Abstracts
MoveIt! - A Board Game for Teaching Computer Science Concepts
Martin Erwig and Jennifer Parham-Mocello.
IEEE Conf. on Frontiers in Education
(FIE'25),
2025, to appear.
This innovative practice full paper introduces a new physical board game for teaching introductory computer science (CS) concepts. The game enjoys a number of important properties that make it a viable vehicle for the equitable teaching of CS. The game is:
- easy to create, as it requires only paper and a few tokens;
- non-competitive, as players collaborate to solve a challenge;
- easy to learn, as it has only a few simple rules;
- clearly linked to CS through a formal semantics.
Initial experiments in the classroom show that the game is universally engaging and effective in conveying computing concepts.
Explaining Results of Multi-Criteria Decision-Making
Martin Erwig and Prashant Kumar.
Journal of Multi-Criteria Decision Analysis Vol. 32, No. 1, 2025.
Transparency in computing is an important precondition to ensure the trust of users. One concrete way of delivering transparency is to provide explanations of computing results.
To this end, we introduce a method for explaining the results of various linear and hierarchical multi-criteria decision-making (MCDM) techniques such as the Weighted Sum Model (WSM) and the Analytic Hierarchy Process (AHP).
The two key ideas are (A) to maintain a fine-grained representation of the values manipulated by these techniques and (B) to derive explanations from these representations through merging, filtering, and aggregating operations.
An explanation in our model presents a high-level comparison of two alternatives in an MCDM problem, presumably an optimal and a non-optimal one, illuminating why one alternative was preferred over the other one.
We show the usefulness of our techniques by generating explanations for two well-known examples from the MCDM literature.
Finally, we show their efficacy by performing computational experiments.
Intersectional HCI on a Budget: An Analytical Approach Powered by Types
Abrar Fallatah, Md Montaser Hamid, Fatima Moussaoui, Chimdi Chikezie, Martin Erwig, Christopher Bogart, Anita Sarma, and Margaret Burnett.
International Journal of Human-Computer Interaction Vol. 41, No. 8, 1-24, 2025.
Intersectional HCI recognizes that humans' interconnected social identities shape their experiences with technology. However, intersectional HCI requires extensive resources, such as access to intersectional populations, which many HCI practitioners may lack. For these practitioners, we present an analytical approach to bring intersectional lenses to HCI practices. The approach uses types—not at the level of identities, but at the level of personal traits drawn from foundational research. We first formally prove that certain analytical methods for detecting inclusivity issues can be meaningfully composed to provide equitable consideration of typically overlooked populations; then present four design use-cases to illustrate what the approach brings to HCI practices; and then empirically investigated one of the four use-cases with 24 HCI participants. Results show that practitioners using the compositional approach detected even more intersectional inclusivity problems than those using a complementary intersectional approach.
Explanations for Combinatorial Optimization Problems
Martin Erwig and Prashant Kumar.
Journal of Computer Languages Vol. 79, 2024.
We introduce a representation for generating explanations for the outcomes of combinatorial optimization algorithms. The two key ideas are (A) to maintain fine-grained representations of the values manipulated by these algorithms and (B) to derive explanations from these representations through merge, filter, and aggregation operations. An explanation in our model presents essentially a high-level comparison of the solution to a problem with a hypothesized alternative, illuminating why the solution is better than the alternative. Our value representation results in explanations smaller than other dynamic program representations, such as traces. Based on a measure for the conciseness of explanations we demonstrate through a number of experiments that the explanations produced by our approach are small and scale well with problem size across a number of different applications.
Preprint.pdf
Analogies and Active Engagement: Introducing Computer Science
Jennifer Parham-Mocello, Martin Erwig, and Margaret Niess.
ACM Symp. on Computer Science Education
(SIGCSE'24),
1007-1013, 2024.
We describe a new introductory CS curriculum for middle schools that focuses on teaching CS concepts using the instructions and rules for playing simple, physical games. We deliberately avoid the use of technology and, in particular, programming, and we focus on games, such as tossing a coin to see who goes first and playing Tic-Tac-Toe. We report on middle-school students' understanding of basic CS concepts and their experiences with the curriculum.
After piloting the curriculum in 6th and 7th grade electives, we found that students liked the curriculum and using games, while some other students reported struggling with the technical content in the algorithm unit and vocabulary across the curriculum. Overall, students gained an understanding of abstraction and representation, and most students could define an algorithm and recognize a condition. However, they could not correctly organize the instructions of an algorithm.
Our results suggest that the non-coding, game-based curriculum engaged middle school students in basic CS concepts at the middle school level, but we believe there is room for improvement in delivering technical content and vocabulary related to algorithms.
MatchMaker: A DSL for Game-Theoretic Matching
Prashant Kumar and Martin Erwig.
Symp. on Trends in Functional Programming
(TFP'23),
LNCS 13868, 51-71, 2023
John McCarthy Best Paper Award
Existing tools for solving game-theoretic matching problems are limited in their expressiveness and can be difficult to use. In this paper, we introduce MatchMaker, a Haskell-based domain-specific embedded language (DSEL), which supports the direct, high-level repre- sentation of matching problems. Haskell’s type system, particularly the use of multi-parameter type classes, facilitates the definition of a highly general interface to matching problems, which can be rapidly instantiated for a wide variety of different matching applications. Additionally, as a novel contribution, MatchMaker provides combinators for dynamically updating and modifying problem representations, as well as for analyzing matching results.
Paper.pdf
A Visual Notation for Succinct Program Traces
Divya Bajaj, Martin Erwig, and Danila Fedorin.
Journal of Computer Languages Vol. 74, 2023.
Program traces are a widely used representation for explaining the dynamic behavior of programs. They help to make sense of computations and also support the location and elimination of bugs. Unfortunately, program traces can grow quite big very quickly, even for small programs, which compromises their usefulness.
In this paper we present a visual notation for program traces that supports their concise representation. We explain the design decisions of the notation and compare it in detail with several alternatives. An important part of the trace representation is its flexibility and adaptability, which allows users to transform traces by applying filters that capture common abstractions for trace representations.
We also present an evaluation of the trace notation and filters on a set of standard examples. The results show that our representation can reduce the overall size of traces by at least 79%, which suggests that our notation is an effective improvement over the use of plain traces in the explanation of dynamic program behavior.
Paper.pdf
Putting Computing on the Table: Using Physical Games to Teach Computer Science
Jennifer Parham-Mocello, Martin Erwig, Margaret Niess, Jason Weber, Madalyn Smith, and Garrett Berliner.
ACM Symp. on Computer Science Education
(SIGCSE'23),
444-450, 2023.
We describe a new introductory CS curriculum for middle schools that focuses on teaching CS concepts using the instructions and rules for playing simple, physical games. We deliberately avoid the use of technology and, in particular, programming, and we focus on games, such as tossing a coin to see who goes first and playing Tic-Tac-Toe. We report on middle-school students' understanding of basic CS concepts and their experiences with the curriculum.
After piloting the curriculum in 6th and 7th grade electives, we found that students liked the curriculum and using games, while some other students reported struggling with the technical content in the algorithm unit and vocabulary across the curriculum. Overall, students gained an understanding of abstraction and representation, and most students could define an algorithm and recognize a condition. However, they could not correctly organize the instructions of an algorithm.
Our results suggest that the non-coding, game-based curriculum engaged middle school students in basic CS concepts at the middle school level, but we believe there is room for improvement in delivering technical content and vocabulary related to algorithms.
Migrating Gradual Types
John Peter Campora III, Sheng Chen, Martin Erwig, and Eric Walkingshaw.
Journal of Functional Programming Vol. 32,
No. e14, 60 pages, 2022.
Gradual typing allows programs to enjoy the benefits of both static typing and dynamic typing. While it is often desirable to migrate a program from more dynamically typed to more statically typed or vice versa, gradual typing itself does not provide a way to facilitate this migration. This places the burden on programmers who have to manually add or remove type annotations. Besides the general challenge of adding type annotations to dynamically typed code, there are subtle interactions between these annotations in gradually typed code that exacerbate the situation. For example, to migrate a program to be as static as possible, in general, all possible combinations of adding or removing type annotations from parameters must be tried out and compared. In this paper, we address this problem by developing migrational typing, which efficiently types all possible ways of replacing dynamic types with fully static types for a gradually typed program. The typing result supports automatically migrating a program to be as static as possible or introducing the least number of dynamic types necessary to remove a type error. The approach can be extended to support user-defined criteria about which annotations to modify. We have implemented migrational typing and evaluated it on large programs. The results show that migrational typing scales linearly with the size of the program and takes only 2-4 times longer than plain gradual typing.
Paper.pdf
Using a Text-Based, Functional Board Game Language to Teach Middle School Programming
Jennifer Parham-Mocello, Martin Erwig, and Margaret Niess.
IEEE Conf. on Frontiers in Education
(FIE'22),
1-9, 2022.
In this work we report on middle school students' experiences while learning a new text-based, functional domain-specific teaching language for programming well-known, simple physical games, such as tossing a coin to see who goes first or playing Tic-Tac-Toe.
Based on students' responses after taking an 18-week, 7th grade elective, we find that the majority of the students like learning the new language because it is not block-based, it is not complicated, and it is in the domain of games. However, we also find that there are some students who say programming is what they like the least about the class, and the majority of the students report that they struggle the most with writing the syntax.
Overall, the majority of students like the curriculum, language, and using games as a way to explain CS concepts and teach programming. Even though learning a text-based, functional programming language may be difficult for middle-school students, these results show that the domain-specific teaching language is an effective teaching vehicle at the middle school level.
Exploring the Use of Games and a Domain-Specific Teaching Language in CS0
Jennifer Parham-Mocello, Aiden Nelson, and Martin Erwig.
ACM Conf. on Innovation and Technology in Computer Science Education
(ITiCSE'22),
351-357, 2022.
University students learning about computer science (CS) can be intimidated and frustrated by programming, and to make matters worse, the general-purpose programming languages chosen for introducing students to programming contain too many features that have the potential to overwhelm and distract students. We hypothesize that by using a delayed-coding approach with a language designed for teaching a smaller set of features focused on the fundamental CS concepts, such as types, values, conditions, control structures, and functions, student retention and success would improve, especially for those with no or little prior programming experience.
To test this hypothesis, we split a college computer science orientation class into two sections. One section began programming with a general-purpose language, Python, during week 1. The second section used a new, functional domain-specific teaching language themed around programming simple, well-known physical games. A group of researchers designed the new language with the purpose of giving students a more focused approach to learning basic computer science concepts and emphasizing good programming practices early, such as working with user-defined types and decomposition. Based on student survey responses before and after the two sections and their grades through the two subsequent CS courses, we find that students in the delayed-coding section using the new language had lower engagement in their class. In addition, we find no evidence of a higher pass rate for students from this section in their subsequent computer science courses.
Paper.pdf
MADMAX: A DSL for Explanatory Decision Making
Martin Erwig and Prashant Kumar.
ACM SIGPLAN Conf. on Generative Programming: Concepts & Experiences
(GPCE'21),
144-155, 2021
MADMAX is a Haskell-embedded DSL for multi-attribute, multi-layered decision making. An important feature of this DSL is the ability to generate explanations of why a computed optimal solution is better than its alternatives.
The functional approach and Haskell's type system support a high-level formulation of decision-making problems, which facilitates a number of innovations, including the gradual evolution and adaptation of problem representations, a more user-friendly form of sensitivity analysis based on problem domain data, and fine-grained control over explanations.
Paper.pdf
Adaptable Traces for Program Explanations
Divya Bajaj, Martin Erwig, Danila Fedorin, and Kai Gay.
Asian Symp. on Programming Languages and Systems
(APLAS'21),
LNCS 13008, 202-221, 2021.
Program traces are a sound basis for explaining the dynamic behavior of programs. Alas, program traces can grow big very quickly, even for small programs, which diminishes their value as explanations.
In this paper we demonstrate how the systematic simplification of traces can yield succinct program explanations. Specifically, we introduce operations for transforming traces that facilitate the abstraction of details. The operations are the basis of a query language for the definition of trace filters that can adapt and simplify traces in a variety of ways.
The generation of traces is governed by a variant of Call-By-Value semantics which specifically supports parsimony in trace representations. We show that our semantics is a conservative extension of Call-By-Value that can produce smaller traces and that the evaluation traces preserve the explanatory content of proof trees at a much smaller footprint.
Paper.pdf
Explainable Dynamic Programming
Martin Erwig and Prashant Kumar.
Journal of Functional Programming Vol. 31,
No. e10, 26 pages, 2021.
In this paper we present a method for explaining the results produced by dynamic programming algorithms. Our approach is based on retaining a granular representation of values that are aggregated during program execution. The explanations that are created from the granular representations can answer questions of why one result was obtained instead of another and therefore can increase the confidence in the correctness of program results.
Our focus on dynamic programming is motivated by the fact that dynamic programming offers a systematic approach to implementing a large class of optimization algorithms which produce decisions based on aggregated value comparisons. It is those decisions that the granular representation can help explain. Moreover, the fact that dynamic programming can be formalized using semirings supports the creation of a Haskell library for dynamic programming that has two important features.
First, it allows programmers to specify programs by recurrence relationships from which efficient implementations are derived automatically.
Second, the dynamic programs can be formulated generically (as type classes), which supports the smooth transition from programs that only produce result to programs that can run with granular representation and also produce explanations.
Finally, we also demonstrate how to anticipate user questions about program results and how to produce corresponding explanations automatically in advance.
Paper.pdf
A Visual Notation for Succinct Program Traces
Divya Bajaj, Martin Erwig, Danila Fedorin, and Kai Gay.
IEEE Int. Symp. on Visual Languages and Human-Centric Computing
(VL/HCC'21),
1-9, 2021.
Program traces are often used for explaining the dynamic behavior of programs. Unfortunately, program traces can grow quite big very quickly, even for small programs, which compromises their usefulness. In this paper we present a visual notation for program traces that supports their succinct representation, as well as their dynamic transformation through a structured query language.
An evaluation on a set of standard examples shows that our representation can reduce the overall size of traces by more than 80%, which suggests that our notation is an effective improvement over the use of plain traces in the explanation of dynamic program behavior.
Paper.pdf
Teaching CS Middle School Camps in a Virtual World
Jennifer Parham-Mocello, Martin Erwig, and Margaret Niess.
IEEE Int. Symp. on Visual Languages and Human-Centric Computing
(VL/HCC'21),
1-4, 2021.
We report our experiences with imple-menting two virtual computer science camps for middle school children. The camps use a two-part curriculum: One designed for 6th grade students using computer science concepts from familiar unplugged games, and the other targeted at 7th grade students using a domain-specific teaching language designed for programming board games.
We use the camps to pilot the curricular material and provide teachers with practical training to deliver the curriculum virtually. Due to the teachers’ commitment to finding successful strategies for delivering the curriculum online, the unplugged and programming activities worked surprisingly well in the remote environment. Overall, we found the use of well-known, unplugged games to be effective in preparing students to think algorithmically, and students were able to successfully code small programs for simple games in a new, functional, text-based language.
Paper.pdf
Reframing Middle School Mathematics Teachers' TPACK for Teaching A New Computer Science Curriculum: Researcher-Practitioner Partnership, Board Games, and Virtual Teaching Experiences
Margaret Niess, Jennifer Parham-Mocello, and Martin Erwig.
Int. Conf. of the Society for Information Technology & Teacher Education
(SITE'21),
1623-1631, 2021.
Recruiting teachers from diverse content specialties for teaching computer science (CS) in K-12 classrooms has been problematic. This first year of a 3-year project examined how a researcher-practitioner partnership (RPP) collaboration designed a new middle school CS curriculum using tabletop board games. The teachers planned and piloted the curriculum in 1-week, virtual learning CS camps. Research examined how the teachers’ knowledge for teaching CS was reframed as a result of their RPP experiences. This study examined this knowledge through four Technological Pedagogical Content Knowledge (TPACK) components: overarching conceptions about teaching CS; knowledge of students’ CS understandings; knowledge of curriculum materials; and knowledge of instructional strategies. Qualitative analyses revealed their knowledge was primarily influenced by their knowledge for teaching mathematics. Overarching conceptions of CS and student understandings limited the teachers' TPACK for CS placing them at the adapting TPACK level. These results directed the planning for the second year RPP efforts.
Paper.pdf
Does Story Programming Prepare for Coding?
Jennifer Parham-Mocello and Martin Erwig.
ACM Symp. on Computer Science Education
(SIGCSE'20),
100-106, 2020.
In this research study, we investigate the impact of using the Story Programming
approach to teach CS concepts on student performance in a subsequent C++ class.
In particular, we compare how students receiving little or no coding to learn
and apply these concepts perform in comparison to students who learn these
concepts only in the context of coding. While past research has shown that
exposure to programming is not a predictor of success in such courses, these
studies are based on a 15-week versus 10-week course and do not control for the
CS concepts and programming to which the students have been exposed.
Consequently, we hypothesize that students from the Story Programming approach
will perform worse in the following C++ class. Surprisingly, we find that this
is not true: Students from the Story Programming approach with little to no
coding do not significantly differ from their peers receiving a traditional
code-focused approach.
Paper.pdf
Explanations for Dynamic Programming
Martin Erwig, Prashant Kumar, and Alan Fern.
Int. Symp. on Practical Aspects of Declarative Languages
(PADL'20),
179-195, 2020.
We present an approach for explaining dynamic programming that is based on
computing with a granular representation of values that are typically aggregated
during program execution. We demonstrate how to derive more detailed and
meaningful explanations of program behavior from such a representation than
would otherwise be possible. To illustrate the practicality of this approach we
also present a Haskell library for dynamic programming that allows programmers
to specify programs by recurrence relationships from which implementations are
derived that can run with granular representation and produce explanations. The
explanations essentially answer questions of why one result was obtained instead
of another. While usually the alternatives have to be provided by a user, we
will show that with our approach such alternatives can be in some cases
anticipated and that corresponding explanations can be generated automatically.
Paper.pdf
Algorithms Aren't All Created Equal
Martin Erwig
(Popular Science),
September 13, 2019.
A recent poll found that most Americans think algorithms are unfair. But was the
poll itself biased?
Online Version
Usability of Probabilistic Programming Language
Alan F. Blackwell, Luke Church, Martin Erwig, James Geddes, Andy Gordon, Maria Gorinova, Atilim Gunes Baydin, Bradley Gram-Hansen, Tobias Kohn, Neil Lawrence, Vikash Mansinghka, Brooks Paige, Tomas Petricek, Diana Robinson, Advait Sarkar, and Oliver Strickson
30th Annual Workshop of the Psychology of Programming Interest Group
(PPIG'19),
1-19, 2019.
This discussion paper presents a conversation between researchers having active
interests in the usability of probabilistic programming languages (PPLs), but
coming from a wide range of technical and research perspectives. Although PPL
development is currently a vigorous and active research field, there has been
very little attention to date to basic questions in the psychology of
programming. Relevant issues include mental models associated with Bayesian
probability, end-user applications of PPLs, the potential for data-first
interaction styles, visualisation or explanation of model structure and solver
behaviour, and many others.
Paper.pdf
To Code or Not to Code? Programming in Introductory CS Courses
Jennifer Parham-Mocello, Martin Erwig, and Emily Dominguez
IEEE Int. Symp. on Visual Languages and Human-Centric Computing
(VL/HCC'19),
187-191, 2019.
Code-first approaches for introducing students to computer science (CS) can
exclude those without preparatory privilege in programming and those who are
intimidated by coding. Delaying coding or not using coding in an introductory CS
course can provide an equitable learning opportunity and include a broader group
of students in computational education. We use simple, well-known stories for
teaching computational and algorithmic thinking skills without the need for a
computer or coding. We present a research study that compares a traditional
Python code-first approach with an approach to delay or remove coding by first
using stories to explain computing. We find that there are a significant number
of students, especially females and those without prior programming experience,
without initial interest in coding and interested in using stories to explain
computing and non-coding activities to help them learn, motivate them to learn
more about CS. We conclude that offering a traditional Python code-first
approach excludes these students and an option that delays coding using stories
and Haskell is the best approach.
