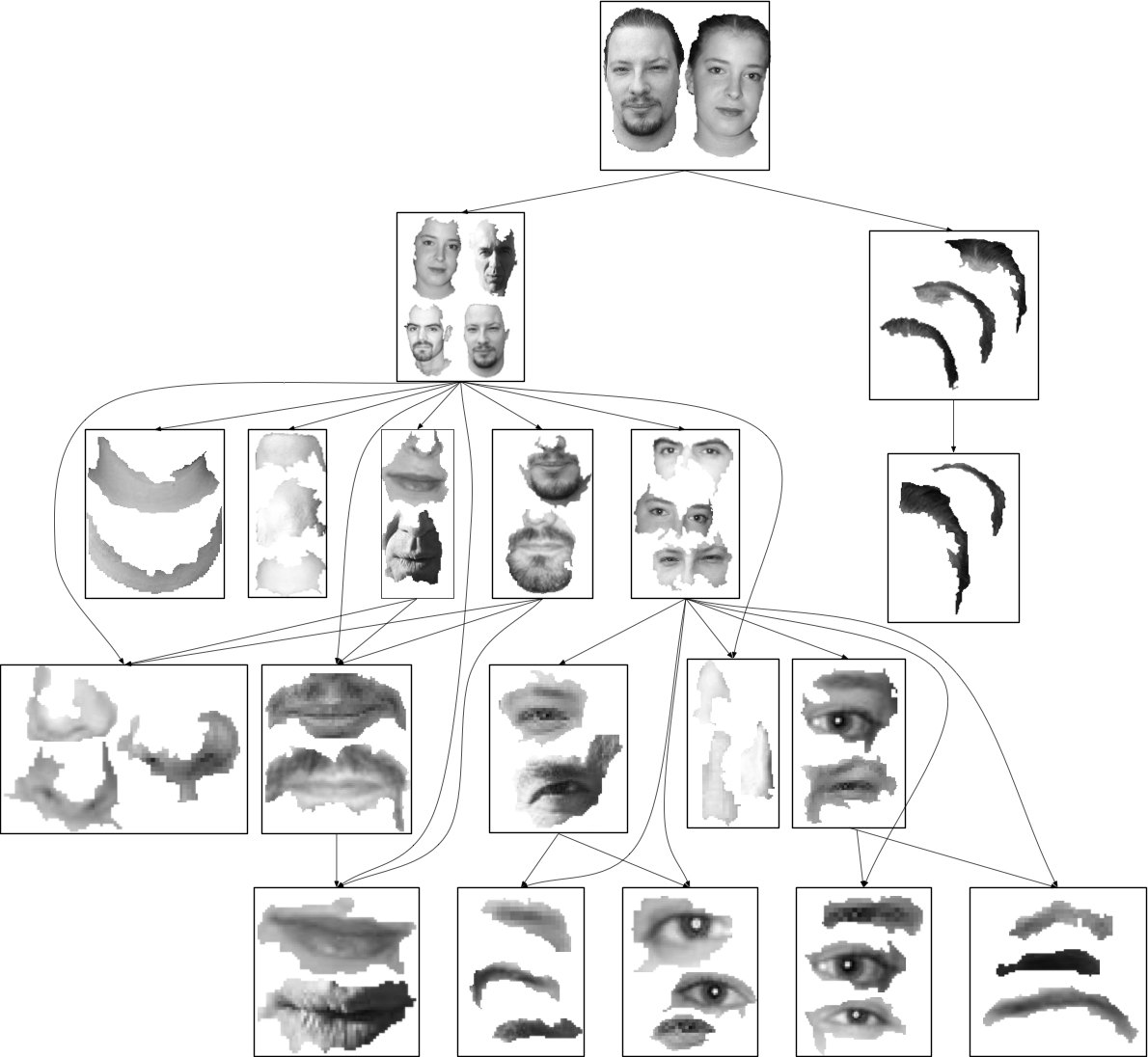
|
Given a set of
images containing frequent occurrences
of an unknown visual category, learn
geometric, photometric and topological
properties of regions defining the
category. Learning is unsupervised,
because the target category is not
defined by the user, and whether and
where any instances of the category
appear in a specific image is not known.
|
|


















































{kind=link}
{kind=link}