Paper.pdf
Explainable Reinforcement Learning via Reward Decomposition
Zoe Juozapaitis, Anurag Koul, Alan Ferm, Martin Erwig, and Finale Doshi-Velez
IJCAI/ECAI Workshop on Explainable Artificial Intelligence,
(XAI'19),
47-53, 2019.
We study reward decomposition for explaining the decisions of reinforcement
learning (RL) agents. The approach decomposes rewards into sums of semantically
meaningful reward types, so that actions can be compared in terms of trade-offs
among the types. In particular, we introduce the concept of minimum sufficient
explanations for compactly explaining why one action is preferred over another
in terms of the types. Prior RL algorithms for decomposed rewards produced
inconsistent decomposed values, which can be ill-suited to explanation. We
introduce an off-policy RL algorithm that provably converges to an optimal
policy and the correct decomposed action values. We illustrate the approach in a
number of domains, showing its utility for explanations.
Paper.pdf
Story Programming: Explaining Computer Science Before Coding
Jennifer Parham-Mocello, Shannon Ernst, Martin Erwig,
Emily Dominguez, and Lily Shellhammer.
ACM Symp. on Computer Science Education
(SIGCSE'19),
379-385, 2019.
Story Programming is an approach that teaches complex computational and
algorithmic thinking skills using simple stories anyone can relate to. One could
learn these skills independent of a computer or with the use of a computer as a
tool to interact with the computation in the tale. This research study examines
the use of Story Programming before teaching coding in a computer science
orientation course to determine if it is a viable alternative to the
code-focused way of teaching the class in the past. We measure the viability of
the new Story Programming approach by evaluating student-success and learning
outcomes, as well as student reactions to post-survey questions.
Paper.pdf
A Domain-Specific Language for Exploratory Data Visualization
Karl Smeltzer and Martin Erwig.
ACM SIGPLAN Conf. on Generative Programming: Concepts & Experiences
(GPCE'18),
1-13, 2018
With an ever-growing amount of collected data, the importance of visualization
as an analysis component is growing in concert. The creation of good
visualizations often doesn't happen in one step but is rather an iterative and
exploratory process. However, this process is currently not well supported in
most of the available visualization tools and systems. Visualization authors
are forced to commit prematurely to particular design aspects of their
creations, and when exploring potential variant visualizations, they are forced
to adopt ad hoc techniques such as copying code snippets or keeping a
collection of separate files.
We propose variational visualizations as a model supporting open-ended
exploration of the design space of information visualization. Together with
that model, we present a prototype implementation in the form of a
domain-specific language embedded in Purescript.
Paper.pdf
Paper.pdf
ACM Link (cid=N)
ACM Link (cid)
SIGCSE'23
Explaining Spreadsheets with Spreadsheets
Jacome Cunha, Mihai Dan, Martin Erwig, Danila Fedorin, and Alex Grejuc.
ACM SIGPLAN Conf. on Generative Programming: Concepts & Experiences
(GPCE'18),
161-167, 2018
Spreadsheets often change owners and have to be used by people who haven't
created the spreadsheet. This flux often contributes to a lack of
understanding, which is a major reason for mistakes in the use and maintenance
of spreadsheets.
Based on the concept of explanation sheets, we present an approach to make
spreadsheets easier to understand and thus easier to use and maintain.
We identify the notion of explanation soundness and show that explanation
sheets which conform to simple rules of formula coverage provide sound
explanations. We also present a practical evaluation of explanation sheets
based on samples drawn from widely used spreadsheet corpora and based on a
small user study.
In addition to supporting spreadsheet understanding and maintenance, our work
on explanation sheets has also uncovered several general principles of
explanation languages that can help guide the design of explanations for other
programming and domain-specific languages.
Paper.pdf
Comparative Visualizations through Parameterization and Variability
Karl Smeltzer and Martin Erwig.
IEEE Int. Symp. on Visual Languages and Human-Centric Computing
(VL/HCC'18),
7-15, 2018
Comparative visualizations and the comparison tasks they support constitute a
crucial part of visual data analysis on complex data sets. Existing
approaches are ad hoc and often require significant effort to produce
comparative visualizations, which is impractical especially in cases where
visualizations have to be amended in response to changes in the underlying
data.
We show that the combination of parameterized visualizations and variations
yields an effective model for comparative visualizations. Our approach
supports data exploration and automatic visualization updates when the
underlying data changes. We provide a prototype implementation and
demonstrate that our approach covers most of existing comparative
visualizations.
Paper.pdf
Typed Table Transformations
Martin Erwig.
Int. Workshop on Software Engineering Methods in Spreadsheets,
(SEMS'18),
2018
Spreadsheet tables are often labeled, and these labels effectively constitute
types for the data in the table. In such cases tables can be considered to be
built from typed data where the placement of values within the table is
controlled by the types used for rows and columns.
We present a new approach to the transformations of spreadsheet tables that is
based on transformations of row and column types.
We illustrate the basic idea of type-based table construction and
transformation and lay out a series of research questions that should be
addressed in future work.
Paper.pdf
Variational Pictures
Martin Erwig and Karl Smeltzer.
Int. Conf. on the Theory and Application of Diagrams,
(Diagrams'18),
LNAI 10871, 55-70, 2018
Diagrams and pictures are a powerful medium to communicate ideas, designs, and
art. However, authors of pictures are forced to use rudimentary and ad hoc
techniques in managing multiple variants of their creations, such as copying
and renaming files or abusing layers in an advanced graphical editing tool. We
propose a model of variational pictures as a basis for the design of editors
and other tools for managing variation in pictures. This model enjoys a
number of theoretical properties that support exploratory graphical design and
can help systematize picture creators' workflows.
Paper.pdf
Explaining Deep Adaptive Programs via Reward Decomposition
Martin Erwig, Alan Fern, Magesh Murali, and Anurag Koul.
IJCAI/ECAI Workshop on Explainable Artificial Intelligence,
(XAI'18),
40-44, 2018
Adaptation Based Programming (ABP) allows programmers to employ "choice points"
at program locations where they are uncertain about how to best code the program
logic. Reinforcement learning (RL) is then used to automatically learn to make
choice-point decisions to optimize the reward achieved by the program. In this
paper, we consider a new approach to explaining the learned decisions of
adaptive programs. The key idea is to include simple program annotations that
define multiple semantically meaningful reward types, which compose to define
the overall reward signal used for learning. Using these reward types we define
the notion of reward difference explanations (RDXs), which aim to explain why at
a choice point an alternative A was selected over another alternative B An RDX
gives the difference in the predicted future reward of each type when selecting
A versus B and then continuing to run the adaptive program. Significant
differences can provide insight into why A was or was not preferred to B. We
describe a SARSA-style learning algorithm for learning to optimize the choices
at each choice point, while also learning side information for producing RDXs.
We demonstrate this explanation approach through a case study in a synthetic
domain, which shows the general promise of the approach and highlights future
research questions.
Paper.pdf
Migrating Gradual Types
John P. Campora III, Sheng Chen, Martin Erwig, and Eric Walkingshaw.
Proc. of the ACM on Programming Languages, Vol. 2,
ACM SIGPLAN Symp. on Principles of Programming Languages
(POPL'18),
15:1-15:29, 2018
Gradual typing allows programs to enjoy the benefits of both static typing and
dynamic typing.
While it is often desirable to migrate a program from more dynamically-typed to
more statically-typed or vice versa, gradual typing itself does not provide a
way to facilitate this migration.
This places the burden on programmers who have to manually add or remove type
annotations. Besides the general challenge of adding type annotations to
dynamically typed code, there are subtle interactions between these annotations
in gradually typed code that exacerbate the situation. For example, to migrate
a program to be as static as possible, in general, all possible combinations of
adding or removing type annotations from parameters must be tried out and
compared.
In this paper, we address this problem by developing migrational typing,
which efficiently types all possible ways of adding or removing type
annotations from a gradually typed program. The typing result supports
automatically migrating a program to be as static as possible, or introducing
the least number of dynamic types necessary to remove a type error. The
approach can be extended to support user-defined criteria about which
annotations to modify.
We have implemented migrational typing and evaluated it on large programs.
The results show that migrational typing scales linearly with the size of the
program and takes only 2-4 times longer than plain gradual typing.
Systematic Identification and Communication of Type Errors
Sheng Chen and Martin Erwig.
Journal of Functional Programming Vol. 28,
No. e2, 1-48, 2018
When type inference fails, it is often difficult to pinpoint the cause of the
type error among many potential candidates. Generating informative messages to
remove the type error is another difficult task due to the limited availability
of type information. Over the last three decades many approaches have
been developed to help debug type errors. However, most of these methods suffer from one or more of the following problems:
(1) Being incomplete, they miss the real cause.
(2) They cover many potential causes without distinguishing them.
(3) They provide little or no information for how to remove the type error.
Any one of this problems can turn the type-error debugging process into a
tedious and ineffective endeavor.
To address this issue, we have developed a method named counter-factual
typing, which
(1) finds a comprehensive set of error causes in AST leaves,
(2)) computes an informative message on how to get rid of the type error for
each error cause, and
(3) ranks all messages and iteratively presents the message for
the most likely error cause.
The biggest technical challenge is the efficient generation of all error
messages, which seems to be exponential in the size of the expression. We
address this challenge by employing the idea of variational typing that
systematically reuses computations for shared parts and generates all messages
by typing the whole ill-typed expression only once.
We have evaluated our approach over a large set of examples collected from
previous publications in the literature. The evaluation result shows that our
approach outperforms previous approaches and is computationally feasible.
Paper.pdf
The Real Ghost in the Machine
Martin Erwig.
The World Today, October & November,
36-37, 2017
Algorithms are everywhere, and they affect everyone. As well as the obvious
places—computers, smart phones, cars and appliances—they also occur
outside of machines. A recipe is an example of such a machine-transcending
algorithm. So are pieces of music, evacuation plans, the instructions on how to
assemble furniture, card tricks and many other activities. If general interest
in science and technology is not a sufficient reason to learn about them, maybe
their omnipresence will persuade you.
Paper.pdf
Variational Lists: Comparisons and Design Guidelines
Karl Smeltzer and Martin Erwig.
ACM Int. Workshop on Feature-Oriented Software Development
(FOSD'17),
2017
Variation is widespread in software artifacts (data and programs) and in some
cases, such as software product lines, is widely studied. In order to
analyze, transform, or otherwise manipulate such variational software
artifacts, one needs a suitable data structure representation that incorporate
variation. However, relatively little work has focused on what effective
representations could be to support programming with variational data.
In this paper we explore how variational data can be represented and what the
implications and requirements are for corresponding variational data
structures. Due to the large design space, we begin by focusing on linked
lists. We discuss different variational linked-list representations and their
respective strengths and weaknesses. Based on our experience, we identify
some general design principles and techniques that can help with the
development of other variational data structures that are needed to make
variational programming practical.
Paper.pdf
Exploiting Diversity in Type Checkers for Better Error Messages
Sheng Chen, Martin Erwig, and Karl Smeltzer.
Journal of Visual Languages and Computing, Vol. 39,
10-21, 2017
Producing precise and helpful type error messages has been a challenge for the
implementations of functional programming languages for over 3 decades now.
Many different approaches and methods have been tried to solve this thorny
problem, but current type-error reporting tools still suffer from a lack of
precision in many cases. Based on the observation that different approaches
work well in different situations, we have studied the question of whether a
combination of tools that exploits their diversity can lead to improved
accuracy. Specifically, we have studied Helium, a Haskell implementation
particularly aimed at producing good type error messages, and Lazy Typing, an
approach developed previously by us to address the premature-error-commitment
problem in type checkers. By analyzing the respective strengths and weaknesses
of the two approaches we were able to identify a strategy to combine both
tools that could markedly improve the accuracy of reported errors.
Specifically, we report an evaluation of 1069 unique ill-typed programs out of
a total of 11256 Haskell programs that reveals that this combination strategy
enjoys a correctness rate of 82%, which is an improvement of 25%/20%
compared to using Lazy Typing/Helium alone. In addition to describing this
particular case study, we will also report insights we gained into the
combination of error-reporting tools in general.
Paper.pdf
What is a Visual Language?
Martin Erwig, Karl Smeltzer, and Xiangyu Wang.
Journal of Visual Languages and Computing, Vol. 38,
9-17, 2017
The visual language research community does not have a single, universally
agreed-upon definition of exactly what a visual language is. This is
surprising since the field of visual languages has been a vibrant research
area for over three decades now.
Disagreement about fundamental definitions can undermine a field, fragment the
research community, and potentially harm the research progress.
To address this issue we have analyzed two decades of VL/HCC publications to
clarify the concept of visual language as accepted by the VL/HCC
community, effectively adopting the approach of descriptive linguistics.
As a result we have obtained a succinct visual language ontology, which
captures the essential aspects of visual languages and which can be used to
characterize individual languages through visual language profiles. These
profiles can tell whether and in what sense a notation can be considered a
visual language.
We also report trends from and statistics about the field of visual languages.
Paper.pdf
A Calculus for Variational Programming
Sheng Chen, Martin Erwig, and Eric Walkingshaw.
European Conf. on Object-Oriented Programming
(ECOOP'16), LIPICS Vol. 56, 6:1-6:28,
2016.
Variation is ubiquitous in software. Many applications can benefit from making
this variation explicit, then manipulating and computing with it directly---a
technique we call variational programming. This idea has been independently
discovered in several application domains, such as efficiently analyzing and
verifying software product lines, combining bounded and symbolic
model-checking, and computing with alternative privacy profiles. Although these
domains share similar core problems, and there are also many similarities in
the solutions, there is no dedicated programming language support for
variational programming. This makes the various implementations tedious, prone
to errors, hard to maintain and reuse, and difficult to compare.
In this paper we present a calculus that forms the basis of a programming
language with explicit support for representing, manipulating, and computing
with variation in programs and data. We illustrate how such a language can
simplify the implementation of variational programming tasks. We present the
syntax and semantics of the core calculus, a sound type system, and a type
inference algorithm that produces principal types.
Paper.pdf [with corrections]
Principal Type Inference for GADTs
Sheng Chen and Martin Erwig.
ACM SIGPLAN-SIGACT Symp. on Principles of Programming Languages
(POPL'16),
416-428, 2016
We present a new method for GADT type inference that improves the precision of
previous approaches. In particular, our approach accepts more type-correct
programs than previous approaches when they do not employ type annotations. A
side benefit of our approach is that can detect a wide range of runtime errors
that are missed by previous approaches.
Our method is based on the idea to represent type refinements in
pattern-matching branches by choice types, which facilitate a separation of
the typing and reconciliation phases and thus support for case expressions.
This idea is formalized in a type system, which is both sound and a
conservative extension of the classical Hindley-Milner system. We present the
results of an empirical evaluation that compares our algorithm with previous
approaches.
Paper.pdf
Automatically Inferring Models from Spreadsheets
Jacome Cunha, Martin Erwig, Jorge Mendes, and Joao Saraiva.
Automated Software Engineering, Vol. 23,
No. 3, 361-392, 2016
Many errors in spreadsheet formulas can be avoided if spreadsheets are built
automatically from higher-level models that can encode and enforce consistency
constraints in the generated spreadsheets. Employing this strategy for legacy
spreadsheets is difficult, because the model has to be reverse engineered from
an existing spreadsheet and existing data must be transferred into the new
model-generated spreadsheet. We have developed and implemented a technique
that automatically infers relational schemas from spreadsheets. This technique
uses particularities from the spreadsheet realm to create better schemas. We
have evaluated this technique in two ways: first, we have demonstrated its
applicability by using it on a set of real-world spreadsheets. Second, we have
run an empirical study with users. The study has shown that the results
produced by our technique are comparable to the ones developed by experts
starting from the same (legacy) spreadsheet data. Although relational schemas
are very useful to model data, they do not fit spreadsheets well, as they do
not allow expressing layout. Thus, we have also introduced a mapping between
relational schemas and ClassSheets. A ClassSheet controls further changes to
the spreadsheet and safeguards it against a large class of formula errors. The
developed tool is a contribution to spreadsheet (reverse) engineering, because
it fills an important gap and allows a promising design method (ClassSheets)
to be applied to a huge collection of legacy spreadsheets with minimal effort.
Type-Based Parametric Analysis of Program Families
Sheng Chen and Martin Erwig.
ACM SIGPLAN Int. Conf. on Functional Programming
(ICFP'14),
39-51, 2014
Previous research on static analysis for program families has focused on
lifting analyses for single, plain programs to program families by employing
idiosyncratic representations. The lifting effort typically involves a
significant amount of work for proving the correctness of the lifted algorithm
and demonstrating its scalability.
In this paper, we propose a parameterized static analysis framework for program
families that can automatically lift a class of type-based static analyses for
plain programs to program families. The framework consists of a
parametric logical specification and a parametric variational constraint
solver. We prove that a lifted algorithm is correct provided that
the underlying analysis algorithm is correct.
An evaluation of our framework has revealed an error in a previous
"hand-lifted" analysis and indicates that the overhead incurred by the
general framework is bounded by a factor of 2.
Paper.pdf
Variational Data Structures: Exploring Tradeoffs in Computing with Variability
Eric Walkingshaw, Christian Kästner, Martin Erwig, Sven Apel, and Eric Bodden.
ACM SIGPLAN Int. Symp. on New Ideas, New Paradigms, and
Reflections on Programming & Software (Onward!)
(Onward'14),
213-226, 2014
Variation is everywhere, but in the construction and analysis of customizable
software it is paramount. In this context, there arises a need for
variational data structures for efficiently representing and computing
with related variants of an underlying data type.
So far, variational data structures have been explored and developed ad hoc.
This paper is a first attempt and a call to action for systematic and
foundational research in this area. Research on variational data structures
will benefit not only customizable software, but the many other application
domains that must cope with variability.
In this paper, we show how support for variation can be understood as a general
and orthogonal property of data types, data structures, and algorithms. We
begin a systematic exploration of basic variational data structures, exploring
the tradeoffs between different implementations. Finally, we retrospectively
analyze the design decisions in our own previous work where we have
independently encountered problems requiring variational data structures.
Let's Hear Both Sides: On Combining Type-Error Reporting Tools
Sheng Chen, Martin Erwig, and Karl Smeltzer
IEEE Int. Symp. on Visual Languages and Human-Centric Computing
(VL/HCC'14),
145-152, 2014
Producing precise and helpful type error messages has been a challenge for the
implementations of functional programming languages for over 3 decades
now. Many different approaches and methods have been tried to solve this
thorny problem, but current type-error reporting tools still suffer from a
lack of precision in many cases. Based on the rather obvious observation that
different approaches work well in different situations, we have studied the
question of whether a combination of tools that exploits their diversity can
lead to improved accuracy. Specifically, we have studied Helium, a Haskell
implementation particularly aimed at producing good type error messages, and
Lazy Typing, an approach developed previously by us to address the premature
error commitment problem in type checkers. By analyzing the respective
strengths and weaknesses of the two approaches we were able to identify a
strategy to combine both tools that could markedly improve the accuracy of
reported errors. Specifically, we report an evaluation of 1069 unique
ill-typed programs out of a total of 11256 Haskell programs that reveals that
this combination strategy enjoys a correctness rate of 79%, which is an
improvement of 22%/17% compared to using Lazy Typing/Helium alone. In
addition to describing this particular case study, we will also report
insights we gained into the combination of error-reporting tools in general.
Paper.pdf
A Notation for Non-Linear Program Edits
Martin Erwig and Karl Smeltzer, and Keying Xu
IEEE Int. Symp. on Visual Languages and Human-Centric Computing
(VL/HCC'14),
205-206, 2014
We present a visual notation to support the understanding and reasoning about
program edits. The graph-based representation directly supports a number of
editing operations beyond those offered by a typical, linear program-edit model
and makes obvious otherwise hidden states the code can reach through selectively
undoing or redoing changes.
Paper.pdf
A Transformational Approach to Data Visualization
Karl Smeltzer, Martin Erwig, and Ron Metoyer.
ACM SIGPLAN Conf. on Generative Programming: Concepts & Experiences
(GPCE'14),
53-62, 2014
Information visualization construction tools generally tend to fall in one of
two disparate categories. Either they offer simple but inflexible
visualization templates, or else they offer low-level graphical primitives
which need to be assembled manually. Those that do offer flexible,
domain-specific abstractions rarely focus on incrementally building and
transforming visualizations, which could reduce limitations on the style of
workflows supported. We present a Haskell-embedded DSL for data visualization
that is designed to provide such abstractions and transformations. This DSL
achieves additional expressiveness and flexibility through common functional
programming idioms and the Haskell type class hierarchy.
Paper.pdf
Guided Type Debugging
Sheng Chen and Martin Erwig.
Int. Symp. on Functional and Logic Programming
(FLOPS'14),
LNCS 8475, 35-51, 2014
We present guided type debugging as a new approach to quickly and reliably
remove type errors from functional programs. The method works by generating
type-change suggestions that satisfy type specifications that are elicited
from programmers during the debugging process. A key innovation is the
incorporation of target types into the type error debugging process.
Whereas previous approaches have aimed exclusively at the removal of type
errors and disregarded the resulting types, guided type debugging exploits
user feedback about result types to achieve better type-change suggestions.
Our method can also identify and remove errors in type annotations, which has
been a problem for previous approaches. To efficiently implement our approach,
we systematically generate all potential type changes and arrange them in a
lattice structure that can be efficiently traversed when guided by target
types that are provided by programmers.
Paper.pdf
Counter-Factual Typing for Debugging Type Errors
Sheng Chen and Martin Erwig.
ACM SIGPLAN-SIGACT Symp. on Principles of Programming Languages
(POPL'14),
583-594, 2014
Changing a program in response to a type error plays an important
part in modern software development. However, the generation of good
type error messages remains a problem for highly expressive type
systems.
Existing approaches often suffer from a lack of precision in locating errors
and proposing remedies. Specifically, they either fail to locate the source of
the type error consistently, or they report too many potential error
locations. Moreover, the change suggestions offered are often incorrect. This
makes the debugging process tedious and ineffective.
We present an approach to the problem of type debugging that is based on
generating and filtering a comprehensive set of type-change suggestions.
Specifically, we generate all (program-structure-preserving) type
changes that can possibly fix the type error. These suggestions will be ranked
and presented to the programmer in an iterative fashion. In some cases we
also produce suggestions to change the program.
In most situations, this strategy delivers the correct change suggestions
quickly, and at the same time never misses any rare suggestions.
The computation of the potentially huge set of type-change suggestions is
efficient since it is based on a variational type inference algorithm that
type checks a program with variations only once, efficiently reusing type
information for shared parts.
We have evaluated our method and compared it with previous approaches. Based
on a large set of examples drawn from the literature, we have found that our
method outperforms other approaches and provides a viable alternative.
Paper.pdf
Early Detection of Type Errors in C++ Templates
Sheng Chen and Martin Erwig.
ACM SIGPLAN Workshop on Partial Evaluation and Program Manipulation
(PEPM'14),
133-144, 2014
Current C++ implementations typecheck templates in two phases:
Before instantiation, those parts of the template are checked that do
not depend on template parameters, while the checking of the remaining parts
is delayed until template instantiation time when the template arguments
become available. This approach is problematic because it causes two major
usability problems. First, it prevents library developers to provide
guarantees about the type correctness for modules involving templates. Second,
it can lead, through the incorrect use of template functions, to inscrutable
error messages. Moreover, errors are often reported far away from the source
of the program fault.
To address this problem, we have developed a type system for Garcia's
type-reflective calculus that allows a more precise characterization of types
and thus a better utilization of type information within template definitions.
This type system allows the static detection of many type errors that could
previously only be detected after template instantiation. The additional
precision and earlier detection time is achieved through the use of so-called
"choice types" and corresponding typing rules that support the static reasoning about
underspecified template types. The main contribution of this paper is a
guarantee of the type safety of C++ templates (general definitions with
specializations) since we can show that well-typed templates only generate
well-typed object programs.
Paper.pdf
Extending Type Inference to Variational Programs
Sheng Chen, Martin Erwig, and Eric Walkingshaw.
ACM Transactions on Programming Languages and Systems, Vol. 36,
No. 1, 1:1-1:54, 2014
Through the use of conditional compilation and related tools, many software
projects can be used to generate a huge number of related programs.
The problem of typing such variational software is difficult. The brute-force
strategy of generating all variants and typing each one individually is (1)
usually infeasible for efficiency reasons and (2) produces results that do not
map well to the underlying variational program.
Recent research has focused mainly on efficiency and addressed only the problem
of type checking. In this work we tackle the more general problem of
variational type inference and introduce variational types to represent the
result of typing a variational program.
We introduce the variational lambda calculus (VLC) as a formal foundation for
research on typing variational programs. We define a type system for VLC in
which VLC expressions are mapped to correspondingly variational types.
We show that the type system is correct by proving that the typing of
expressions is preserved over the process of variation elimination, which
eventually results in a plain lambda calculus expression and its corresponding
type.
We identify a set of equivalence rules for variational types and prove that the
type unification problem modulo these equivalence rules is unitary and
decidable; we also present a sound and complete unification algorithm.
Based on the unification algorithm, the variational type inference algorithm is
an extension of algorithm W. We show that it is sound and complete and
computes principal types. We also consider the extension of VLC with sum
types, a necessary feature for supporting variational data types, and
demonstrate that the previous theoretical results also hold under this
extension.
Finally, we characterize the complexity of variational type inference and
demonstrate the efficiency gains over the brute-force strategy.
Paper.pdf
An Abstract Representation of Variational Graphs
Martin Erwig, Eric Walkingshaw, and Sheng Chen.
ACM Int. Workshop on Feature-Oriented Software Development
(FOSD'13),
25-32, 2013
In the context of software product lines, there is often a need to represent
graphs containing variability. For example, extending traditional modeling
techniques or program analyses to variational software requires a corresponding
notion of variational graphs.
In this paper, we introduce a general model of variational graphs and a
theoretical framework for discussing variational graph algorithms.
Specifically, we present an abstract syntax based on tagging for succinctly
representing variational graphs and other data types relevant to variational
graph algorithms, such as variational sets and paths.
We demonstrate how (non-variational) graph algorithms can be generalized to
operate on variational graphs, to accept variational inputs, and produce
variational outputs. Finally, we discuss a filtering operation on variational
graphs and how this interacts with variational graph algorithms.
Paper.pdf
A Visual Language for Explaining Probabilistic Reasoning
Martin Erwig and Eric Walkingshaw.
Journal of Visual Languages and Computing, Vol. 24,
No. 2, 88-109, 2013
We present an explanation-oriented, domain-specific, visual language for
explaining probabilistic reasoning. Explanation-oriented programming is a new
paradigm that shifts the focus of programming from the computation of results
to explanations of how those results were computed. Programs in this language
therefore describe explanations of probabilistic reasoning problems.
The language relies on a story-telling metaphor of explanation, where the
reader is guided through a series of well-understood steps from some initial
state to the final result.
Programs can also be manipulated according to a set of laws to automatically
generate equivalent explanations from one explanation instance. This increases
the explanatory value of the language by allowing readers to cheaply derive
alternative explanations if they do not understand the first.
The language is comprised of two parts: a formal textual notation for specifying
explanation-producing programs and the more elaborate visual notation for
presenting those explanations. We formally define the abstract syntax of
explanations and define the semantics of the textual notation in terms of the
explanations that are produced.
Paper.pdf
Adding Configuration to the Choice Calculus
Martin Erwig, Klaus Ostermann, Tillmann Rendel, and Eric Walkingshaw.
ACM Int. Workshop on Variability Modelling of Software-Intensive Systems
(VAMOS'13),
13:1-13:8, 2013
The choice calculus, a formal language for representing variation in software
artifacts, features syntactic forms to map dimensions of variability
to local choices between source code variants.
However, the process of selecting alternatives from dimensions was relegated
to an external operation. The lack of a syntactic form for
selection precludes many interesting variation and reuse
patterns, such as nested product lines, and theoretical results,
such as a syntactic description of the configuration process.
In this paper we add a selection operation to the choice calculus and
illustrate how that increases the expressiveness of the calculus. We
investigate some alternative semantics of this operation and study their
impact and utility. Specifically, we will examine selection in the context of
static and dynamically scoped dimension declarations, as a well as a linear
and comprehensive form of dimension elimination. We also present a design for a type
system to ensure configuration safety and modularity of nested product lines.
Paper.pdf
Variation Programming with the Choice Calculus
Martin Erwig and Eric Walkingshaw.
Generative and Transformational Techniques in Software Engineering
(GTTSE),
LNCS 7680, 55-100, 2013
The choice calculus provides a language for representing and transforming
variation in software and other structured documents. Variability is captured
in localized choices between alternatives. The space of all variations is
organized by dimensions, which provide scoping and structure to choices. The
variation space can be reduced through a process of selection, which
eliminates a dimension and resolves all of its associated choices by replacing
each with one of their alternatives. The choice calculus also allows the
definition of arbitrary functions for the flexible construction and
transformation of all kinds of variation structures. In this tutorial we will
first present the motivation, general ideas, and principles that underlie the
choice calculus. This is followed by a closer look at the semantics.
We will then present practical applications based on several small example
scenarios and consider the concepts of "variation programming" and "variation
querying". The practical applications involve work with a Haskell library that
supports variation programming and experimentation with the choice calculus.
Paper.pdf
An Error-Tolerant Type System for Variational Lambda Calculus
Sheng Chen, Martin Erwig, and Eric Walkingshaw.
ACM SIGPLAN Int. Conf. on Functional Programming
(ICFP'12),
29-40, 2012
Conditional compilation and software product line technologies make it possible
to generate a huge number of different programs from a single software project.
Typing each of these programs individually is usually impossible due to the
sheer number of possible variants.
Our previous work has addressed this problem with a type system for variational
lambda calculus (VLC), an extension of lambda calculus with basic constructs
for introducing and organizing variation. Although our type inference
algorithm is more efficient than the brute-force strategy of inferring the
types of each variant individually, it is less robust since type inference will
fail for the entire variational expression if any one variant contains a type
error. In this work, we extend our type system to operate on VLC expressions
containing type errors. This extension directly supports locating ill-typed
variants and the incremental development of variational programs. It also has
many subtle implications for the unification of variational types. We show
that our extended type system possesses a principal typing property and that
the underlying unification problem is unitary. Our unification algorithm
computes partial unifiers that lead to result types that (1) contain errors in
as few variants as possible and (2) are most general.
Finally, we perform an empirical evaluation to determine the overhead of this
extension compared to our previous work, to demonstrate the improvements over
the brute-force approach, and to explore the effects of various error
distributions on the inference process.
Paper.pdf
Surveyor: A DSEL for Representing and Analyzing Strongly Typed Surveys
Wyatt Allen and Martin Erwig.
ACM SIGPLAN Haskell Symposium
(Haskell'12),
81-90, 2012
Polls and surveys are increasingly employed to gather information about
attitudes and experiences of all kinds of populations and user groups. The
ultimate purpose of a survey is to identify trends and relationships
that can inform decision makers. To this end, the data gathered by a
survey must be appropriately analyzed.
Most of the currently existing tools focus on the user interface aspect of the
data collection task, but pay little attention to the structure and type of
the collected data, which are usually represented as potentially
tag-annotated, but otherwise unstructured, plain text. This makes the task of
writing data analysis programs often difficult and error-prone, whereas a
typed data representation could support the writing of type-directed data
analysis tools that would enjoy the many benefits of static typing.
In this paper we present Surveyor, a DSEL that allows the compositional
construction of typed surveys, where the types describe the structure of the
data to be collected. A survey can be run to gather typed data, which can then
be subjected to analysis tools that are built using Surveyor's typed
combinators. Altogether the Surveyor DSEL realizes a strongly typed and
type-directed approach to data gathering and analysis.
The implementation of our DSEL is based on GADTs to allow a flexible, yet
strongly typed representation of surveys. Moreover, the implementation employs
the Scrap-Your-Boilerplate library to facilitate the type-dependent traversal,
extraction, and combination of data gathered from surveys.
Paper.pdf (462K)
A Calculus for Modeling and Implementing Variation
Eric Walkingshaw and Martin Erwig.
ACM SIGPLAN Conf. on Generative Programming and Component Engineering
(GPCE'12),
132-140, 2012
We present a formal calculus for modeling and implementing
variation in software. It unifies the compositional and annotative approaches
to feature implementation and supports the development of abstractions that can
be used to directly relate feature models to their implementation.
Since the compositional and annotative approaches are complementary,
the calculus enables implementers to use the best combination of tools
for the job and focus on inherent feature interactions, rather than those
introduced by biases in the representation. The calculus also supports the
abstraction of recurring variational patterns and provides a metaprogramming
platform for organizing variation in artifacts.
Paper.pdf
Faster Program Adaptation Through Reward Attribution Inference
Tim Bauer, Martin Erwig, Alan Fern, and Jervis Pinto.
ACM SIGPLAN Conf. on Generative Programming and Component Engineering
(GPCE'12),
103-111, 2012
In the adaptation-based programming (ABP) paradigm, programs may contain
variable parts (function calls, parameter values, etc.) that can be
take a number of different values. Programs also contain reward
statements with which a programmer can provide feedback about how well a
program is performing with respect to achieving its goals (for example,
achieving a high score on some scale).
By repeatedly running the program, a machine learning component will, guided
by the rewards, gradually adjust the automatic choices made in the
variable program parts so that they converge toward an optimal strategy.
ABP is a method for semi-automatic program generation in which the choices and
rewards offered by programmers allow standard machine-learning techniques to
explore a design space defined by the programmer to find an optimal instance
of a program template.
ABP effectively provides a DSL that allows non-machine learning experts to
exploit machine learning to generate self-optimizing programs.
Unfortunately, in many cases the placement and structuring of choices and
rewards can have a detrimental effect on how an optimal solution to a
program-generation problem can be found.
To address this problem, we have developed a dataflow analysis that computes
influence tracks of choices and rewards. This information can be exploited by
an augmented machine-learning technique to ignore misleading rewards and to
generally attribute rewards better to the choices that have actually
influenced them.
Moreover, this technique allows us to detect errors in the adaptive program
that might arise out of program maintenance.
Our evaluation shows that the dataflow analysis can lead to improvements
in performance.
Paper.pdf
Semantics-Driven DSL Design
Martin Erwig and Eric Walkingshaw.
Formal and Practical Aspects of Domain-Specific Languages: Recent Developments,
(ed. M. Mernik),
56-80, 2012
Convention dictates that the design of a language begins with its syntax. We
argue that early emphasis should be placed instead on the identification of
general, compositional semantic domains, and that grounding the design process
in semantics leads to languages with more consistent and more extensible
syntax. We demonstrate this semantics-driven design process through the
design and implementation of a DSL for defining and manipulating calendars,
using Haskell as a metalanguage to support this discussion. We emphasize the
importance of compositionality in semantics-driven language design, and
describe a set of language operators that support an incremental and modular
design process.
Paper.pdf
Lightweight Automated Testing with Adaptation-Based Programming
Alex Groce, Alan Fern, Jervis Pinto, Tim Bauer, Amin Alipour,
Martin Erwig, and Camden Lopez.
IEEE Int. Symp. on Software Reliability Engineering
(ISSRE'12),
2012
This paper considers the problem of testing a container class or other
modestly-complex API-based software system. Past experimental evaluations
have shown that for many such modules, random testing and shape abstraction
based model checking are effective. These approaches have proven attractive
due to a combination of minimal require- ments for tool/language support,
extremely high usability, and low overhead. These "lightweight" methods are
therefore available for almost any programming language or environment, in
contrast to model checkers and concolic testers. Unfortunately, for the cases
where random testing and shape abstraction perform poorly, there have been
few alternatives available with such wide applicability. This paper presents
a generalizable approach based on reinforcement learning (RL), using
adaptation-based programming (ABP) as an interface to make RL-based testing
(almost) as easy to apply and adaptable to new languages and environments as
random testing. We show that learned tests differ from random ones, and
propose a model for why RL works in this unusual (by RL standards) setting,
in the context of a detailed large-scale experimental evaluation of
lightweight automated testing methods.
Paper.pdf
Learning-Based Test Programming for Programmers
Alex Groce, Alan Fern, Martin Erwig, Jervis Pinto,
Tim Bauer, and Amin Alipour.
Int. Symp. on Leveraging Applications of Formal Methods,
Verification, and Validation
(ISOLA'12),
LNCS 7609, 582-586, 2012
While a diverse array of approaches to applying machine learning to testing
has appeared in recent years, many efforts share three central challenges, two
of which are not always obvious. First, learning-based testing relies on
adapting the tests generated to the program being tested, based on the results
of observed executions. This is the heart of a machine learning approach to
test generation. A less obvious challenge in many approaches is that the
learning techniques used may have been devised for problems that do not share
all the assumptions and goals of software testing. Finally, the usability of
approaches by programmers is a challenge that has often been neglected.
Programmers may wish to maintain more control of test generation than a "push
button" tool generally provides, without becoming experts in software testing
theory or machine learning algorithms, and with access to the full power of
the language in which the tested system is written. In this paper we consider
these issues, in light of our experience with adaptation-based programming as
a method for automated test generation.
Paper.pdf
Systematic Evolution of Model-Based Spreadsheet Applications
Markus Luckey, Martin Erwig, and Gregor Engels.
Journal of Visual Languages and Computing, Vol. 23,
No. 5, 267-286, 2012
Using spreadsheets is the preferred method to calculate, display or store
anything that fits into a table-like structure. They are often used by end
users to create applications, although they have one critical
drawback - spreadsheets are very error-prone. Recent research has developed
methods to reduce this error-proneness by introducing a new way of
object-oriented modeling of spreadsheets before using them. These spreadsheet
models, termed ClassSheets, are used to generate concrete spreadsheets on the
instance level. By this approach sources of errors are reduced and spreadsheet
applications become easier to understand. As usual for almost every other
application, requirements on spreadsheets change due to the changing
environment. Thus, the problem of evolution of spreadsheets arises. The update
and evolution of spreadsheets is the uttermost source of errors that may have
severe impact. In this article, we will introduce a model-based approach to
spreadsheet evolution by propagating updates on spreadsheet models (i.e.
ClassSheets) to spreadsheets. To this end, update commands for the ClassSheet
layer are automatically transformed to those for the spreadsheet layer. We
describe spreadsheet model update propagation using a formal framework and
present an integrated tool suite that allows the easy creation and safe update
of spreadsheet models. The presented approach greatly contributes to the
problem of software evolution and maintenance for spreadsheets and thus avoids
many errors that might have severe impacts.
Paper.pdf
Finding Common Ground: Choose, Assert, and Assume
Alex Groce and Martin Erwig.
Int. Workshop on Dynamic Analysis
(WODA'12),
12-17, 2012
At present, the "testing community" is on good speaking terms, but typically
lacks a common language for expressing some computational ideas, even in cases
where such a language would be both useful and plausible. In particular, a
large body of testing systems define a testing problem in the language of the
system under test, extended with operations for choosing inputs, asserting
properties, and constraining the domain of executions considered. While the
underlying algorithms used for "testing" include symbolic execution,
explicit-state model checking, machine learning, and "old fashioned" random
testing, there seems to be a common core of expressive need. We propose that
the dynamic analysis community could benefit from working with some common
syntactic (and to some extent semantic) mechanisms for expressing a body of
testing problems. Such a shared language would have immediate practical uses
and make cross-tool comparisons and research into identifying appropriate
tools for different testing activities easier. We also suspect that
considering the more abstract testing problem arising from this minimalist
common ground could serve as a basis for thinking about the design of usable
embedded domain-specific languages for testing and might help identify
computational patterns that have escaped the notice of the community.
Paper.pdf
Explanations for Regular Expressions
Martin Erwig and Rahul Gopinath.
Int. Conf. on Fundamental Approaches to Software Engineering
(FASE'12),
LNCS 7212, 394-408, 2012
Regular expressions are widely used, but they are inherently hard to
understand and (re)use, which is primarily due to the lack of abstraction
mechanisms that causes regular expressions to grow large very quickly. The
problems with understandability and usability are further compounded by the
viscosity, redundancy, and terseness of the notation. As a consequence, many
different regular expressions for the same problem are floating around, many
of them erroneous, making it quite difficult to find and use the right regular
expression for a particular problem. Due to the ubiquitous use of regular
expressions, the lack of understandability and usability becomes a serious
software engineering problem.
In this paper we present a range of independent, complementary representations
that can serve as explanations of regular expressions. We provide methods to
compute those representations, and we describe how these methods and the
constructed explanations can be employed in a variety of usage scenarios. In
addition to aiding understanding, some of the representations can also help
identify faults in regular expressions. Our evaluation shows that our methods
are widely applicable and can thus have a significant impact in improving
the practice of software engineering.
Paper.pdf
The Choice Calculus: A Representation for Software Variation
Martin Erwig and Eric Walkingshaw.
ACM Transactions on Software Engineering and Methodology, Vol. 21,
No. 1, 6:1-6:27, 2011
Many areas of computer science are concerned with some form of variation in
software - from managing changes to software over time, to supporting families
of related artifacts.
We present the choice calculus, a fundamental
representation for software variation that can serve as a common language of
discourse for variation research, filling a role similar to the lambda calculus
in programming language research. We also develop an associated theory of
software variation, including sound transformations of variation artifacts, the
definition of strategic normal forms, and a design theory for variation
structures, which will support the development of better algorithms and tools.
Paper.pdf
Semantics First! Rethinking the Language Design Process
Martin Erwig and Eric Walkingshaw.
Int. Conf. on Software Language Engineering
(SLE'11),
LNCS 6940, 243-262, 2011
The design of languages is still more of an art than an engineering
discipline. Although recently tools have been put forward to support the
language design process, such as language workbenches, these have mostly
focused on a syntactic view of languages. While these tools are quite helpful
for the development of parsers and editors, they provide little support for
the underlying design of the languages.
In this paper we illustrate how to support the design of languages by focusing
on their semantics first. Specifically, we will show that powerful and general
language operators can be employed to adapt and grow sophisticated languages
out of simple semantics concepts.
We use Haskell as a metalanguage and will associate generic language concepts,
such as semantics domains, with Haskell-specific ones, such as data types. We
do this in a way that clearly distinguishes our approach to language design
from the traditional syntax-oriented one.
This will reveal some unexpected correlations, such as viewing type classes as
language multipliers.
We illustrate the viability of our approach with several real-world examples.
Paper.pdf
A DSEL for Studying and Explaining Causation
Eric Walkingshaw and Martin Erwig.
IFIP Working Conference on Domain Specific Languages
(DSL'11),
143-167, 2011
We present a domain-specific embedded language (DSEL) in Haskell that supports
the philosophical study and practical explanation of causation. The language
provides constructs for modeling situations comprised of events and functions
for reliably determining the complex causal relation- ships that emerge
between these events. It enables the creation of visual explanations of these
causal relationships and a means to systematically generate alternative,
related scenarios, along with corresponding outcomes and causes. The DSEL is
based on neuron diagrams, a visual notation that is well established in
practice and has been successfully employed for causation explanation and
research. In addition to its immediate applicability by users of neuron
diagrams, the DSEL is extensible, allowing causation experts to extend the
notation to introduce special-purpose causation constructs. The DSEL also
extends the notation of neuron diagrams to operate over non-boolean values,
improving its expressiveness and offering new possibilities for causation
research and its applications.
Paper.pdf
Adaptation-Based Programming in Haskell
Tim Bauer, Martin Erwig, Alan Fern, and Jervis Pinto.
IFIP Working Conference on Domain Specific Languages
(DSL'11),
1-23, 2011
We present an embedded DSL to support adaptation-based programming (ABP)
in Haskell. ABP is an abstract model for defining adaptive values,
which adapt in response to some associated feedback.
We show how our design choices in Haskell motivate higher-level combinators
and constructs and help us derive more complicated compositional adaptives.
We also show an important specialization of ABP is in support of
reinforcement learning constructs, which optimize adaptive values based
on a programmer-specified objective function. This permits ABP users to easily
define adaptive values that express uncertainty anywhere in their programs.
Over repeated executions, these adaptive values adjust to more optimal ones
allow the user's programs to self optimize.
The design of our DSL depends significantly on the use of type classes.
We will illustrate, along with presenting our DSL, how the use of type
classes can support the gradual evolution of DSLs.
Paper.pdf
Improving Policy Gradient Estimates with Influence Information
Jervis Pinto, Alan Fern, Tim Bauer, and Martin Erwig.
Asian Conference on Machine Learning and Applications,
1-16, 2011
In reinforcement learning (RL) it is often possible to obtain sound, but
incomplete, information about influences and independencies among problem
variables and rewards, even when an exact domain model is unknown. For
example, such information can be computed based on a partial, qualitative
domain model, or via domain-specific analysis techniques. While, intuitively,
such information appears useful for RL, there are no algorithms that
incorporate it in a sound way. In this work, we describe how to leverage such
information for improving the estimation of policy gradients, which can be
used to speedup gradient-based RL. We prove general conditions under which our
estimator is unbiased and show that it will typically have reduced variance
compared to standard unbiased gradient estimates. We evaluate the approach in
the domain of Adaptation-Based Programming where RL is used to optimize the
performance of programs and independence information can be computed via
standard program analysis techniques. Incorporating independence information
produces a large speedup in learning on a variety of adaptive programs.
Paper.pdf
#ifdef Confirmed Harmful: Promoting Understandable Software Variation
Duc Le, Eric Walkingshaw, and Martin Erwig.
IEEE Int. Symp. on Visual Languages and Human-Centric Computing
(VL/HCC'11),
143-150, 2011
Maintaining variation in software is a difficult problem that poses serious
challenges for the understanding and editing of software artifacts.
Although the C preprocessor (CPP) is often the default tool used to introduce
variability to software, because of its simplicity and flexibility, it is
infamous for its obtrusive syntax and has been blamed for reducing the
comprehensibility and maintainability of software.
In this paper, we address this problem by developing a prototype for managing
software variation at the source code level. We evaluate the difference
between our prototype and CPP with a user study, which indicates that the prototype
helps users reason about variational code faster and more accurately than CPP.
Our results also support the research of others, providing evidence for the
effectiveness of related tools, such as CIDE and FeatureCommander.
Paper.pdf
Optimizing the Product Derivation Process
Sheng Chen and Martin Erwig.
IEEE Int. Software Product Line Conference
(SPLC'11),
35-44, 2011
Feature modeling is widely used in software product-line engineering to
capture the commonalities and variabilities within an application domain. As
feature models evolve, they can become very complex with respect to the number
of features and the dependencies among them, which can cause the product
derivation based on feature selection to become quite time consuming and error
prone.
We address this problem by presenting techniques to find good feature
selection sequences that are based on the number of products that contain a
particular feature and the impact of a selected feature on the selection of
other features. Specifically, we identify a feature selection strategy, which
brings up highly selective features early for selection. By prioritizing
feature selection based on the selectivity of features our technique makes the
feature selection process more efficient. Moreover, our approach helps with
the problem of unexpected side effects of feature selection in later stages of
the selection process, which is commonly considered a difficult problem. Our
evaluation results demonstrate that with the help of our techniques the
feature selection processes can be reduced significantly.
Paper.pdf
Adaptation-Based Programming in Java
Tim Bauer, Martin Erwig, Alan Fern, and Jervis Pinto.
ACM SIGPLAN Workshop on Partial Evaluation and Program Manipulation
(PEPM'11),
81-90, 2011
Writing deterministic programs is often difficult for problems whose optimal
solutions depend on unpredictable properties of the programs' inputs.
Difficulty is also encountered for problems where the programmer is uncertain
about how to best implement certain aspects of a solution. For such problems a
mixed strategy of deterministic programming and machine learning can often be
very helpful: Initially, define those parts of the program that are well
understood and leave the other parts loosely defined through default actions,
but also define how those actions can be improved depending on results from
actual program runs. Then run the program repeatedly and let the loosely
defined parts adapt.
In this paper we present a library for Java that facilitates this style of
programming, called \emph{adaptation-based programming}. We motivate the
design of the library, define the semantics of adaptation-based programming,
and demonstrate through two evaluations that the approach works well in
practice.
Adaptation-based programming is a form of program generation in which the
creation of programs is controlled by previous runs. It facilitates a whole
new spectrum of programs between the two extremes of totally deterministic
programs and machine learning.
Paper.pdf
The State of the Art in End-User Software Engineering
A. J. Ko, R. Abraham, L. Beckwith, A. Blackwell, M. M.
Burnett, M. Erwig, J. Lawrence, C. Scaffidi, H. Lieberman, B. Myers, M. B.
Rosson, G. Rothermel, M. Shaw, and S. Wiedenbeck.
ACM Computing Surveys, Vol. 43, No. 3, 2011
Most programs today are written not by professional software developers, but
by people with expertise in other domains working towards goals for which they
need computational support. For example, a teacher might write a grading
spreadsheet to save time grading, or an interaction designer might use an
interface builder to test some user interface design ideas. Although these
end-user programmers may not have the same goals as professional developers,
they do face many of the same software engineering challenges, including
understanding their re- quirements, as well as making decisions about design,
reuse, integration, testing, and debugging. This article summarizes and
classifies research on these activities, defining the area of End-User
Software Engineering (EUSE) and related terminology. The article then
discusses empirical research about end-user software engi- neering activities
and the technologies designed to support them. The article also addresses
several crosscutting issues in the design of EUSE tools, including the roles
of risk, reward, and domain complexity, and self-efficacy in the design of
EUSE tools and the potential of educating users about software engineering
principles.
Program Fields for Continuous Software
Martin Erwig and Eric Walkingshaw.
ACM SIGSOFT Workshop on the Future of Software Engineering Research,
105-108, 2010
We propose program fields, a formal representation for
groups of related programs, as a new abstraction to support future software
engineering research in several areas. We will discuss opportunities offered by
program fields and research questions that have to be addressed.
Paper.pdf
Robust Learning for Adaptive Programs by Leveraging Program Structure
Jervis Pinto, Alan Fern, Tim Bauer, and Martin Erwig.
IEEE Int. Conf. on Machine Learning and Applications,
943-948, 2010
We study how to effectively integrate reinforcement learning
(RL) and programming languages via adaptation-based programming,
where programs can include non-deterministic structures that can
be automatically opti- mized via RL. Prior work has optimized
adaptive programs by defining an induced sequential decision
process to which standard RL is applied. Here we show that the
success of this approach is highly sensitive to the specific
program structure, where even seemingly minor program
transformations can lead to failure. This sensitivity makes it
extremely difficult for a non-RL-expert to write effective
adaptive programs. In this paper, we study a more robust learning
approach, where the key idea is to leverage information about
program structure in order to define a more informative decision
process and to improve the SARSA(lambda) RL algorithm. Our empirical
results show significant benefits for this approach.
Paper.pdf
A Language for Software Variation Research
Martin Erwig.
ACM SIGPLAN Conf. on Generative Programming and Component Engineering,
3-12, 2010
Managing variation is an important problem in software engineering that
takes different forms, ranging from version control and configuration
management to software product lines. In this paper, I present our recent
work on the choice
calculus, a fundamental representation for software variation that can serve
as a common language of discourse for variation research, filling a role
similar to lambda calculus in programming language research.
After motivating the design of the choice calculus and sketching its
semantics, I will discuss several potential application areas.
Paper.pdf
Reasoning about Spreadsheets with Labels and Dimensions
Chris Chambers and Martin Erwig.
Journal of Visual Languages and Computing, Vol. 21,
No. 5, 249-262, 2010
Labels in spreadsheets can be exploited for finding formula errors in two
principally different ways.
First, the spatial relationships between labels and other cells express
simple constraints on the cells usage in formulas.
Second, labels can be interpreted as units of measurements to provide semantic
information about the data being combined in formulas, which results in
different kinds of constraints.
In this paper we demonstrate how both approaches can be combined into an
integrated analysis, which is able to find significantly more errors in
spreadsheets than each of the individual approaches. In particular, the
integrated system is able to detect errors that cannot be found by either
of the individual approaches alone, which shows that the integrated system
provides an added value beyond the mere combination of its parts.
We also compare the effectiveness of this combined approach with
several other conceivable combinations of the involved components and identify
a system that seems most effective to find spreadsheet formula errors based on
label and unit-of-measurement information.
Paper.pdf
Causal Reasoning with Neuron Diagrams
Martin Erwig and Eric Walkingshaw.
IEEE Int. Symp. on Visual Languages and Human-Centric Computing
(VL/HCC'10),
101-108, 2010
The principle of causation is fundamental to science and society and has
remained an active topic of discourse in philosophy for over two millennia.
Modern philosophers often rely on "neuron diagrams", a domain-specific visual
language for discussing and reasoning about causal relationships and the
concept of causation itself. In this paper we formalize the syntax and
semantics of neuron diagrams. We discuss existing algorithms for identifying
causes in neuron diagrams, show how these approaches are flawed, and propose
solutions to these problems. We separate the standard representation of a
dynamic execution of a neuron diagram from its static definition and define two
separate, but related semantics, one for the causal effects of neuron diagrams
and one for the identification of causes themselves. Most significantly, we
propose a simple language extension that supports a clear, consistent, and
comprehensive algorithm for automatic causal inference.
Paper.pdf
SheetDiff: A Tool for Identifying Changes in Spreadsheets
Chris Chambers, Martin Erwig, and Markus Luckey
IEEE Int. Symp. on Visual Languages and Human-Centric Computing
(VL/HCC'10),
85-92, 2010
Most spreadsheets, like other software, change over time. A frequently
occurring scenario is the repeated reuse and adaptation of spreadsheets from
one project to another. If several versions of one spreadsheet for
grading/budgeting/etc. have accumulated, it is often not obvious which one to
choose for the next project. In situations like these, an understanding of how
two versions of a spreadsheet differ is crucial to make an
informed choice. Other scenarios are the reconciliation of two spreadsheets
created by different users, generalizing different spreadsheets into a common
template, or simply understanding and documenting the evolution of a
spreadsheet over time.
In this paper we present a method for identifying the changes between two
spreadsheets with the explicit goal of presenting them to users in a concise
form. We have implemented a prototype system, called SheetDiff, and tested
the approach on several different spreadsheet pairs. As our evaluations will
show, this system works reliably in practice. Moreover, we have compared
SheetDiff to similar systems that are commercially available. An important
difference is that while all these other tools distribute the change
representation over two spreadsheets, our system displays all changes in the
context of one spreadsheet, which results in a more compact representation.
Paper.pdf
Automatically Inferring ClassSheet Models from Spreadsheets
Jacome Cunha, Martin Erwig, and Joao Saraiva.
IEEE Int. Symp. on Visual Languages and Human-Centric Computing
(VL/HCC'10),
93-100, 2010
Most Influential Paper Award
Many errors in spreadsheet formulas can be avoided if spreadsheets are built
automatically from higher-level models that can encode and enforce consistency
constraints. However, designing such models is time consuming and requires
expertise beyond the knowledge to work with spreadsheets. Legacy spreadsheets
pose a particular challenge to the approach of controlling spreadsheet
evolution through higher-level models, because the need for a model might be
overshadowed by two problems: (A) The benefit of creating a spreadsheet is
lacking since the legacy spreadsheet already exists, and (B) existing data
must be transferred into the new model-generated spreadsheet.
To address these problems and to support the model-driven spreadsheet
engineering approach, we have developed a tool that can automatically infer
ClassSheet models from spreadsheets. To this end, we have adapted a method to
infer entity/relationship models from relational database to the
spreadsheets/ClassSheets realm. We have implemented our techniques in the
HaExcel framework and integrated it with the ViTSL/Gencel spreadsheet
generator, which allows the automatic generation of refactored spreadsheets
from the inferred ClassSheet model. The resulting spreadsheet guides further
changes and provably safeguards the spreadsheet against a large class of
formula errors. The developed tool is a significant contribution to
spreadsheet (reverse) engineering, because it fills an important gap and
allows a promising design method (ClassSheets) to be applied to a huge
collection of legacy spreadsheets with minimal effort.
Paper.pdf
Declarative Scripting in Haskell
Tim Bauer and Martin Erwig.
Int. Conf. on Software Language Engineering
(SLE'09),
LNCS 5969, 294-313, 2009
We present a domain-specific language embedded within the Haskell programming
language to build scripts in a declarative and type-safe manner. We can
categorize script components into various orthogonal dimensions, or
concerns, such as IO interaction, configuration, or error handling. In
particular, we provide special support for two dimensions that are often
neglected in scripting languages, namely creating deadlines for computations
and tagging and tracing of computations. Arbitrary computations may be
annotated with a textual tag explaining its purpose. Upon failure a detailed
context for that error is automatically produced. The deadline combinator
allows one to set a timeout on an operation. If it fails to complete within
that amount of time, the computation is aborted. Moreover, this combinator
works with the tag combinator so as to produce a contextual trace.
Paper.pdf
A Domain-Specific Language for Experimental Game Theory
Eric Walkingshaw and Martin Erwig.
Journal of Functional Programming Vol. 19,
No. 6, 645-661, 2009
Experimental game theory refers to the use of game theoretic models in
simulations and experiments to understand strategic behavior. It is an
increasingly important research tool in many fields, including economics,
biology and many social sciences, but computer support
for such projects is primarily found in custom programs written in general
purpose languages.
Here we present Hagl (short for "Haskell game language", and loosely
intended to evoke the homophone "haggle"), a domain-specific language
embedded in Haskell, intended to drastically reduce the development time of
such experiments, and make the definition and exploration of games and
strategies simple and fun.
Paper.pdf
Software Engineering for Spreadsheets
Martin Erwig.
IEEE Software Vol. 29,
No. 5, 25-30, 2009
Spreadsheets are popular end-user programming tools. Many people
use spreadsheet-computed values to make critical decisions, so
spreadsheets must be correct. Proven software engineering
principles can assist the construction and maintenance of
dependable spreadsheets. However, how can we make this practical
for end users? One way is to exploit spreadsheets' idiosyncratic
structure to translate software engineering concepts such as type
checking and debugging to an end-user programming domain. The
simplified computational model and the spatial embedding of
formulas, which provides rich contextual information, can
simplify these concepts, leading to effective tools for end
users.
Paper.pdf
Automatic Detection of Dimension Errors in Spreadsheets
Chris Chambers and Martin Erwig.
Journal of Visual Languages and Computing Vol. 20,
No. 4, 269-283, 2009
Spreadsheets are widely used, and studies have shown that most
end-user spreadsheets contain non-trivial errors. Most of the
currently available tools that try to mitigate this problem require
varying levels of user intervention. This paper presents a
system, called UCheck, that detects errors in spreadsheets
automatically. UCheck carries out automatic
header and unit inference, and reports unit errors to the
users. UCheck is based on two static analyses phases that infer
header and unit information for all cells in a spreadsheet.
We have tested UCheck on a wide variety of spreadsheets and found
that it works accurately and reliably. The system was also used in a
continuing education course for high school teachers, conducted
through Oregon State University, aimed at making the participants
aware of the need for quality control in the creation of spreadsheets.
Paper.pdf
Combining Spatial and Semantic Label Analysis
Chris Chambers and Martin Erwig.
IEEE Symp. on Visual Languages and Human-Centric Computing
(VL/HCC'09),
225-232, 2009
Labels in spreadsheets can be exploited for finding errors in
spreadsheet formulas. Previous approaches have either used the
positional information of labels or their interpretation as
dimension for checking the consistency of formulas.
In this paper we demonstrate how these two approaches can be combined. We have
formalized a combined reasoning system and have implemented a
corresponding prototype system. We have evaluated the system on
the EUSES spreadsheet corpus. The evaluation has demonstrated that
adding a syntactic, spatial analysis to a dimension inference can
significantly improve the rate of detected errors.
Paper.pdf
Visual Explanations of Probabilistic Reasoning
Martin Erwig and Eric Walkingshaw.
IEEE Symp. on Visual Languages and Human-Centric Computing
(VL/HCC'09),
23-27, 2009
Continuing our research in explanation-oriented language design, we present a
domain-specific visual language for explaining probabilistic reasoning.
Programs in this language, called explanation objects, can be manipulated
according to a set of laws to automatically generate many equivalent
explanation instances. We argue that this increases the
explanatory power of our language by allowing a user to view a problem from
many different perspectives.
Paper.pdf
Varying Domain Representations in Hagl -
Extending the Expressiveness of a DSL for Experimental Game Theory
Eric Walkingshaw and Martin Erwig.
IFIP Working Conference on Domain Specific Languages
(DSLWC'09),
LNCS 5658, 310-334, 2009
Experimental game theory is an increasingly important research tool in many
fields, providing insight into strategic behavior through simulation and
experimentation on game theoretic models. Unfortunately, despite relying
heavily on automation, this approach has not been well supported by tools.
Here we present our continuing work on Hagl, a domain-specific language
embedded in Haskell, intended to drastically reduce the development time of
such experiments and support a highly explorative research style.
In this paper we present a fundamental redesign of the underlying game
representation in Hagl. These changes allow us to better leverage domain
knowledge by allowing different classes of games to be represented differently,
exploiting existing domain representations and algorithms. In particular, we
show how this supports analytical extensions to Hagl, and makes strategies
for state-based games vastly simpler and more efficient.
Paper.pdf
A DSL for Explaining Probabilistic Reasoning
Martin Erwig and Eric Walkingshaw.
IFIP Working Conference on Domain Specific Languages
(DSLWC'09),
LNCS 5658, 335-359, 2009
Best Paper Award
We propose a new focus in language design where languages provide
constructs that not only describe the computation of results, but also
produce explanations of how and why those results were obtained. We
posit that if users are to understand computations produced by a
language, that language should provide explanations to the user.
As an example of such an explanation-oriented language we present a
domain-specific language for explaining probabilistic reasoning, a
domain that is not well understood by non-experts. We show the design
of the DSL in several steps. Based on a story-telling metaphor of
explanations, we identify generic constructs for building stories out
of events, and obtaining explanations by applying stories to specific
examples. These generic constructs are then adapted to the particular
explanation domain of probabilistic reasoning. Finally, we develop a
visual notation for explaining probabilistic reasoning.
Paper.pdf
A Formal Representation of Software-Hardware System Design
Eric Walkingshaw, Paul Strauss, Martin Erwig, Jonathan Mueller, Irem Tumer
ASME Int. Design Engineering Technical Conference &
Computers and Information in Engineering Conference
(IDETC'09),
2009
The design of hardware-software systems is a complex and
difficult task exacerbated by the very different tools used by
designers in each field. Even in small projects, tracking the impact,
motivation and context of individual design decisions between
designers and over time quickly becomes intractable. In an
attempt to bridge this gap, we present a general, low-level model
of the system design process. We formally define the concept of a
design decision, and provide a hierarchical representation of both
the design space and the context in which decisions are made.
This model can serve as a foundation for software-hardware
system design tools which will help designers cooperate more
efficiently and effectively. We provide a high-level example of the
use of such a system in a design problem provided through
collaboration with NASA.
Paper.pdf
Mutation Operators for Spreadsheets
Robin Abraham and Martin Erwig.
IEEE Transactions on Software Engineering,
Vol. 35, No. 1, 94-108, 2009
Based on (1) research into mutation testing for general purpose programming
languages, and (2) spreadsheet errors that have been reported in literature,
we have developed a suite of mutation operators for spreadsheets.
We present an evaluation of the mutation adequacy of du-adequate test suites
generated by a constraint-based automatic test-case generation system we have
developed in previous work. The results of the evaluation suggest additional
constraints that can be incorporated into the system to target mutation adequacy.
In addition to being useful in mutation testing of spreadsheets, the operators
can be used in the evaluation of error-detection tools and also for seeding
spreadsheets with errors for empirical studies. We describe two case studies
where the suite of mutation operators helped us carry out such empirical
evaluations.
The main contribution of this paper is the suite of mutation operators for
spreadsheets that can (1) help with systematic mutation testing of
spreadsheets, and (2) be used for carrying out empirical evaluations of
spreadsheet tools.
Paper.pdf
Spreadsheet Programming
Robin Abraham and Margaret M. Burnett and Martin Erwig.
Encyclopedia of Computer Science and Engineering,
(ed. B.J. Wah),
2804-2810, 2009
Spreadsheets are among the most widely used programming systems in
the world. Individuals and businesses use spreadsheets for a wide variety of
applications, ranging from performing simple calculations to building complex
financial models. In this article, we first discuss how spreadsheet programs
are actually functional programs. We then describe concepts in spreadsheet
programming, followed by a brief history of spreadsheet systems. Widespread
use of spreadsheets, coupled with their high error-proneness and the impact of
spreadsheet errors, has motivated research into techniques aimed at the
prevention, detection, and correction of errors in spreadsheets. We present an
overview of research effort that seeks to rectify this problem.
Paper.pdf
Test-Driven Goal-Directed Debugging in Spreadsheets
Robin Abraham and Martin Erwig.
IEEE Symp. on Visual Languages and Human-Centric Computing
(VL/HCC'08),
131-138, 2008
We present an error-detection and -correction approach for spreadsheets that
automatically generates questions about input/output pairs and, depending on
the feedback given by the user, proposes changes to the spreadsheet that would
correct detected errors. This approach combines and integrates previous work
on automatic test-case generation and goal-directed debugging. We have
implemented this method as an extension to MS Excel. We carried out an
evaluation of the system using spreadsheets seeded with faults using mutation
operators. The evaluation shows among other things that up to 93% of the
first-order mutants and 98% of the second-order mutants were detected by the
system using the automatically generated test cases.
Paper.pdf
Dimension Inference in Spreadsheets
Chris Chambers and Martin Erwig.
IEEE Symp. on Visual Languages and Human-Centric Computing
(VL/HCC'08),
123-130, 2008
Best Paper Award
We present a reasoning system for inferring dimension information in
spreadsheets. This system can be used to check the consistency of spreadsheet
formulas and can be employed to detect errors in spreadsheets.
We have prototypically implemented the system as an add-in to Excel. In an
evaluation of this implementation we were able to detect dimension errors in
almost 50% of the
investigated spreadsheets, which shows (i) that the system works reliably in
practice and (ii) that dimension information can be well exploited to uncover
errors in spreadsheets.
Paper.pdf
A Visual Language for Representing and Explaining Strategies in Game Theory
Martin Erwig and Eric Walkingshaw.
IEEE Symp. on Visual Languages and Human-Centric Computing
(VL/HCC'08),
101-108, 2008
We present a visual language for strategies in game theory,
which has potential applications in economics, social sciences, and in general
science education. This language facilitates explanations of strategies by
visually representing the interaction of players' strategies with game
execution. We have utilized the cognitive dimensions framework in the design
phase and recognized the need for a new cognitive dimension of "traceability"
that considers how well a language can represent the execution of a program.
We consider how traceability interacts with other cognitive dimensions and
demonstrate its use in analyzing existing languages. We conclude that the
design of a visual representation for execution traces should be an integral
part of the design of visual languages because understanding a program is
often tightly coupled to its execution.
Paper.pdf
The Inverse Ocean Modeling System. Part I: Implementation
Andrew F. Bennett, Boon S. Chua, Martin Erwig, Zhe Fu, Rich D. Loft, Julia C.
Muccino, and Ben Pflaum
Journal of Atmospheric and Oceanic Technology, Vol. 25,
Issue 9, 1608-1622, 2008
The Inverse Ocean Modeling (IOM) system constructs and runs
weak-constraint, four-dimensional variational data assimilation (W4DVAR) for
any dynamical model and any observing array. The dynamics and the observing
algorithms may be nonlinear but must be functionally smooth. The user need
only provide the model and the observing algorithms, together with an
interpolation scheme that relates the model numerics to the observer's
coordinates. All other model-dependent elements of the Inverse Ocean Modeling
assimilation algorithm, including adjoint
generators and Monte Carlo estimates of posteriors, have been derived and
coded as templates in Parametric FORTRAN. This language has
been developed for the IOM but has wider application in scientific
programming. Guided by the Parametric FORTRAN templates, and by model
information entered via a graphical user interface (GUI), the IOM generates
conventional FORTRAN code for each of the many algorithm elements, customized
to the user's model. The IOM also runs the various W4DVAR assimilations, which
are monitored by the GUI. The system is supported by a Web site that includes
interactive tutorials for the assimilation algorithm.
Paper.pdf
A Type System Based on End-User Vocabulary
Robin Abraham, Martin Erwig, and Scott Andrew.
IEEE Symp. on Visual Languages and Human-Centric Computing
(VL/HCC'07),
215-222, 2007
In previous work we have developed a system that automatically checks for unit
errors in spreadsheets. In this paper we describe our experiences using the
system in a workshop on spreadsheet safety aimed at high school teachers and
students. We present the results from a think-aloud study we conducted with
five high school teachers and one high school student as the subjects. The
study is the first ever to investigate the usability of a type system in
spreadsheets. We discovered that end users can effectively use the system to
debug a variety of errors in their spreadsheets. This result is encouraging
given that type systems are difficult even for programmers. The subjects had
difficulty debugging "non-local" unit errors. Guided by the results of the
study we devised new methods to improve the error-location inference. We also
extended the system to generate change suggestions for cells with unit errors,
which when applied, would correct unit errors. These extensions solved the
problem that the study revealed in the original system.
Paper.pdf
ClassSheets - Model-Based, Object-Oriented Design of Spreadsheet Applications
Jan-Christopher Bals, Fabian Christ, Gregor Engels, and Martin Erwig.
Journal of Object Technologies Vol. 6, No. 9, 2007
Using spreadsheets is the preferred method to calculate, display or store
anything that fits into a table-like structure. They are often used by end
users to create applications. But they have one critical drawback - they are
very error-prone. To reduce the error-proneness, we purpose a new way of
object-oriented modeling of spreadsheets prior to using them. These
spreadsheet models, termed ClassSheets, are used to generate concrete
spreadsheets on the instance level. By this approach sources of errors are
reduced and spreadsheet applications are easier to understand.
Paper.pdf
Exploiting Domain-Specific Structures For End-User Programming Support
Tools
Robin Abraham and Martin Erwig.
End-User Software Engineering (eds. Burnett, Engels, Myers, and
Rothermel), 2007
In previous work we have tried to transfer ideas that have been successful in
general-purpose programming languages and mainstream software engineering into
the realm of spreadsheets, which is one important example of an end-user
programming environment.
More specifically, we have addressed the questions of how to employ the
concepts of type checking, program generation and maintenance, and testing in
spreadsheets. While the primary objective of our work has been to offer
improvements for end-user productivity, we have tried to follow two
particular principles to guide our research.
- Keep the number of new concepts to be learned by end users at a minimum.
- Exploit as much as possible information offered by the internal
structure of spreadsheets.
In this paper we will illustrate our research approach with several examples.
Paper.pdf
An Update Calculus for Expressing Type-Safe Program Updates
Martin Erwig and Deling Ren.
Science of Computer Programming Vol. 67,
No. 2-3, 199-222, 2007
The dominant share of software development costs is spent on software
maintenance, particularly the process of updating programs in response to
changing requirements. Currently, such program changes tend to be performed
using text editors, an unreliable method that often causes many errors. In
addition to syntax and type errors, logical errors can be easily introduced
since text editors cannot guarantee that changes are performed consistently
over the whole program. All these errors can cause a correct and
perfectly running program to become instantly unusable. It is not surprising
that this situation exists because the "text-editor method" reveals a low-level
view of programs that fails to reflect the structure of programs.
We address this problem by pursuing a programming-language-based approach to
program updates. To this end we discuss in this paper the design and
requirements of an update language for expressing update programs. We identify
as the essential part of any update language a \emph{scope update} that
performs coordinated update of the definition and all uses of a symbol.
As the underlying basis for update languages, we define an update calculus for
updating lambda-calculus programs. We develop a type system for the update
calculus that infers the possible type changes that can be caused by an update
program. We demonstrate that type-safe update programs that fulfill certain
structural constraints preserve the type-correctness of lambda terms.
The update calculus can serve as a basis for higher-level update languages,
such as for Haskell or Java.
Paper.pdf
Parametric Fortran: Program Generation in Scientific Computing
Martin Erwig and Zhe Fu and Ben Pflaum
Journal of Software Maintenance and Evolution Vol. 19,
No. 3, 155-182, 2007
Parametric Fortran is an extension of Fortran that supports defining Fortran
program templates by allowing the parameterization of arbitrary Fortran
constructs. A Fortran program template can be translated into a regular
Fortran program guided by values for the parameters. This paper describes the
design, implementation, and applications of Parametric Fortran. Parametric
Fortran is particularly useful in scientific computing. The applications
include defining generic functions, removing duplicated code, and automatic
differentiation. The described techniques have been successfully employed in
a project that implements a generic inverse ocean modeling system.
Paper.pdf
GoalDebug: A Spreadsheet Debugger for End Users
Robin Abraham and Martin Erwig.
29th ACM/IEEE Int. Conf. on Software Engineering
(ICSE'07),
251-260, 2007
We present a spreadsheet debugger targeted at end users.
Whenever the computed output of a cell is incorrect, the user can supply an
expected value for a cell, which is employed by the system to generate a list
of change suggestions for formulas that, when applied, would result in the
user-specified output. The change suggestions are ranked using a set of
heuristics.
In previous work, we had presented the system as a proof of concept. In this
paper, we describe a systematic evaluation of the effectiveness of inferred
change suggestions and the employed ranking heuristics.
Based on the results of the evaluation we have extended both, the change
inference process and the ranking of suggestions. An evaluation of the
improved system shows that change inference process and the ranking heuristics
have both been substantially improved and that the system performs
effectively.
Paper.pdf
UCheck: A Spreadsheet Unit Checker for End Users
Robin Abraham and Martin Erwig.
Journal of Visual Languages and Computing Vol. 18,
No. 1, 71-95, 2007
Spreadsheets are widely used, and studies have shown that most
end-user spreadsheets contain non-trivial errors. Most of the
currently available tools that try to mitigate this problem require
varying levels of user intervention. This paper presents a
system, called UCheck, that detects errors in spreadsheets
automatically. UCheck carries out automatic
header and unit inference, and reports unit errors to the
users. UCheck is based on two static analyses phases that infer
header and unit information for all cells in a spreadsheet.
We have tested UCheck on a wide variety of spreadsheets and found
that it works accurately and reliably. The system was also used in a
continuing education course for high school teachers, conducted
through Oregon State University, aimed at making the participants
aware of the need for quality control in the creation of spreadsheets.
Paper.pdf
A Generic Recursion Toolbox for Haskell
(Or: Scrap Your Boilerplate Systematically)
Deling Ren and Martin Erwig.
ACM SIGPLAN Haskell Workshop,
13-24, 2006
Haskell programmers who deal with complex data types often need to apply
functions to specific nodes deeply nested inside of terms. Typically,
implementations for those applications require so-called boilerplate code,
which recursively visits the nodes and carries the functions to the places
where they need to be applied. The scrap-your-boilerplate approach proposed by
Lämmel and Peyton Jones tries to solve this problem by defining a general
traversal design pattern that performs the traversal automatically so that the
programmers can focus on the code that performs the actual transformation.
In practice we often encounter applications that require variations of the
recursion schema and call for more sophisticated generic traversals. Defining
such traversals from scratch requires a profound understanding of the
underlying mechanism and is everything but trivial.
In this paper we analyze the problem domain of recursive traversal strategies,
by integrating and extending previous approaches. We then extend the
scrap-your-boilerplate approach by rich traversal strategies and by a
combination of transformations and accumulations, which leads to a
comprehensive recursive traversal library in a statically typed framework.
We define a two-layer library targeted at general programmers and programmers
with knowledge in traversal strategies. The high-level interface defines a
universal combinator that can be customized to different one-pass traversal
strategies with different coverage and different traversal order. The
lower-layer interface provides a set of primitives that can be used for
defining more sophisticated traversal strategies such as fixpoint
traversals. The interface is simple and succinct. Like the original
scrap-your-boilerplate approach, it makes use of rank-2 polymorphism and
functional dependencies, implemented in GHC.
Paper.pdf (196K)
AutoTest: A Tool for Automatic Test Case Generation in Spreadsheets
Robin Abraham and Martin Erwig.
IEEE Symp. on Visual Languages and Human-Centric Computing
(VL/HCC'06),
43-50, 2006
In this paper we present a system that helps users test their spreadsheets
using automatically generated test cases. The system generates the test cases
by backward propagation and solution of constraints on cell values. These
constraints are obtained from the formula of the cell that is being tested
when we try to execute all feasible du-paths within the formula.
AutoTest
generates test cases that execute all feasible du-pairs. If infeasible
du-associations are present in the spreadsheet, the system is capable of
detecting and reporting all of these to the user. We also present a
comparative evaluation of our approach against the "Help Me Test" mechanism in
Forms/3 and show that our approach is faster and produces test suites that
give better du-coverage.
Paper.pdf
Sharing Reasoning about Faults in Spreadsheets: An Empirical Study
Joey Lawrence, Robin Abraham, Margaret Burnett, and Martin Erwig.
IEEE Symp. on Visual Languages and Human-Centric Computing
(VL/HCC'06),
35-42, 2006
Although researchers have developed several ways to
reason about the location of faults in spreadsheets, no single
form of reasoning is without limitations. Multiple types
of errors can appear in spreadsheets, and various fault localization
techniques differ in the kinds of errors that they
are effective in locating. In this paper, we report empirical
results from an emerging system that attempts to improve
fault localization for end-user programmers by sharing the
results of the reasoning systems found in WYSIWYT and
UCheck.
By evaluating the visual feedback from each fault
localization system, we shed light on where these different
forms of reasoning and combinations of them complement
- and contradict - one another, and which heuristics can
be used to generate the best advice from a combination of
these systems.
Paper.pdf
Type Inference for Spreadsheets
Robin Abraham and Martin Erwig.
ACM Int. Symp. on Principles and Practice of Declarative Programming
(PPDP'06),
73-84, 2006
Spreadsheets are the most popular programming systems in use today. Since
spreadsheets are visual, first-order functional languages, research into the
foundations of spreadsheets is therefore a highly relevant topic for the
principles and, in particular, the practice, of declarative programming.
Since the error rate in spreadsheets is very high and since those errors have
significant impact, methods and tools that can help detect and remove errors
from spreadsheets are very much needed. Type systems have traditionally played
a strong role in detecting errors in programming languages, and it is
therefore reasonable to ask whether type systems could not be helpful in
improving the current situation of spreadsheet programming.
In this paper we introduce a type system and a type inference
algorithm for spreadsheets and demonstrate how this algorithm and the
underlying typing concept can identify programming errors in spreadsheets.
In addition, we also demonstrate how the type inference algorithm can be
employed to infer models, or specifications, for spreadsheets, which can be
used to prevent future errors in spreadsheets.
Paper.pdf
Inferring Templates from Spreadsheets
Robin Abraham and Martin Erwig.
28th ACM/IEEE Int. Conf. on Software Engineering
(ICSE'06),
182-191, 2006
We present a study investigating the performance of a system for automatically
inferring spreadsheet templates. These templates allow users to safely edit
spreadsheets, that is, certain kinds of errors such as range, reference, and
type errors can be provably prevented. Since the inference of templates is
inherently ambiguous, such a study is required to demonstrate the
effectiveness of any such automatic system. The study results show that the
system considered performs significantly better than subjects with
intermediate to expert level programming expertise. These results are
important because the translation of existing spreadsheets into a system based
on safety-guaranteeing templates cannot be performed without automatic
support. We carried out post-hoc analyses of the video recordings of the
subjects' interactions with the spreadsheets and found that expert-level
subjects spend less time and inspect fewer cells in the spreadsheet and
develop more accurate templates than less experienced subjects.
Paper.pdf
Toward Sharing Reasoning to Improve Fault Localization in Spreadsheets
Joey Lawrence, Robin Abraham, Margaret Burnett, and Martin Erwig.
2nd Workshop on End-User Software Engineering
(WEUSE'06),
35-42, 2006
Although researchers have developed several ways to reason about
the location of faults in spreadsheets, no single form of reasoning is
without limitations. Multiple types of errors can appear in spreadsheets,
and various fault localization techniques differ in the kinds
of errors that they are effective in locating. Because end users who
debug spreadsheets consistently follow the advice of fault localization
systems, it is important to ensure that fault localization
feedback corresponds as closely as possible to where the faults actually
appear.
In this paper, we describe an emerging system that attempts to improve
fault localization for end-user programmers by sharing the
results of the reasoning systems found in WYSIWYT and
UCheck. By understanding the strengths and weaknesses of
the reasoning found in each system, we expect to identify where
different forms of reasoning complement one another, when different
forms of reasoning contradict one another, and which heuristics
can be used to select the best advice from each system. By using
multiple forms of reasoning in conjunction with heuristics to choose
among recommendations from each system, we expect to produce
unified fault localization feedback whose combination is better than
the sum of the parts.
Paper.pdf
Gencel: A Program Generator for Correct Spreadsheets
Martin Erwig, Robin Abraham, Irene Cooperstein, and Steve Kollmansberger.
Journal of Functional Programming Vol. 16,
No. 3, 293-325, 2006
A huge discrepancy between theory and practice exists in one popular
application area of functional programming-spreadsheets. Although
spreadsheets are the most frequently used (functional) programs, they fall
short of the quality level that is expected of functional programs, which
is evidenced by the fact that existing spreadsheets contain many errors, some
of which have serious impacts.
We have developed a template specification language that allows the definition
of spreadsheet templates that describe possible spreadsheet evolutions. This
language is based on a table calculus that formally captures the process of
creating and modifying spreadsheets.
We have developed a type system for this calculus that can prevent
type, reference, and omission errors from occurring in spreadsheets.
On the basis of the table calculus we have developed Gencel, a system for
generating reliable spreadsheets. We have implemented a prototype version of
Gencel as an extension of Excel.
Paper.pdf
Visual Type Inference
Martin Erwig.
Journal of Visual Languages and Computing Vol. 17,
No. 2, 161-186, 2006
We describe a type-inference algorithm that is based on labeling nodes with
type information in a graph that represents type constraints. This algorithm
produces the same results as the famous algorithm of Milner, but is much
simpler to use, which is of importance especially for teaching type systems
and type inference.
The proposed algorithm employs a more concise notation and yields inferences
that are shorter than applications of the traditional algorithm.
Simplifications result, in particular, from three facts:
(1) We do not have to maintain an explicit type environment throughout the
algorithm because the type environment is represented implicitly through node
labels.
(2) The use of unification is simplified through label propagation along graph
edges.
(3) The typing decisions in our algorithm are dependency-driven (and not
syntax-directed), which reduces notational overhead and bookkeeping.
Paper.pdf
Modeling Genome Evolution with a DSEL for Probabilistic Programming
Martin Erwig and Steve Kollmansberger.
8th Int. Symp. on Practical Aspects of Declarative Languages
(PADL'06),
LNCS 3819, 134-149, 2006
Many scientific applications benefit from simulation.
However, programming languages used in simulation, such as C++ or Matlab,
approach problems from a deterministic procedural view, which seems to differ,
in general, from many scientists' mental representation. We apply a
domain-specific language for probabilistic programming to the biological field
of gene modeling, showing how the mental-model gap may be bridged. Our system
assisted biologists in developing a model for genome evolution by separating
the concerns of model and simulation and providing implicit probabilistic
non-determinism.
Paper.pdf
Generic Programming in Fortran
Martin Erwig, Zhe Fu and Ben Pflaum.
ACM SIGPLAN Workshop on Partial Evaluation and Program Manipulation
(PEPM'06),
130-193, 2006
Parametric Fortran is an extension of Fortran that supports the
construction of generic programs by allowing the parameterization of
arbitrary Fortran constructs. A parameterized Fortran program can be
translated into a regular Fortran program guided by values for the
parameters. This paper describes the extensions of Parametric Fortran
by two new language features, accessors and list parameters. These
features particularly address the code duplication problem, which is
a major problem in the context of scientific computing. The described
techniques have been successfully employed in a project that
implements a generic inverse ocean modeling system.
Paper.pdf
Probabilistic Functional Programming in Haskell
Martin Erwig and Steve Kollmansberger.
Journal of Functional Programming, Vol. 16, No. 1, 21-34, 2006
At the heart of functional programming rests the principle of referential
transparency, which in particular means that a function f applied
to a value x always yields one and the same value y=f(x).
This principle seems to be violated when contemplating the use of functions to
describe probabilistic events, such as rolling a die: It is not clear at all
what exactly the outcome will be, and neither is it guaranteed that the same
value will be produced repeatedly.
However, these two seemingly incompatible notions can be reconciled if
probabilistic values are encapsulated in a data type.
In this paper, we will demonstrate such an approach by describing a
probabilistic functional programming (PFP) library for Haskell. We will show
that the proposed approach not only facilitates probabilistic programming in
functional languages, but in particular can lead to very concise programs and
simulations. In particular, a major advantage of our system is that
simulations can be specified independently from their method of execution.
That is, we can either fully simulate or randomize any
simulation without altering the code which defines it.
Paper.pdf
Haskell Source Code
ClassSheets: Automatic Generation of Spreadsheet Applications
from Object-Oriented Specifications
Gregor Engels and Martin Erwig.
20th IEEE/ACM Int. Conf. on Automated Software Engineering
(ASE'05), 124-133, 2005
Spreadsheets are widely used in all kinds of business applications. Numerous
studies have shown that they contain many errors that sometimes have dramatic
impacts. One reason for this situation is the low-level, cell-oriented
development process of spreadsheets.
We improve this process by introducing and formalizing a higher-level
object-oriented model termed ClassSheet. While still following the tabular
look-and-feel of spreadsheets, ClassSheets allow the developer to express
explicitly business object structures within a spreadsheet, which is achieved
by integrating concepts from the UML (Unified Modeling Language). A stepwise
automatic transformation process generates a spreadsheet application that is
consistent with the ClassSheet model. Thus, by deploying the formal
underpinning of ClassSheets, a large variety of errors can be prevented that
occur in many existing spreadsheet applications today.
The presented ClassSheet approach links spreadsheet applications to the
object-oriented modeling world and advocates an automatic model-driven
development process for spreadsheet applications of high quality.
Paper.pdf
Goal-Directed Debugging of Spreadsheets
Robin Abraham and Martin Erwig.
IEEE Symp. on Visual Languages and Human-centric Computing
(VL/HCC'05),
37-44, 2005
We present a semi-automatic debugger for spreadsheet systems that is
specifically targeted at end-user programmers. Users can report
expected values for cells that yield incorrect results. The system
then generates change suggestions that could correct the error. Users
can interactively explore, apply, refine, or reject these change
suggestions. The computation of change suggestions is based on a
formal inference system that propagates expected values backwards
across formulas. The system is fully integrated into Microsoft Excel
and can be used to automatically detect and correct various kinds of
errors in spreadsheets. Test results show that the system works
accurately and reliably.
Paper.pdf
Visual Specifications of Correct Spreadsheets
Robin Abraham, Martin Erwig, Steve Kollmansberger, and Ethan Seifert.
IEEE Symp. on Visual Languages and Human-Centric Computing
(VL/HCC'05),
189-196, 2005
We introduce a visual specification language for spreadsheets that allows the
definition of spreadsheet templates. A spreadsheet generator can
automatically create Excel spreadsheets from these templates together with
customized update operations. It can be shown that spreadsheets created in
this way are free from a large class of errors, such as reference, omission,
and type errors.
We present a formal definition of the visual language for templates and
describe the process of generating spreadsheets from templates. In addition,
we present an editor for templates and analyze the editor using the Cognitive
Dimensions framework.
Paper.pdf
How to Communicate Unit Error Messages in Spreadsheets
Robin Abraham and Martin Erwig.
1st Workshop on End-User Software Engineering
(WEUSE'05),
52-56, 2005
In previous work we have designed and implemented an
automatic reasoning system for spreadsheets, called UCheck,
that infers unit information for cells in a spreadsheet.
Based on this unit information, UCheck can identify cells in
the spreadsheet that contain erroneous formulas. However,
the information about an erroneous cell is reported to the
user currently in a rather crude way by simply coloring the
cell, which does not tell anything about the nature of error
and thus offers no help to the user as to how to fix it.
In this paper we describe an extension of UCheck, called
UFix, which improves the error messages reported to the
spreadsheet user dramatically. The approach essentially
consists of three steps: First, we identify different
categories of spreadsheet errors from an end-user's
perspective. Second, we map units that indicate erroneous
formulas to these error categories. Finally, we create
customized error messages from the unit information and the
identified error category. In many cases, these error
messages also provide suggestions on how to fix the reported
errors.
Paper.pdf
Automatic Generation and Maintenance of Correct Spreadsheets
Martin Erwig, Robin Abraham, Irene Cooperstein, and Steve Kollmansberger.
27th ACM/IEEE Int. Conf. on Software Engineering
(ICSE'05), 136-145, 2005
Existing spreadsheet systems allow users to change cells arbitrarily, which
is a major source of spreadsheet errors. We propose a system that prevents
errors in spreadsheets by restricting spreadsheet updates to only those that
are logically and technically correct. The system is based on the concept of
table specifications that describe the principal structure of the initial
spreadsheet and all of its future versions. We have developed a program
generator that translates a table specification into an initial spreadsheet
together with customized update operations for changing cells and
inserting/deleting rows and columns for this particular specification.
We have designed a type system for table specifications that ensures the
following form of "spreadsheet maintenance safety": Update operations that
are generated from a type-correct table specification are proved to transform
the spreadsheet only according to the specification and to never produce any
omission, reference, or type errors.
Finally, we have developed a prototype as an extension to Excel, which has been
shown by a preliminary usability study to be well accepted by end users.
Paper.pdf
Software Reuse for Scientific Computing Through Program Generation
Martin Erwig and Zhe Fu.
ACM Transactions on Software Engineering and Methodology, Vol. 14,
No. 2, 168-198, 2005
We present a program-generation approach to address a software-reuse challenge
in the area of scientific computing. More specifically, we describe the design
of a program generator for the specification of subroutines that can be
generic in the dimensions of arrays, parameter lists, and called subroutines.
We describe the application of that approach to a real-world problem in
scientific computing, which requires the generic description of inverse ocean
modeling tools.
In addition to a compiler that can transform generic specifications into
efficient Fortran code for models, we have also developed a type system that
can identify possible errors already in the specifications. This type system
is important for the acceptance of the program generator among scientists
because it prevents a large class of errors in the generated code.
Paper.pdf
Header and Unit Inference for Spreadsheets Through Spatial Analyses
Robin Abraham and Martin Erwig.
IEEE Symp. on Visual Languages and Human-Centric Computing
(VL/HCC'04),
165-172, 2004
Best Paper Award
This paper describes the design and implementation of a unit and header
inference system for spreadsheets. The system is based on a formal model of
units that we have described in previous work. Since the unit inference
depends on information about headers in a spreadsheet, a realistic unit
inference system requires a method for automatically determining headers. The
present paper describes (1) several spatial-analysis algorithms for header
inference, (2) a framework that facilitates the integration
of different algorithms, and (3) the implementation of the system.
The combined header and unit inference system is fully integrated into
Microsoft Excel and can be used to automatically identify various kinds of
errors in spreadsheets. Test results show that the system works accurately and
reliably.
Paper.pdf
Monadification of Functional Programs
Martin Erwig and Deling Ren.
Science of Computer Programming, Vol. 52, No. 1-3, 101-129, 2004
The structure of monadic functional programs allows the integration of many
different features by just changing the definition of the monad and not the
rest of the program, which is a desirable feature from a software engineering
and software maintenance point of view.
We describe an algorithm for the automatic transformation of a group of
functions into such a monadic form. We identify two correctness criteria and
argue that the proposed transformation is at least correct in the sense that
transformed programs yield the same results as the original programs modulo
monad constructors.
The translation of a set of functions into monadic form is in most cases
only a first step toward an extension of a program by new features. The
extended behavior can be realized by choosing an appropriate monad type and
by inserting monadic actions into the functions that have been transformed
into monadic form. We demonstrate an approach to the integration of
monadic actions that is based on the idea of specifying context-dependent
rewritings.
Paper.pdf
Parametric Fortran
- A Program Generator for Customized Generic Fortran Extensions
Martin Erwig and Zhe Fu.
6th Int. Symp. on Practical Aspects of Declarative Languages
(PADL'04),
LNCS
3057, 209-223, 2004
We describe the design and implementation of a program generator that can
produce extensions of Fortran that are specialized to support the programming
of particular applications. Extensions are specified through parameter
structures that can be referred to in Fortran programs to specify the
dependency of program parts on these parameters. By providing parameter
values, a parameterized Fortran program can be translated into a regular
Fortran program.
We describe as a real-world application of this program generator the
implementation of a generic inverse ocean modeling tool. The program generator
is implemented in Haskell and makes use of sophisticated features, such as
multi-parameter type classes, existential types, and generic programming
extensions and thus represents the application of an advanced applicative
language to a real-world problem.
Paper.pdf
Escape from Zurg: An Exercise in Logic Programming
Martin Erwig.
Journal of Functional Programming, Vol. 14, No. 3, 253-261, 2004
In this article we will illustrate with an example that modern functional
programming languages like Haskell can be used effectively for programming
search problems, in contrast to the widespread belief that
Prolog is much better suited for tasks like these.
Paper.pdf
Haskell Source Code
Toward Spatiotemporal Patterns
Martin Erwig.
Spatio-Temporal Databases (eds. De Caluwe et al.), Springer,
29-54, 2004
Existing spatiotemporal data models and query languages offer only basic
support to query changes of data. In particular, although these systems often
allow the formulation of queries that ask for changes at particular time
points, they fall short of expressing queries for sequences of such changes.
In this chapter we propose the concept of spatiotemporal patterns as a
systematic and scalable concept to query developments of objects and their
relationships. Based on our previous work on spatiotemporal predicates, we
outline the design of spatiotemporal patterns as a query mechanism to
characterize complex object behaviors in space and time. We will not present a
fully-fledged design. Instead, we will focus on deriving constraints that will
allow spatiotemporal patterns to become well-designed composable abstractions
that can be smoothly integrated into spatiotemporal query languages.
Spatiotemporal patterns can be applied in many different areas of science, for
example, in geosciences, geophysics, meteorology, ecology, and environmental
studies. Since users in these areas typically do not have extended formal
computer training, it is often difficult for them to use advanced query
languages. A visual notation for spatiotemporal patterns can help solving this
problem. In particular, since spatial objects and their relationships have a
natural graphical representation, a visual notation can express relationships
in many cases implicitly where textual notations require the explicit
application of operations and predicates. Based on our work on the
visualization of spatiotemporal predicates, we will sketch the design of a
visual language to formulate spatiotemporal patterns.
Paper.pdf
Toward the Automatic Derivation of XML Transformations
Martin Erwig.
1st Int. Workshop on XML Schema and Data Management
(XSDM'03),
LNCS
2814, 342-354, 2003
Existing solutions to data and schema integration require user
interaction/input to generate a data transformation between two different
schemas. These approaches are not appropriate in situations where many data
transformations are needed or where data transformations have to be generated
frequently.
We describe an approach to an automatic XML-transformation generator that
is based on a theory of information-preserving and -approximating XML
operations. Our approach builds on a formal semantics for XML operations and
their associated DTD transformation and on an axiomatic theory of information
preservation and approximation. This combination enables the inference of
a sequence of XML transformations by a search algorithm based on the
operations' DTD transformations.
Paper.pdf
KeyQuery - A Front End for the Automatic Translation of Keywords
into Structured Queries
Martin Erwig and Jianglin He.
14th Int. Conf. on Database and Expert Systems Applications
(DEXA'03),
LNCS
2736, 494-503, 2003
We demonstrate an approach to transform keyword queries
automatically into queries that combine keywords appropriately by
boolean operations, such as and and or. Our approach
is based on an analysis of relationships between the keywords using a
taxonomy. The transformed queries will be sent to a search engine, and the
returned results will be presented to the user. We evaluate the effectiveness
of our approach by comparing the precision of the results returned for
the generated query with the precision of the result for the original
query. Our experiments indicate that our approach can improve the precision
of the results considerably.
Paper.pdf
Type-Safe Update Programming
Martin Erwig and Deling Ren.
12th European Symp. on Programming
(ESOP'03),
LNCS
2618, 269-283, 2003
Many software maintenance problems are caused by using text editors to change
programs. A more systematic and reliable way of performing program updates is
to express changes with an update language. In particular, updates should
preserve the syntax- and type-correctness of the transformed object programs.
We describe an update calculus that can be used to update lambda-calculus
programs. We develop a type system for the update language that infers the
possible type changes that can be caused by an update program. We demonstrate
that type-safe update programs that fulfill certain structural constraints
preserve the type-correctness of lambda terms.
Paper.pdf
Xing: A Visual XML Query Language
Martin Erwig.
Journal of Visual Languages and Computing, Vol. 14,
No. 1, 5-45, 2003
We present a visual language for querying and transforming XML data. The
language is based on a visual document metaphor and the notion of document
patterns and rules. It combines a dynamic form-based interface for defining
queries and transformation rules with powerful pattern matching capabilities
and offers thus a highly expressive visual language. The design of the visual
language is specifically targeted at end users.
Paper.pdf
Spatio-Temporal Models and Languages: An Approach Based on Data Types
Ralf H. Güting, Mike H. Böhlen, Martin Erwig, Christian S. Jensen,
Nikos A. Lorentzos, Enrico Nardelli, and Markus Schneider.
Chapter 4 of Spatio-Temporal Databases: The CHOROCHRONOS Approach
(eds. T. Sellis et al.), Springer Verlag, LNCS 2520, 97-146, 2003
We develop DBMS data models and query languages to deal with geometries
changing over time. In contrast to most of the earlier work on this subject,
these models and languages are capable of handling continuously changing
geometries, or moving objects. We focus on two basic abstractions called
moving point and moving region. A moving point can represent an entity for
which only the position in space is relevant. A moving region captures moving
as well as growing or shrinking regions. Examples for moving points are
people, polar bears, cars, trains, or air planes; examples for moving regions
are hurricanes, forest fires, or oil spills in the sea. The main line of
research presented in this chapter takes a data type oriented approach. The
idea is to view moving points and moving regions as three-dimensional
(2D-space + time) or higher-dimensional entities whose structure and behavior
is captured by modeling them as abstract data types. These data types can then
be integrated as attribute types into relational, object-oriented, or other
DBMS data models; they can be implemented as extension packages ("data
blades") for suitable extensible DBMSs.
A Visual Language for the Evolution of Spatial Relationships
and its Translation into a Spatio-Temporal Calculus
Martin Erwig and Markus Schneider.
Journal of Visual Languages and Computing, Vol. 14,
No. 2, 181-211, 2003
Queries about objects that change their spatial attributes over time become
particularly interesting when they ask for changes in the spatial
relationships between different objects. We propose a visual notation that
is able to describe scenarios of changing object relationships. The visual
language is based on the idea to analyze two-dimensional traces of moving
objects to infer a temporal development of their mutual spatial
relationships. We motivate the language design by successively simplifying
object traces to their intrinsic properties. The notation can be effectively
translated in to a calculus of spatio-temporal predicates that formally
characterizes the evolution of spatial relationships. We also outline a user
interface that supports specifications by menus and a drawing editor. The
visual notation can be used directly as a visual query interface to
spatio-temporal databases, or it can provide predicate specifications that
can be integrated into textual query languages leading to heterogeneous
languages.
Paper.pdf
A Rule-Based Language for Programming Software Updates
Martin Erwig and Deling Ren.
3rd ACM SIGPLAN Workshop on Rule-Based Programming
(RULE'02), 67-77, 2002
We describe the design of a rule-based language for expressing changes to
Haskell programs in a systematic and reliable way. The update language
essentially offers update commands for all constructs of the object language
(a subset of Haskell). The update language can be translated into a core
calculus consisting of a small set of basic updates and update combinators.
The key construct of the core calculus is a scope update mechanism that
allows (and enforces) update specifications for the definition of a symbol
together with all of its uses.
The type of an update program is given by the possible type changes it can
cause for an object programs. We have developed a type-change inference system
to automatically infer type changes for updates. Updates for which a type
change can be successfully inferred and that satisfy an additional structural
condition can be shown to preserve type correctness of object programs.
In this paper we define the Haskell Update Language HULA and give a
translation into the core update calculus. We illustrate HULA and its
translation into the core calculus by several examples.
Paper.pdf
Design of Spatio-Temporal Query Languages
Martin Erwig.
NSF/BDEI Workshop on Spatio-Temporal Data Models of Biogeophysical Fields for Ecological Forecasting,
2002
In contrast to the field view of spatial data that basically views
spatial data as a mapping from points into some features, the object
view clusters points by features and their values into spatial objects of type
point, line, or region, which can then be integrated as abstract data types
into a database system.
We can apply the ADT idea to model spatio-temporal data and to integrate such
ADTs into data models. The basic idea is very simple and starts from the
observation that anything that changes over time can be regarded as a function
that maps from time into the data of consideration.
The integration of spatio-temporal data types into data models supports the
definition of a query languages because the interaction between ADT operations
and general querying constructs is constrained to a few well-defined places,
so that we are immediately able to pose spatio-temporal queries in a
straightforward way.
Paper.pdf
STQL: A Spatio-Temporal Query Language
Martin Erwig and Markus Schneider.
Chapter 6 of
Mining Spatio-Temporal Information Systems,
(eds. R. Ladner, K. Shaw, and M. Abdelguerfi), Kluwer Academic Publishers,
105-126, 2002
Integrating spatio-temporal data as abstract data types into
already existing data models is a promising approach to creating
spatio-temporal query languages. Based on a formal foundation presented
elsewhere, we present the main aspects of an SQL-like, spatio-temporal query
language, called STQL. As one of its essential features, STQL allows to query
and to retrieve moving objects which describe continuous
evolutions of spatial objects over time. We consider spatio-temporal
operations that are particularly useful in formulating queries, such as the
temporal lifting of spatial operations, the projection into space and time,
selection, and aggregation. Another important class of queries is concerned
with developments, which are changes of spatial relationships over
time. Based on the notion of spatio-temporal predicates we provide a
framework in STQL that allows a user to build more and more complex predicates
starting with a small set of elementary ones. We also describe a visual
notation to express developments.
Paper.pdf
Visually Customizing Inference Rules About Apples and Orange
Margaret M. Burnett and Martin Erwig.
2nd IEEE Int. Symp. on Human Centric Computing Languages and Environments
(HCC'02),
140-148, 2002
We have been working on a unit system for end-user spreadsheets that is based
on the concrete notion of units instead of the abstract concept of types. In
previous work, we defined such a system formally. In this paper, we describe
a visual system to support the formal reasoning in two ways. First, it
supports communicating and explaining the unit inference process to users.
Second and more important, our approach allows users to change the system's
reasoning by adding and customizing the system's inference rules.
Paper.pdf
Adding Apples and Oranges
Martin Erwig and Margaret M. Burnett.
4th Int. Symp. on Practical Aspects of Declarative Languages
(PADL'02),
LNCS
2257, 173-191, 2002
We define a unit system for end-user spreadsheets that is based
on the concrete notion of units instead of the abstract concept of types.
Units are derived from header information given by spreadsheets.
The unit system contains concepts, such as dependent units, multiple units,
and unit generalization, that allow the classification of spreadsheet contents
on a more fine-grained level than types do. Also, because communication with
the end user happens only in terms of objects that are contained in the
spreadsheet, our system does not require end users to learn new abstract
concepts of type systems.
Paper.pdf
Spatio-Temporal Predicates
Martin Erwig and Markus Schneider.
IEEE Transactions on Knowledge and Data Engineering, Vol. 14,
No. 4, 881-901, 2002
This paper investigates temporal changes of topological
relationships and thereby integrates two important research areas: first,
two-dimensional topological relationships that have been investigated quite
intensively, and second, the change of spatial information over time.
We investigate spatio-temporal predicates, which describe developments of
well-known spatial topological relationships. A framework is developed in
which spatio-temporal predicates can be obtained by temporal aggregation of
elementary spatial predicates and sequential composition. We compare our
framework with two other possible approaches: one is based on the observation
that spatio-temporal objects correspond to three-dimensional spatial objects
for which existing topological predicates can be exploited. The other
approach is to consider possible transitions between spatial configurations.
These considerations help to identify a canonical set of spatio-temporal
predicates.
Paper.pdf
Programs are Abstract Data Types
Martin Erwig.
16th IEEE Int. Conf. on Automated Software Engineering
(ASE'01), 400-403, 2001
We propose to view programs as abstract data types and to perform program
changes by applying well-defined operations on programs. The ADT view of
programs goes beyond the approach of syntax-directed editors and proof-editors
since it is possible to combine basic update operations into larger update
programs that can be stored and reused. It is crucial for the design of update
operations and their composition to know which properties they can preserve
when they are applied to a program.
In this paper we argue in favor of the abstract data type view of programs,
and present a general framework in which different programming languages,
update languages, and properties can be studied.
Paper.pdf
Inductive Graphs and Functional Graph Algorithms
Martin Erwig.
Journal of Functional Programming, Vol. 11, No. 5, 467-492, 2001.
We propose a new style of writing graph algorithms in functional languages
which is based on an alternative view of graphs as inductively defined data
types. We show how this graph model can be implemented efficiently, and then
we demonstrate how graph algorithms can be succinctly given by recursive
function definitions based on the inductive graph view.
We also regard this as a contribution to the teaching of algorithm and data
structures in functional languages since we can use the functional-style
graph algorithms instead of the imperative algorithms that are dominant today.
Paper.pdf
Haskell Sources
Pattern Guards and Transformational Patterns
Martin Erwig and Simon Peyton Jones.
Electronic Notes in Theoretical Computer Science, Vol. 41,
No. 1, 12.1-12.27, 2001
We propose three extensions to patterns and pattern matching in
Haskell. The first, pattern guards, allows the guards of a
guarded equation to match patterns and bind variables, as well as to
test boolean condition. For this we introduce a natural
generalization of guard expressions to guard qualifiers.
A frequently-occurring special case is that a function should be applied to a
matched value, and the result of this is to be matched against another pattern.
For this we introduce a syntactic abbreviation, transformational
patterns, that is particularly useful
when dealing with views.
These proposals can be implemented with very modest syntactic and implementation
cost. They are upward compatible with Haskell; all existing programs will
continue to work.
We also offer a third, much more speculative proposal, which provides
the transformational-pattern construct with additional power to
explicitly catch pattern match failure.
We demonstrate the usefulness of the proposed extension by several examples,
in particular, we compare our proposal with views, and we also discuss the use
of the new patterns in combination with equational reasoning.
Paper.pdf
XML Queries and Transformations for End Users
Martin Erwig.
XML 2000, 259-269, 2000
We propose a form-based interface to expresses XML queries and transformations
by so-called "document patterns" that describe properties of the requested
information and optionally specify how the found results should be reformatted
or restructured. The interface is targeted at casual users who want a fast and
easy way to find information in XML data resources. By using dynamic forms an
intuitive and easy-to-use interface is obtained that can be used to solve a
wide spectrum of tasks, ranging from simple selections and projections to
advanced data restructuring tasks. The interface is especially suited for end
users since it can be used without having to learn a programming or query
language and without knowing anything about (query or XML) language syntax,
DTDs or schemas. Nevertheless, DTDs can be well exploited, in particular, on
the user interface level to support the semi-automatic construction of
queries.
Paper.pdf
A Visual Language for XML
Martin Erwig.
16th IEEE Symp. on Visual Languages
(VL 2000), 47-54, 2000
XML is becoming one of the most influential standards concerning data exchange
and Web-presentations. In this paper we present a visual language for querying
and transforming XML data. The language is based on a visual document metaphor
and the notion of document patterns. It combines an intuitive, dynamic
form-based interface for defining queries and transformation rules with
powerful pattern matching capabilities and offers thus a highly expressive yet
easy to use visual language.
Providing visual language support for XML not only helps end users, it is
also a big opportunity for the VL community to receive greater attention.
Paper.pdf
Random Access to Abstract Data Types
Martin Erwig.
8th Int. Conf. on Algebraic Methodology and Software Technology
(AMAST 2000),
LNCS
1816, 135-149, 2000
We show how to define recursion operators for random access data
types, that is, ADTs that offer random access to their elements, and how
algorithms on arrays and on graphs can be expressed by these operators.
The approach is essentially based on a representation of ADTs as
bialgebras that allows catamorphisms between ADTs to be defined by
composing one ADT's algebra with the other ADT's coalgebra. The
extension to indexed data types enables the development of specific
recursion schemes, which are, in particular, suited to express a large
class of graph algorithms.
Paper.pdf,
Long Version.pdf
Formalization of Advanced Map Operations
Martin Erwig and Markus Schneider.
9th Int. Symp. on Spatial Data Handling
(SDH 2000), 8a.3-8a.17, 2000
Maps are a fundamental metaphor in GIS. We introduce several new
operations on maps that go far beyond well-known operations like
overlay or reclassification. In particular, we identify and
generalize operations that are of practical interest for spatial
analysis and that can be useful in many GIS applications. We give a
precise definition of these operations based on a formal model of
spatial partitions. This provides a theoretical foundation for maps
which also serves as a specification for implementations.
Paper.pdf
Query-By-Trace: Visual Predicate Specification in Spatio-Temporal Databases
Martin Erwig and Markus Schneider.
5th IFIP Conf. on Visual Databases
(VDB 5), 2000
In this paper we propose a visual interface for the specification of
predicates to be used in queries on spatio-temporal databases. The approach is
based on a visual specification method for temporally changing spatial
situations. This extends existing concepts for visual spatial query languages,
which are only capable of querying static spatial situations. We outline a
preliminary user interface that supports the specification on an intuitive
and easily manageable level, and we describe the design of the underlying
visual language. The visual notation can be used directly as a visual query
interface to spatio-temporal databases, or it can provide predicate
specifications that can be integrated into textual query languages leading to
heterogeneous languages.
Paper.pdf
A Foundation for Representing and Querying Moving Objects
Ralf H. Güting, Mike H. Böhlen, Martin Erwig, Christian S. Jensen,
Nikos A. Lorentzos, Markus Schneider, and Michalis Vazirgiannis.
ACM Transactions on Database Systems, Vol. 25, No. 1, 1-42, 2000
Most Cited TODS Paper in Ten Years (1993-2004)
Spatio-temporal databases deal with geometries changing over time. The goal
of our work is to provide a DBMS data model and query language capable of
handling such time-dependent geometries, including those changing continuously
which describe moving objects. Two fundamental abstractions are moving point
and moving region, describing objects for which only the time-dependent
position, or position and extent, are of interest, respectively. We propose to
represent such time-dependent geometries as attribute data types with suitable
operations, that is, to provide an abstract data type extension to a DBMS data
model and query language.
This paper presents a design of such a system of abstract data types. It
turns out that besides the main types of interest, moving point and moving
region, a relatively large number of auxiliary data types is needed. For
example, one needs a line type to represent the projection of a moving point
into the plane, or a "moving real" to represent the time-dependent distance of
two moving points. It then becomes crucial to achieve (i) orthogonality in the
design of the type system, i.e., type constructors can be applied uniformly,
(ii) genericity and consistency of operations, i.e., operations range over as
many types as possible and behave consistently, and (iii) closure and
consistency between structure and operations of non-temporal and related
temporal types. Satisfying these goals leads to a simple and expressive system
of abstract data types that may be integrated into a query language to yield a
powerful language for querying spatio-temporal data, including moving objects.
The paper formally defines the types and operations, offers detailed insight
into the considerations that went into the design, and exemplifies the use of
the abstract data types using SQL. The paper offers a precise and conceptually
clean foundation for implementing a spatio-temporal DBMS extension.
Paper.pdf
The Graph Voronoi Diagram with Applications
Martin Erwig.
Networks, Vol 36, No. 3, 156-163, 2000
The Voronoi diagram is a famous structure of computational geometry.
We show that there is a straightforward equivalent in graph theory
which can be efficiently computed. In particular, we give two
algorithms for the computation of graph Voronoi diagrams, prove a
lower bound on the problem, and we identify cases where the algorithms
presented are optimal. The space requirement of a graph Voronoi
diagram is modest, since it needs no more space than the graph itself.
The investigation of graph Voronoi diagrams is motivated by many
applications and problems on networks that can be easily solved with
their help. This includes the computation of
nearest facilities, all nearest neighbors and closest pairs,
some kind of collision free moving, and anti-centers and closest
points.
Paper.pdf
Visual Graphs
Martin Erwig
15th IEEE Symp. on Visual Languages
(VL'99), 122-129, 1999
The formal treatment of visual languages is often based on
graph representations. Since the matter of discourse is
visual languages, it would be convenient if the formal
manipulations could be performed in a visual way. We
introduce visual graphs to support this goal. In a visual
graph some nodes are shown as geometric figures, and
some edges are represented by geometric relationships
between these figures. We investigate mappings between
visual and abstract graphs and show their application in
semantics definitions for visual languages and in formal
manipulations of visual programs.
Paper.pdf
Visual Specifications of Spatio-Temporal Developments
Martin Erwig and Markus Schneider
15th IEEE Symp. on Visual Languages
(VL'99), 187-188, 1999
We introduce a visual language for the specification of
temporally changing spatial situations. The main idea is
to represent spatio-temporal (ST) objects in a two-dimensional
way by their trace. The intersections of these traces with
other objects are interpreted and translated into sequences
of spatial and spatio-temporal predicates, called developments,
that can then be used, for example, to query spatio-temporal
databases.
Summary.pdf
The Honeycomb Model of Spatio-Temporal Partitions
Martin Erwig and Markus Schneider
Int. Workshop on Spatio-Temporal Database Management
(STDBM'99),
LNCS
1678, 39-59, 1999
We define a formal model of spatio-temporal partitions which can be
used to model temporally changing maps. We investigate new applications
and generalizations of operations that are well-known for static, spatial
maps. We then define a small set of operations on spatio-temporal
partitions that are powerful enough to express all these tasks and more.
Spatio-temporal partitions combine the general notion of temporal objects
and the powerful spatial partition abstraction into a new, highly expressive
spatio-temporal data modeling tool.
Paper.pdf
Developments in Spatio-Temporal Query Languages
Martin Erwig and Markus Schneider
IEEE Int. Workshop on Spatio-Temporal Data Models and Languages,
441-449, 1999
Integrating spatio-temporal data as abstract data types into already
existing data models is a promising approach to creating spatio-temporal
query languages. In this context, an important new class of queries
can be identified which is concerned with developments of spatial objects
over time, that is, queries ask especially for changes in spatial relationships.
Based on a definition of the notion of spatio-temporal predicate we provide
a framework which allows to build more and more complex predicates starting
with a small set of elementary ones. These predicates can be well
used to characterize developments. We show how these concepts can
be realized within the relational data model. In particular, we demonstrate
how SQL can be extended to enable the querying of developments.
Paper.pdf
Spatio-Temporal Data Types: An Approach to Modeling and Querying Moving
Objects in Databases
Martin Erwig, Ralf H. Güting, Markus Schneider, and Michalis Vazirgiannis.
GeoInformatica, Vol. 3, No. 3, 269-296, 1999
Spatio-temporal databases deal with geometries changing over time.
In general, geometries cannot only change in discrete steps, but continuously,
and we are talking about moving objects. If only the position in
space of an object is relevant, then moving point is a basic abstraction;
if also the extent is of interest, then the moving region abstraction
captures moving as well as growing or shrinking regions. We propose
a new line of research where moving points and moving regions are viewed
as three-dimensional (2D space + time) or higher-dimensional entities whose
structure and behavior is captured by modeling them as abstract data types.
Such types can be integrated as base (attribute) data types into relational,
object-oriented, or other DBMS data models; they can be implemented as
data blades, cartridges, etc. for extensible DBMSs. We expect
these spatio-temporal data types to play a similarly fundamental role for
spatio-temporal databases as spatial data types have played for spatial
databases. The paper explains the approach and discusses several
fundamental issues and questions related to it that need to be clarified
before delving into specific designs of spatio-temporal algebras.
Paper.pdf
Diets for Fat Sets
Martin Erwig.
Journal of Functional Programming, Vol. 8, No. 6, 627-632, 1998
In this paper we describe the discrete interval encoding tree
for storing subsets of types having a total order and a predecessor and
a successor function. We consider for simplicity only the case for integer
sets; the generalization is not difficult. The discrete interval encoding
tree is based on the observation that the set of integers
{ i| a<=i<=b}
can be perfectly represented by the closed interval [ a, b]. The
general idea is to represent a set by a binary search tree of integers
in which maximal adjacent subsets are each represented by an interval.
For instance, inserting the sequence of numbers [6, 9, 2, 13, 8, 14, 10,
7, 5] into a binary search tree, respectively, into an discrete interval
encoding tree results in the tree structures shown below:
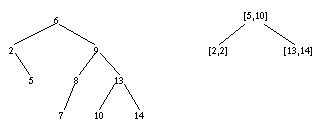 After defining operations for inserting, searching, and deleting elements,
we give a best-, worst- and average-case analysis. We also comment upon
some applications and compare actual running times.
After defining operations for inserting, searching, and deleting elements,
we give a best-, worst- and average-case analysis. We also comment upon
some applications and compare actual running times.
Paper.pdf
ML and Haskell Sources
Abstract Syntax and Semantics of Visual Languages
Martin Erwig.
Journal of Visual Languages and Computing, Vol. 9, No. 5, 461-483, 1998
The effective use of visual languages requires a precise understanding
of their meaning. Moreover, it is impossible to prove properties of visual
languages like soundness of transformation rules or correctness results
without having a formal language definition. Although this sounds obvious,
it is surprising that only little work has been done about the semantics
of visual languages, and even worse, there is no general framework available
for the semantics specification of different visual languages. We present
such a framework that is based on a rather general notion of abstract visual
syntax. This framework allows a logical as well as a denotational approach
to visual semantics, and it facilitates the formal reasoning about visual
languages and their properties. We illustrate the concepts of the proposed
approach by defining abstract syntax and semantics for the visual languages
VEX, Show and Tell, and Euler Circles. We demonstrate the semantics in
action by proving a rule for visual reasoning with Euler Circles and by
showing the correctness of a Show and Tell program.
Paper.pdf
Categorical Programming with Abstract Data Types
Martin Erwig.
7th Int. Conf. on Algebraic Methodology and Software Technology
(AMAST'98),
LNCS
1548, 406-421, 1998
We show how to define fold operators for abstract data types. The main
idea is to represent an ADT by a bialgebra, that is, an algebra/coalgebra
pair with a common carrier. A program operating on an ADT is given by a
mapping to another ADT. Such a mapping, called metamorphism, is
basically a composition of the algebra of the second with the coalgebra
of the first ADT. We investigate some properties of metamorphisms, and
we show that the metamorphic programming style offers far-reaching opportunities
for program optimization that cover and even extend those known for algebraic
data types.
Paper.pdf
Haskell Source Files and Related Papers
Temporal Objects for Spatio-Temporal Data Models and a Comparison of Their
Representations
Martin Erwig, Markus Schneider, and Ralf H. Güting
Int. Workshop on Advances in Database Technologies,
LNCS
1552, 454-465, 1998
Currently, there are strong efforts to integrate spatial and temporal
database technology into spatio-temporal database systems. This paper
views the topic from a rather fundamental perspective and makes several
contributions. First, it reviews existing temporal and spatial data models
and presents a completely new approach to temporal data modeling based
on the very general notion of temporal object. The definition of temporal
objects is centered around the observation that anything that changes over
time can be expressed as a function over time.� For the modeling of spatial
objects the well known concept of spatial data types is employed. As specific
subclasses, linear temporal and spatial objects are identified. Second,
the paper proposes the database embedding of temporal objects by means
of the abstract data type approach to the integration of complex objects
into databases. Furthermore, we make statements about the expressiveness
of different temporal and spatial database embeddings. Third, we consider
the combination of temporal and spatial objects into spatio-temporal objects
in (relational) databases.� We explain various alternatives for spatio-temporal
data models and databases and compare their expressiveness. Spatio-temporal
objects turn out to be specific instances of temporal objects.
Paper.pdf
Abstract and Discrete Modeling of Spatio-Temporal Data Types
Martin Erwig, Ralf H. Güting, Markus Schneider, and Michalis Vazirgiannis.
6th ACM Symp. on Geographic Information Systems
(ACMGIS'98),
131-136, 1998
Spatio-temporal databases deal with geometries changing over time. In
general, geometries cannot only change in discrete steps, but continuously,
and we are talking about moving objects. If only the position in space
of an object is relevant, then moving point is a basic abstraction; if
also the extent is of interest, then the moving region abstraction captures
moving as well as growing or shrinking regions. We propose a new line of
research where moving points and moving regions are viewed as three-dimensional
(2D space + time) or higher-dimensional entities whose structure and behavior
is captured by modeling them as abstract data types. Such types can be
integrated as base (attribute) data types into relational, object-oriented,
or other DBMS data models; they can be implemented as data blades, cartridges,
etc. for extensible DBMSs. We expect these spatio-temporal data types to
play a similarly fundamental role for spatio-temporal databases as spatial
data types have played for spatial databases. In this paper we consider
the need for modeling spatio-temporal data types on two different levels
of abstraction.
Paper.pdf
The Categorical Imperative - Or: How to Hide Your State Monads
Martin Erwig.
10th Int. Workshop on Implementation of Functional Languages
(IFL'98), 1-25, 1998
We demonstrate a systematic way of introducing state monads to improve
the efficiency of data structures. When programs are expressed as transformations
of abstract data types - which becomes possible by suitable definitions
of ADTs and ADT fold operations, we can observe restricted usage patterns
for ADTs, and this can be exploited to derive (i) partial data structures
correctly implementing the ADTs and (ii) imperative realizations of these
partial data structures. With a library of ADTs together with (some of)
their imperative implementations, efficient versions of functional programs
can be obtained without being concerned or even knowing about state monads.
As one example we demonstrate the optimization of a graph ADT resulting
in an optimal imperative implementation of depth-first search.
Paper.pdf
Haskell Source Files and Related Papers
Visual Semantics - Or: What You See is What You Compute
Martin Erwig.
14th IEEE Symp. on Visual Languages
(VL'98), 96-97, 1998
In this paper we introduce visual graphs as an intermediate representation
between concrete visual syntax and abstract graph syntax. In a visual graph
some nodes are shown as geometric figures, and some edges are represented
by geometric relationships between these figures. By carefully designing
visual graphs and corresponding mappings to abstract syntax graphs, semantics
definitions can, at least partially, employ a visual notation while still
being based on abstract syntax. Visual semantics thus offers the "best
of both worlds" by integrating abstract syntax and visual notation. We
also demonstrate that these concepts can be used to give visual semantics
for traditional textual formalisms. As an example we provide a visual definition
of Turing machines.
Summary.pdf
Partition and Conquer
Martin Erwig and Markus Schneider.
3rd Int. Conf. on Spatial Information Theory
(COSIT'97),
LNCS
1329, 389-408, 1997
Although maps and partitions are ubiquitous in geographical information
systems and spatial databases, there is only little work investigating
their foundations. We give a rigorous definition for spatial partitions
and propose partitions as a generic spatial data type that can be used
to model arbitrary maps and to support spatial analysis. We identify a
set of three powerful operations on partitions and show that the type of
partitions is closed under them. These basic operators are sufficient to
express all known application-specific operations. Moreover, many map operations
will be considerably generalized in our framework. We also indicate that
partitions can be effectively used as a meta-model to describe other spatial
data types.
Paper.pdf
Fully Persistent Graphs - Which One to Choose?
Martin Erwig.
9th Int. Workshop on Implementation of Functional Languages
(IFL'97),
LNCS
1467, 123-140, 1997
Functional programs, by nature, operate on functional, or persistent,
data structures. Therefore, persistent graphs are a prerequisite to express
functional graph algorithms. In this paper we describe two implementations
of persistent graphs and compare their running times on different graph
problems. Both implementations essentially represent graphs as adjacency
lists. The first structure uses the version tree implementation of functional
arrays to make adjacency lists persistent. An array cache of the newest
graph version together with a time stamping technique for speeding up deletions
makes it asymptotically optimal for a class of graph algorithms that use
graphs in a single-threaded way. The second approach uses balanced search
trees to implement adjacency lists. For both structures we also consider
several variations, e.g., ignoring edge labels or predecessor information.
Paper.pdf
Semantics of Visual Languages
Martin Erwig.
13th IEEE Symp. on Visual Languages
(VL'97), 304-311, 1997
The effective use of visual languages requires a precise understanding
of their meaning. Moreover, it is impossible to prove properties of visual
languages like soundness of transformation rules or correctness results
without having a formal language definition. Although this sounds obvious,
it is surprising that only little work has been done about the semantics
of visual languages, and even worse, there is no general framework available
for the semantics specification of different visual languages. We present
such a framework that is based on a rather general notion of abstract visual
syntax. This framework allows a logical as well as a denotational approach
to visual semantics, and it facilitates the formal reasoning about visual
languages and their properties. We illustrate the concepts of the proposed
approach by defining abstract syntax and semantics for the visual languages
VEX, Show and Tell, and Euler Circles. For the latter we also prove a rule
for visual reasoning.
Paper.pdf
Abstract Visual Syntax
Martin Erwig.
2nd IEEE Int. Workshop on Theory of Visual Languages
(TVL'97), 15-25, 1997
We propose a separation of visual syntax into concrete and abstract
syntax, much like it is often done for textual languages. Here the focus
is on visual programming languages; the impact on visual languages in general
is not clear by now. We suggest to use unstructured labeled multi-graphs
as abstract visual syntax and show how this facilitates semantics definitions
and transformations of visual languages. In particular, disregarding structural
constraints on the abstract syntax level makes such manipulations simple
and powerful. Moreover, we demonstrate that - in contrast to the traditional
monolithic graph definition - an inductive view of graphs provides a very
convenient way to move in a structured (and declarative) way through graphs.
Again this supports the simplicity of descriptions for transformations
and semantics.
Paper.pdf
Vague Regions
Martin Erwig and Markus Schneider.
5th Int. Symp. on Advances in Spatial Databases
(SSD'97),
LNCS
1262, 298-320, 1997
In many geographical applications there is a need to model spatial phenomena
not simply by sharp objects, but rather through indeterminate or vague
concepts. To support such applications we present a model of vague regions
which covers and extends previous approaches. The formal framework is based
on a general exact model of spatial data types. On the one hand, this simplifies
the definition of the vague model since we can build upon already existing
theory of spatial data types, on the other hand, this approach facilitates
the migration from exact to vague models. Moreover, exact spatial data
types are subsumed as a special case of the presented vague concepts. We
present examples and show how they are represented within our framework.
We give a formal definition of basic operations and predicates which particularly
allow a more fine-grained investigation of spatial situations than in the
pure exact case. We also demonstrate the integration of the presented concepts
into an SQL-like query language.
Paper.pdf
Functional Programming with Graphs
Martin Erwig.
2nd ACM SIGPLAN Int. Conf. on Functional Programming
(ICFP'97),
52-65, 1997
(also in: ACM SIGPLAN Notices, Vol. 32,No. 8, Aug
1997, pp. 52-65)
Graph algorithms expressed in functional languages often suffer from
their inherited imperative, state-based style. In particular, this impedes
formal program manipulation. We show how to model persistent graphs in
functional languages by graph constructors. This provides a decompositional
view of graphs which is very close to that of data types and leads to a
``more functional'' formulation of graph algorithms. Graph constructors
enable the definition of general fold operations for graphs. We present
a promotion theorem for one of these folds that allows program fusion and
the elimination of intermediate results. Fusion is not restricted to the
elimination of tree-like structures, and we prove another theorem that
facilitates the elimination of intermediate graphs. We describe an ML-implementation
of persistent graphs which efficiently supports the presented fold operators.
For example, depth-first-search expressed by a fold over a functional graph
has the same complexity as the corresponding imperative algorithm.
Paper.pdf
ML-Source.tar.gz, for an improved
implementation, have a look at the
Functional Graph Library
Active Patterns
Martin Erwig.
8th Int. Workshop on Implementation of Functional Languages
(IFL'96),
LNCS
1268, 21-40, 1996
Active patterns apply preprocessing functions to data type values before
they are matched. This is of use for unfree data types where more than
one representation exists for an abstract value: In many cases there is
a specific representation for which function definitions become very simple,
and active patterns just allow to assume this specific representation in
function definitions. We define the semantics of active patterns and describe
their implementation.
Paper.pdf
Heterogeneous Visual Languages - Integrating Visual and Textual Programming
Martin Erwig and Bernd Meyer. 11th IEEE Symp. on Visual Languages
(VL'95),
318-325, 1995
After more than a decade of research, visual languages have still not
become everyday programming tools. On a short term, an integration of visual
languages with well-established (textual) programming languages may be
more likely to meet the actual requirements of practical software development
than the highly ambitious goal of creating purely visual languages. In
such an integration each paradigm can support the other where it is superior.
Particularly attractive is the use of visual expressions for the description
of domain-specific data structures in combination with textual notations
for abstract control structures. In addition to a basic framework for heterogeneous
languages, we outline the design of a development system that allows rapid
prototyping of implementations of heterogeneous languages. Examples will
be presented from the domains of logical, functional, and procedural languages.
Paper.pdf
Encoding Shortest Paths in Spatial Networks
Martin Erwig.
Networks, Vol. 26,291-303, 1995
A new data structure is presented which facilitates the search for shortest
paths in spatially embedded planar networks in a worst-case time of O(l
log r) where l is the number of edges in the shortest path
to be found and r is an upper bound on the number of so-called ``cross
edges'' (these are edges connecting, for any node v, different shortest
path subtrees rooted at v's successors). The data structure is based
on the idea to identify shortest path subtrees with the regions in the
plane they cover. In the worst-case the space requirement is O(rn),
which, in general, is O(n^2), but for regularly shaped networks
it is expected to be only O(n\sqrt(n)). A decomposition of
graphs into bi-connected components can be used to reduce the sizes of
the trees to be encoded and to reduce the complexity of the regions for
these trees. The decomposition also simplifies the algorithm for computing
encoding regions, which is based on minimum link paths in polygons. Approximations
for region boundaries can effectively be utilized to speed up the process
of shortest path reconstruction: For a realistically constrained class
of networks, i.e., networks in which the ratio of the shortest path distance
between any two points to the Euclidean distance between these points is
bounded by a constant, it is shown that an average searching time of O(l)
can be achieved.
DEAL - A Language for Depicting Algorithms
Martin Erwig. 10th IEEE Symp. on Visual Languages (VL'94),184-185,
1994
Algorithms can be regarded as instructions for building and/or changing
data structures. In order to describe algorithms visually we need (i) a
visual representation of data structures, and (ii) a (visual) representation
of modifications.
An instructive way for explaining
algorithms found in many data structure textbooks is to describe changes
in data structures by drawing a picture showing the situation before the
change and a picture denoting the modified structure. We believe that following
this tradition is a good policy for developing a visual algorithmic language.
Thus, we will utilize data type icons to denote objects of a certain type,
and we will use action rules for describing changes in pictures and the
denoted data structures.
Since typical operations often
work on subparts of a larger data structure (e.g., add a node to a tree
or exchange two elements of an array) it is convenient to be able to denote
parts of data structures. In the presented language this is achieved by
attaching labels to data type icons at specific positions. Some label positions
denote unique parts of the data type whereas other locations mean collections
of subobjects. The latter case is exploited to implicitly describe iterations
over objects in complex data structures. Let us convey a concrete impression
by an example. The action rule that is shown in the following Figure introduces
bindings for variables denoting parts of an array A on the left
side and describes changes to be performed on A by relocating labels
on the right side (exchange y and z).
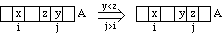
The variables i and j below the array denote indices which
are interpreted by (nested) loops over A: Here, by default, the
first loop for i ranges from 1 to n, and the inner loop for
j
runs from n down to i. The lower bound of this loop is given
by the condition under the arrow, j> i, which also specifies
the direction of the loop (> means descending). The condition above the
arrow restricts the action described by the right side: The array elements
y
and z are only exchanged if y< z. Since the label
z
is located directly adjacent to y both labels are interpreted as
adjacent array elements.
Pattern matching is a very powerful
feature used by many modern functional languages, such as ML or Haskell,
to define functions on structured data. We will use icon patterns, showing
the composition of complex data structures, for distinguishing arguments
for different cases of action rules and building new structures. Specifically,
in building new array structures the concept of array comprehensions is
extremely useful. An array comprehension is an expression [x \in
A
| P(x)] denoting a new array B consisting of all elements
of A for which condition P is true. The order of the elements
of B is the same as in A. One or more array comprehensions
are displayed by an array icon with one or more variables inside (i.e.,
not denoting the first or last element in the array) for which the conditions
are given above the arrow symbol. Consider, e.g., the recursive function
definition of Quicksort:
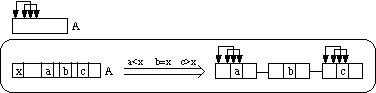
The icon above the box describes how to apply the defined function.
The action rule inside the box initially binds x to A[1]
(since the label x is located at the beginning of the array icon)
and describes three array comprehensions: [a \in A | a<
x],
[b \in A | b=x], and [c \in
A
| c> x]. The pattern on the the right side appends the three
new arrays defined by the array comprehensions where the quicksort function
is recursively applied to the first and to the third one.
In this paper, we compare our visual
language with other approaches, and we provide a formal definition together
with describing the translation into a textual algorithmic language.
Explicit Graphs in a Functional Model for Spatial Databases
Martin Erwig and Ralf H. Güting.
IEEE Transactions on Knowledge and Data Engineering, Vol. 5,No. 6, 787-804, 1994
Observing that networks are ubiquitous in applications for spatial databases,
we define a new data model and query language that especially supports
graph structures. This model integrates concepts of functional data modeling
with order-sorted algebra. Besides object and data type hierarchies graphs
are available as an explicit modeling tool, and graph operations are part
of the query language. Graphs have three classes of components, namely
nodes, edges, and explicit paths. These are at the same time object types
within the object type hierarchy and can be used like any other type. Explicit
paths are useful because ``real world'' objects often correspond to paths
in a network. Furthermore, a dynamic generalization concept is introduced
to handle heterogeneous collections of objects in a query. In connection
with spatial data types this leads to powerful modeling and querying capabilities
for spatial databases, in particular for spatially embedded networks such
as highways, rivers, public transport, and so forth. We use multi-level
order-sorted algebra as a formal framework for the specification of our
model. Roughly spoken, the first level algebra defines types and operations
of the query language whereas the second level algebra defines kinds (collections
of types) and type constructors as functions between kinds and so provides
the types that can be used at the first level.
Paper.pdf,
Long Version (Report).pdf
Graphs in Spatial Databases
Martin Erwig. Doctoral Thesis, FernUniversität Hagen, 1994
This thesis investigates the integration of graph structures into spatial
databases. We consider three different perspectives:
First and foremost, we define a
functional data model extended by spatial datatypes to which graphs are
added by means of special type constructors. Graphs are defined as an orthogonal,
``first-class'', concept of the model which enables the clear modeling
of applications and the direct formulation of graph queries. The latter
is achieved by presenting the functional model within an algebraic setting
where graph operations are directly available as functions. In order to
give a precise account for extending algebras by polymorphic type constructors
we introduce the formalism of multi-level algebra which allows the description
of type systems as well as languages within one formal framework. Multi-level
algebra is capable of expressing very subtle details of type systems, such
as preventing type constructors from being nested or describing operations
with a variable number of arguments. These features are needed by the functional
model which is entirely specified by the multi-level algebra formalism.
Second, realizing that all interesting
computations on graph structures cannot be captured by a small set of operators
--- at least not in an efficient way --- we develop a programming language
for the specification of graph algorithms. This is done by formulating
a powerful exploration paradigm which regards a large class of graph algorithms
as iterations over graph elements. The exact behavior of explorations is
primarily determined by special data structures which are supplied as arguments
to exploration operators. This graph language is defined and implemented
as an extension of ML. The integration with ML allows an even larger class
of graph problems to be addressed. The design of the language is chosen
on the one hand to provide very succinct and clear descriptions of graph
algorithms and on the other hand to retain an efficient implementation.
The second aspect is achieved by introducing recursive array definitions
which are the formal backbone of the computations performed during explorations.
Recursive arrays are a new means for introducing mutable state in an efficient
and at the same time declarative way into functional languages.
Finally, we propose data structures
and algorithms supporting the efficient realization of some very important
graph operations. The first is a geometric index for encoding shortest
paths. The idea is to represent shortest path (sub-) trees by the regions
they cover in the plane. Point location in these regions is then used to
reconstruct shortest paths. Concerning space and time complexity the proposed
structure outperforms previous proposals in some practically relevant classes
of graphs. The second structure is the graph Voronoi diagram which is a
partition of the nodes in a graph according to shortest paths to a set
of reference nodes. We give efficient algorithms for the construction of
graph Voronoi diagrams and show their use by presenting numerous example
queries which are perfectly supported by this structure.
Specifying Type Systems with Multi-Level Order-Sorted Algebra
Martin Erwig.
3rd Int. Conf. on Algebraic Methodology and Software Technology (AMAST'93),177-184, 1993
We propose to use order-sorted algebras (OSA) on multiple levels to
describe languages together with their type systems. It is demonstrated
that even advanced aspects can be modeled, including, parametric polymorphism,
complex relationships between different sorts of an operation's rank, the
specification of a variable number of parameters for operations, and type
constructors using values (and not only types) as arguments.
The basic idea is to use a signature
to describe a type system where sorts denote sets of type names and operations
denote type constructors. The values of an algebra for such a signature
are then used as sorts of another signature now describing a language having
the previously defined type system. This way of modeling is not restricted
to two levels, and we will show useful applications of three-level algebras.
Paper.pdf
Graph Algorithms = Iteration + Data Structures? The Structure of Graph
Algorithms and a Corresponding Style of Programming
Martin Erwig. 18th Int. Workshop on Graph Theoretic Concepts in Computer
Science (WG'92),
LNCS
657, 277-292, 1992
We encourage a specific view of graph algorithms, which can be paraphrased
by "iterate over the graph elements in a specific order and perform computations
in each step". Data structures will be used to define the processing order,
and we will introduce recursive mapping/array definitions as a vehicle
for specifying the desired computations. Being concerned with the problem
of implementing graph algorithms, we outline the extension of a functional
programming language by graph types and operations. In particular, we explicate
an exploration operator that essentially embodies the proposed view of
algorithms. Fortunately, the resulting specifications of algorithms, in
addition to being compact and declarative, are expected to have an almost
as efficient implementation as their imperative counterparts.
Paper.pdf
A Functional DBPL Revealing High Level Optimizations
Martin Erwig and Udo W. Lipeck.
3rd Int. Workshop on Database Programming Languages (DBPL3),306-321, 1991
We present a functional DBPL in the style of FP that facilitates the
definition of precise semantics and opens up opportunities for far-reaching
optimizations. The language is integrated into a functional data model,
which is extended by arbitrary type hierarchies and complex objects. Thus
we are able to provide the clarity of FP-like programs together with the
full power of semantic data modeling. To give an impression of the special
facilities for optimizing functional database languages, we point out some
laws not presented before which enable access path selection already on
the algebraic level of optimization. The algebraic way of access path optimization
also gives new insights into optimization strategies.
Paper.pdf